STL源码分析
1. STL概论与版本简介
首先是STL的六大基础组件:
- 容器.简而言之就是各种数据结构:vector,deque,set,map等.实现上是一种
class template. - 算法,sort,search,copy,erase等.实现上是
function template. - 迭代器,算法和容器等粘合剂,是一种“范型指针”.
- 仿函数,可以看做是算法的某种策略.可看作重载了
operator()的class template. - 配接器,一种用来修饰容器,仿函数,或者迭代器接口的东西.
- 分配器,负责空间的管理和配置.
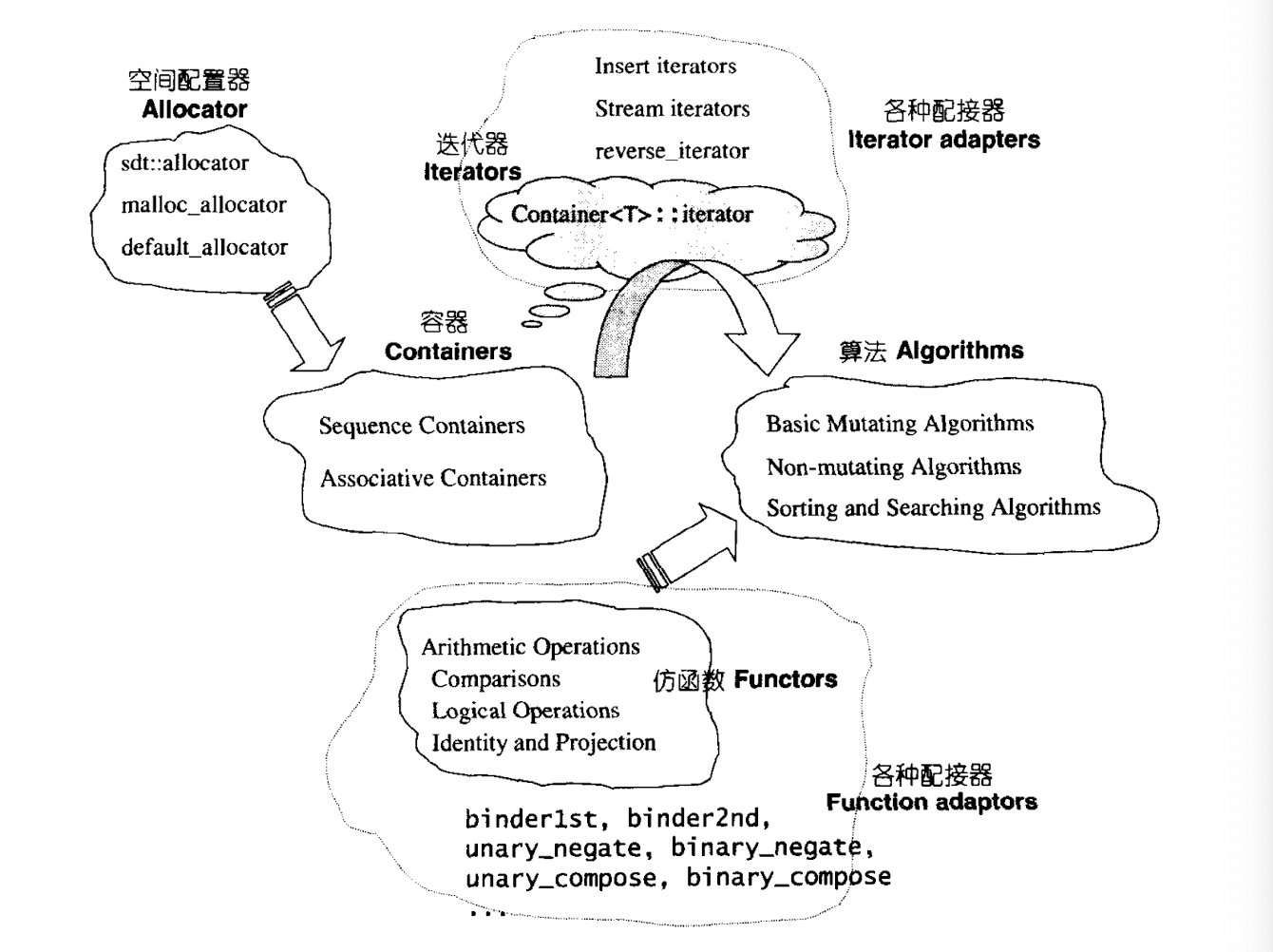
简而言之,算法对于容器的操作借助迭代器实现,仿函数影响算法实现的策略,空间分配器是为容器管理内存的.
其中GCC所采用的是
SGI STL,也是后来我们重点学习的版本.
2.Allocator
allocator是容器实现的基础,但是allocator不一定是分配内存,也可以分配磁盘.
分配器很多时候是一个
template class,其中有一些主要的接口,这些接口主要有:allocator,deallocator,constructor,destroy等.
可以说是实现STL的过程中的第一步,因为要考虑为容器中的数据分配空间的问题.
1)最简易的allocator实现.
下面是一个简单的实现,我们来对其源代码进行分析.
在一个简易的STL实现中,分配器文件的代码主要有两个部分:一个是模版类allocator,另一个是实现的模版函数(下面代码段中所示).而
allocator中主要是将这些接口进行封装.而这些函数,最主要的是
allocator,deallocator,constructor,destroy等,分别是对
new,delete,构造函数,析构函数进行的封装.
template <class T>
inline T* _allocate(ptrdiff_t size, T*) {
set_new_handler(0);
T *tmp = (T *)(::operator new((size_t)(size * sizeof(T))));//分配内存空间
if (tmp == 0) {
cerr << "out of memory" << endl;
exit(1);
}
return tmp;//将该指针返回
}
template <class T>
inline void _deallocate(T* buffer) {
::operator delete(buffer);//释放buffer指向的内存空间
}
template <class T1, class T2>
inline void _construct(T1* p, const T2& value) {
new (p) T1(value);//用value去拷贝构造一个新对象,返回到p指针中.
}
template <class T>
inline void _destroy(T* ptr) {
ptr->~T();//调用析构函数.
}所以总体来看这些接口并不复杂,只是做了一层很薄的封装而已.这四个接口分别代表分配,释放,析构,构造.前两者只涉及到内存空间的分配,后两者则在已有的内存上进行对象的操作.
下面是allocator的简易实现.可见,除了简单的调用了前面实现的函数接口.
template <class T>
class allocator {
public:
typedef T value_type;typedef T * pointer;
typedef const T * const_pointer;typedef T & reference;
typedef const T & const_reference;typedef size_t size_type;
typedef ptrdiff_t difference_type;
// rebind allocator of type U
template <class U>
struct rebind {
typedef allocator<U> other;
};
// hint used for locality. ref. [Austern], p189
pointer allocate(size_type n, const void* hint=0) {
return _allocate((difference_type)n, (pointer)0);
}
void deallocate(pointer p, size_type n) {
_deallocate(p);
}
//.......其他接口的实现也是类似的,不过在此省略........
const_pointer const_address(const_reference x) {
return (const_pointer)&x;
}
size_type max_size() const {
return size_type(UINT_MAX / sizeof(T));
}
};当创建一个新的对象时,分配器发生什么?
首先调用allocate申请内存空间,并返回指针,然后调用construct将对象构建在已经分配好的内存中.
如果析构的话,首先会调用destroy执行此对象的析构函数,最后再调用dallocator将已经分配的内存释放.
2) SGI STL中allocator的实现
其中分别介绍 alocator和alloc
allocator只是多了层很薄的封装,实现的效率不高,也不是
SGI STL中所使用的主流.而后者则是
SGI STL中效率比较高,使用的主流,很多容器默认采用的分配器就是这个.但是它的实现相对比较复杂.
我们首先回顾一下,C++中 new和delete的过程:
new一个对象时,先调用分配内存在调用构造函数.delete一个对象,先析构函数在释放内存.
这两个动作都是两阶段的.
在 STL allocator的实现中,将两个阶段分离.分为
allocator,deallocator,constructor,destroy.因而在
<memory>中,分别包含
<stl_alloc.h>和 <stl_construct.h>
.
construct和destroy的实现
#if __cplusplus >= 201103L
template<typename _T1, typename... _Args>
inline void
_Construct(_T1* __p, _Args&&... __args)
{ ::new(static_cast<void*>(__p)) _T1(std::forward<_Args>(__args)...); }
#else
template<typename _T1, typename _T2>
inline void
_Construct(_T1* __p, const _T2& __value)
{
::new(static_cast<void*>(__p)) _T1(__value);
}
#endif
template<typename _T1>
inline void
_Construct_novalue(_T1* __p)
{ ::new(static_cast<void*>(__p)) _T1; }首先上面是 constructor实现,借助
placement new实现.
placement new指的是,相比一般的new,此操作用于在已经分配的内存上创建对象.一般语法为:>A *p = new (mem) A;
而关于
destory的实现则是比较复杂的.主要有两个版本,一个是直接基于一个指针,另一个是借助两个迭代器.
下面这两个是
Destory中最基础的部分,很多其他接口都是基于它们实现的.
template<typename _Tp>
inline void
_Destroy(_Tp* __pointer)//基于一个指针实现的,直接调用其析构函数即可.
{ __pointer->~_Tp(); }
template<bool>
struct _Destroy_aux
{
template<typename _ForwardIterator>
static void
__destroy(_ForwardIterator __first, _ForwardIterator __last)//基于迭代器实现的,将两个迭代器之间的逐个析构
{
for (; __first != __last; ++__first)
std::_Destroy(std::__addressof(*__first));//值得注意的是,迭代器之间的每一个都是调用的_Destory!!!!
}
};如果迭代器之间的范围很大.并且都是那种
trivial destroy,那么将会造成效率的浪费.
其解决方法为:首先借助 value_type判断是否为
trivial,如果是,就什么也不做,否则就对每个对象调用第一类型的析构函数
具体实现如下:
template<typename _ForwardIterator>
inline void
_Destroy(_ForwardIterator __first, _ForwardIterator __last)
{
typedef typename iterator_traits<_ForwardIterator>::value_type
_Value_type;
#if __cplusplus >= 201103L
// A deleted destructor is trivial, this ensures we reject such types:
static_assert(is_destructible<_Value_type>::value,
"value type is destructible");
#endif
std::_Destroy_aux<__has_trivial_destructor(_Value_type)>::
__destroy(__first, __last);
}std::alloc中的分配与释放
主要见 <stl_alloc.h>,其中设计考虑到问题如下:
- 多线程
- 分配在堆上.
- 考虑内存不足的对策.
- 考虑内存碎皮问题.
其中主要介绍一下,第一级分配器和第二级分配器.
第一级分配器,也就是
__malloc_alloc_template实现方式如下:
template <int __inst>
class __malloc_alloc_template {
private:
static void* _S_oom_malloc(size_t);
static void* _S_oom_realloc(void*, size_t);
#ifndef __STL_STATIC_TEMPLATE_MEMBER_BUG
static void (* __malloc_alloc_oom_handler)();
#endif
public:
static void* allocate(size_t __n)
{
void* __result = malloc(__n);
if (0 == __result) __result = _S_oom_malloc(__n);
return __result;
}
static void deallocate(void* __p, size_t /* __n */)
{
free(__p);
}
static void* reallocate(void* __p, size_t /* old_sz */, size_t __new_sz)
{
void* __result = realloc(__p, __new_sz);
if (0 == __result) __result = _S_oom_realloc(__p, __new_sz);
return __result;
}
static void (* __set_malloc_handler(void (*__f)()))()
{
void (* __old)() = __malloc_alloc_oom_handler;
__malloc_alloc_oom_handler = __f;
return(__old);
}
};其实现方式还是比较简单的,主要是对于 malloc和
free的封装.对于分配失败的情况,也就是当调用
malloc返回为0的时候,会调用 _S_oom_malloc或者
_S_oom_realloc进行处理.这其实是一种类似于
new-handler的机制.
new-handler是一种当内存分配时,如果无法满足,就会调用一个我们所指定的处理函数(handler).
之所以不使用
operator new + new-handler的原因除了历史原因,还因为C++中没有关于
realloc的支持.
而对于它们的处理方式,实现方式如下:
template <int __inst>
void*
__malloc_alloc_template<__inst>::_S_oom_malloc(size_t __n)
{
void (* __my_malloc_handler)();//一个函数指针,用于指向“内存不足处理例程”
void* __result;
for (;;) {
__my_malloc_handler = __malloc_alloc_oom_handler;//设置“内存不足处理例程”
if (0 == __my_malloc_handler) { __THROW_BAD_ALLOC; }//如果未进行设置,就直接抛出异常
(*__my_malloc_handler)();//每一轮都进行尝试调用
__result = malloc(__n);//尝试分配内存,realloc对应的处理,只有这一行代码不同: __result = realloc(__p, __n);
if (__result) return(__result);//知道满足要求时,返回.
}
}简而言之,这个内存不足所触发的处理函数,处于一个无限循环中,每一寸循环反复地调用“内存不足处理例程”,执行完之后就再次尝试分配内存,知道成功时返回,如果没有设置相应的“内存不足处理例程”,就直接抛出异常.
而关于
__default_alloc_template的实现方式,相对而言要复杂得多.
由于在堆上分配内存时,都要留一个
cookie,这是一种内存的额外开销,尤其对于较小的内存块,导致空间利用率比较低.除此以外还要考虑内存空间碎片的问题.所以第二级分配器做法如下:
- 大于128B的交给
__malloc_alloc_template. - 否则,交给内存池管理.
首先我们来看一下 free-list和内存池相关的实现.
__PRIVATE:
union _Obj {
union _Obj* _M_free_list_link;
char _M_client_data[1]; /* The client sees this. */
};
private:
# if defined(__SUNPRO_CC) || defined(__GNUC__) || defined(__HP_aCC)
static _Obj* __STL_VOLATILE _S_free_list[];
// Specifying a size results in duplicate def for 4.1
# else
static _Obj* __STL_VOLATILE _S_free_list[_NFREELISTS];
# endif上面的代码是关于 free-list的部分,其中
_Obj定义了节点,节点采用了联合的方式,这助于节省内存空间.既可以视为一个指向下一节点的指针,也可以视为保存着内容的内存块.
一般采用的是链表的数组,也就是
_NFREELISTS(16)个.对应着不同大小.
其中主要的函数接口和第一级一样,只不过增加了其他用于内存管理的数据结构及其操作.所以下面首先还是从几个基本的函数接口说起.
首先是 allocate的实现.
static void* allocate(size_t __n)
{
void* __ret = 0;
if (__n > (size_t) _MAX_BYTES) {//对于大于_MAX_BYTES(128B)的,直接调用第一级分配器.
__ret = malloc_alloc::allocate(__n);
}
else {
_Obj* __STL_VOLATILE* __my_free_list
= _S_free_list + _S_freelist_index(__n);
// Acquire the lock here with a constructor call.
// This ensures that it is released in exit or during stack
// unwinding.
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;
# endif
_Obj* __RESTRICT __result = *__my_free_list;
if (__result == 0)
__ret = _S_refill(_S_round_up(__n));
else {
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
}
return __ret;
};简而言之,首先根据其大小,检索出在 free-list中对应索引的
list,然后在尝试直接从这个链表中拿出空闲块,如果失败,就调用
_S_refill进行处理,如果成功,就将该内存块取走,并且调整
free-list.至于
_S_refill的作用会在后面进行说明.
然后是 deallocate的实现:
static void deallocate(void* __p, size_t __n){
if (__n > (size_t) _MAX_BYTES)
malloc_alloc::deallocate(__p, __n);
else {
_Obj* __STL_VOLATILE* __my_free_list
= _S_free_list + _S_freelist_index(__n);
_Obj* __q = (_Obj*)__p;
// acquire lock
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;
# endif /* _NOTHREADS */
__q -> _M_free_list_link = *__my_free_list;
*__my_free_list = __q;
// lock is released here
}
}这个过程是比较简单的,简而言之,就是先根据大小索引出对应的链表,然后将要释放的内存块的转型为
_Obj,将此内存块的下一节指向对应链表,并且将链表的头部移动到新加入的内存块上.
剩余的一些关于 allocator的细节,暂鸽
3.iterator
在设计STL时,有一种重要的思想就是将容器和算法分离,最后以一种粘合剂将两者联系起来.这就是迭代器的地位.
首先我们可以说迭代器是一种smart
pointer,首先我们考虑一下指针的操作中,最重要的是
dereference和 access,也就是说
operator *和
operator ->的重要性.比如说,我们可以在
auto_ptr发现这种方法的实现.
auto_ptr几乎就是对一个指针的一层封装,其中重点需要我们关注的地方就在于它提供了对于
operator *和 operator ->的重载.
类似于下面的这种实现方式.
template<typename T>
class ListIterator {
public:
ListIterator(T *p = 0) : m_ptr(p){}
T& operator*() const { return *m_ptr;} //取值,即dereference
T* operator->() const { return m_ptr;} //成员访问,即member access
//...
};如果我们想要为一个链表设计一个迭代器,应该怎么设计呢?相比
auto_ptr而言,不仅仅是 operator *和
operator ->和重载,还有
operator ++的重载,这对于链表来说,相当于节点指针的移动.
template <class Item>
struct ListIter {
Item *ptr; // 保持与容器的联系
ListIter(Item* p =0) : ptr(p) {}
Item& operator*() const {
return *ptr;
}
Item* operator->() const {
return ptr;
}
ListIter& operator++() {//这意味着在list上后下一个节点移动
ptr = ptr->next();
return *this;
}
ListIter operator++(int) {
ListIter temp = *this;
++*this;
return temp;
}
bool operator==(const ListIter& i) const {
return ptr == i.ptr;
}
bool operator!=(const ListIter& i) const {
return ptr != i.ptr;
}
};下面我们简单地看一下 find是怎么借助迭代器实现的.由于
find函数内部需要借助"!="来检验每个元素是否与目标的value相吻合,因此还需要对“!=”进行重载.
如果想要设计出 list的迭代器需要对
list的很多实现的细节有所了解,很多STL都提供自己专属的迭代器.
1)迭代器 associated types
我们也时常将迭代器所指对象的类型,称为
value type.
除此之外 associated types总共有5种:
value type,迭代器所指对象的类型.difference type.两个迭代器之间的距离,可以用来表示一个容器的最大容量.reference type,主要分为const和non-const,也就是说,迭代器所指对象是否可以改变.pointer type.iterator type,迭代器种类,这个是比较复杂的问题.在后面细说.
2) template 参数推导
我们在此介绍的参数推导的方式主要是借助
function template来进行参数推导.就一下面这串代码为例,当带入
func的时候,会根据第二个参数不同类型往下进入不同的重载版本.
template <class I>
inline void func(I iter) {
func_imp(iter, *iter); // 传入 iter 和 iter 所指的值,class 自动推导
}
template <class I>
void func_imp(I& p, B) {
cout << "B version" << endl;
}
template <class I>
void func_imp(I& p, D2) {
cout << "D2 version" << endl;
}
int main() {
int * p;
func(p, B());
func(p, D1());
func(p, D2());
}就像上面,我们可以在不同的
func_imp中有不同类型的返回值,但是用户直接调用的往往是
func.
3)声明内嵌型别
可以考虑加上内嵌型别:为指定的对象类型定义一个别名,然后可以将此别名直接获取.实现方式如下:
template<typename T>
class MyIter {
public:
typedef T value_type; //内嵌类型声明
MyIter(T *p = 0) : m_ptr(p) {}
T& operator*() const { return *m_ptr;}
private:
T *m_ptr;
};
//以迭代器所指对象的类型作为返回类型
//注意typename是必须的,它告诉编译器这是一个类型
template<typename MyIter>
typename MyIter::value_type Func(MyIter iter) {
return *iter;
}
int main(int argc, const char *argv[]) {
MyIter<int> iter(new int(666));
std::cout<<Func(iter)<<std::endl; //print=> 666
}就像上面这样,可以实现一个能够返回迭代器
value type类型的对象.但是这种做法还是存在一定的问题的:我们当前的迭代器是一个以
class type的方式实现的,倘若我们的迭代器只是一个原生的指针,就难以嵌入一个
value_type.
再次强调,内嵌型别只适合一般情况,也就是迭代器是以
class type实现的情况.
4) Partial Specialization
这种方法用来解决上面所提到的问题.
Partial Specialization指的是,如果我们的class template拥有一个以上的参数,那么我们可以对其中的某个参数进行特化工作.可以理解为,为某一种特化的情况,提供另一种
template定义.
比如说.
template<typename T>//一般的范化版本
class C {...};
//特化版本,适用于T为原生指针的情况.
template<typename T>
class C<T *> {...};5) 萃取机的应用与实现
下面我们可以介绍一下"参数推导机制+内嵌型别机制获取型别+Partial Specialization"在STL中的应用方式了.
因此STL中引入中间一层机制,作为萃取机,萃取机能够根据带入的迭代器类型,进而“推导”出相应的
associaed type然后可以直接获取
associaed type.实现方式如下:
template <class _Iterator>//一般的泛化模式
struct iterator_traits {
typedef typename _Iterator::iterator_category iterator_category;
typedef typename _Iterator::value_type value_type;
typedef typename _Iterator::difference_type difference_type;
typedef typename _Iterator::pointer pointer;
typedef typename _Iterator::reference reference;
};在引入 traits之后,其应用方式有如下的变化.
template<typename Iterator> //引入萃取机之前
typename Iterator::value_type func(Iterator iter) {
return *iter;
}
template<typename Iterator> //引入萃取机之后
typename iterator_traits<Iterator>::value_type func(Iterator iter) {
return *iter;
}除此之外,对于原生指针的情况,会使用
partial specialization的方式来实现.下面是对于一种偏特化的实现方式,支持原生指针.
template <class _Tp>
struct iterator_traits<_Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};除了原生指针之外,还有对于指向常量的指针也会采用
partial specialization.
template <class _Tp>
struct iterator_traits<const _Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef const _Tp* pointer;
typedef const _Tp& reference;
};所以直到这里,关于
traits的方法也就讲得差不多了,主要是借助增加一个中间的
template class,这个类可以获取迭代器的
associated type,对于一般的
class type的迭代器借助了其内嵌型别,对于一些特殊情况(原生指针,pointer-to-const)等,采用了
partial specialization的方法.
最终,对于一个函数 func我们可以实现一种固定的方式.
template <class I>
typename my_iterator_traits<I>::value_type Func(I ite) {
std::cout << "normal version" << std::endl;
return *ite;
}复盘一下,如果一个算法或者函数,需要知道迭代器的
associated type,会发生什么?
- 询问
iterator_traits. - 如果是
class type,其结果来自于其嵌入的type. - 如果是原生指针或者
pointer-to-const,则需要从偏特化的iterator_traits得出答案.
6) 迭代器的种类
迭代器分类方式的依据在于:读写和访问方式
分为如下几种:
input iterator.只写.output iterator,只读.forward iterator,读写单向移动.bidirectional iterator,读写双向移动.random access iterator,读写随机访问.
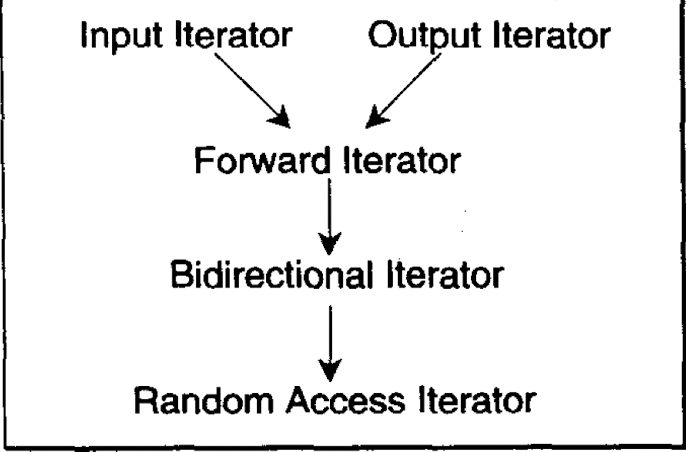
之所以划分成不同的迭代器种类,主要考虑的原因就在于:能够根据不同的类别,相应的算法能够采取不同的处理方式,进而达到效率最大化.
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};然后如果以input_iterator为例的话,其内部的第一个typedef也就是迭代器类型,就是关于input_iterator_tag这种结构体.
下面主要是 advance()和
distance()对于不同种类迭代器的不同处理方式.
在advance中,不同类型的迭代器实现方式不同.下图分别为InputIter,BidirectionalIterator,_RandomAccessIterator.
template <class _InputIter, class _Distance>
inline void __advance(_InputIter& __i, _Distance __n, input_iterator_tag) {
while (__n--) ++__i;
}//直接单项操作,只能向前
template <class _BidirectionalIterator, class _Distance>
inline void __advance(_BidirectionalIterator& __i, _Distance __n,
bidirectional_iterator_tag) {
__STL_REQUIRES(_BidirectionalIterator, _BidirectionalIterator);
if (__n >= 0)
while (__n--) ++__i;
else
while (__n++) --__i;//根据n的大小,要么向前要么向后.
}
template <class _RandomAccessIterator, class _Distance>
inline void __advance(_RandomAccessIterator& __i, _Distance __n,
random_access_iterator_tag) {
__STL_REQUIRES(_RandomAccessIterator, _RandomAccessIterator);
__i += __n;
}所以,最后总结,之所以要区分iterator item的方式是大大不同的.所以需要迭代器种类,进而做出最合适的算法.
4.Sequential Containers
常见的数据机构有:list,tree,stack,queue,hash table, set,map
其中根据数据在容器中的排列特性,分为序列式和关联式.
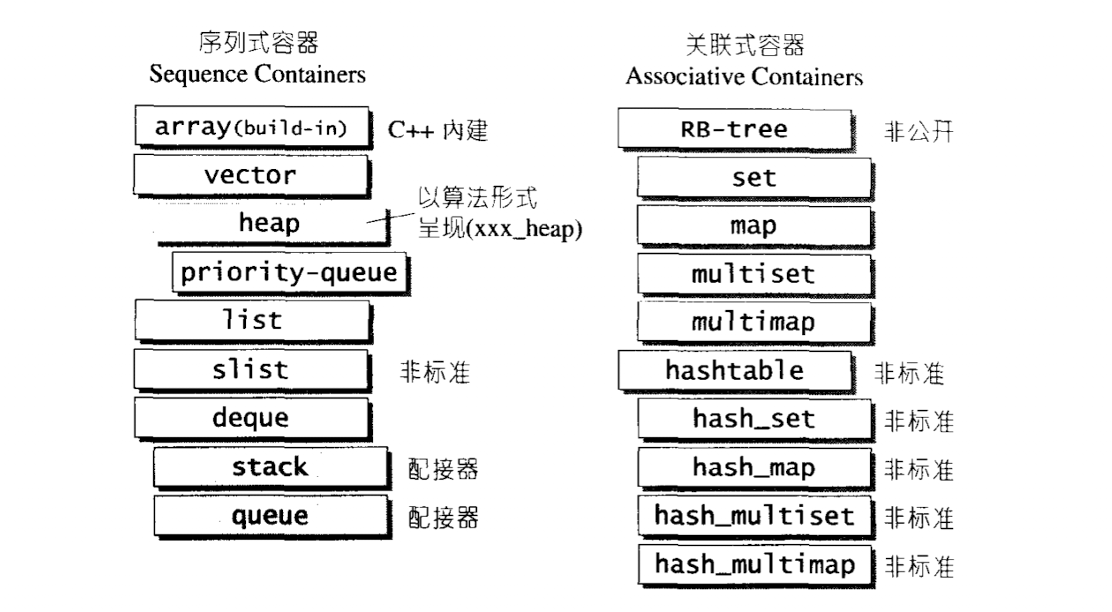
这里提到的衍生关系,主要指的是内含.比如说heap中内含有vector,stack,queue等都含有deque.
1) vector
我们在使用vector往往会加上头文件<vector>.其更底层的实现是<stl_vector.h>.下面将会从迭代器,数据结构,分配器还有相关算法上进行分析.
从总体上来说,对于vector的实现,是由一个vector类继承了一个_Vector_Base类组成的.
其中关于_Vector_base的定义如下:
template <class _Tp, class _Alloc>
class _Vector_base {
public:
typedef _Alloc allocator_type;
allocator_type get_allocator() const { return allocator_type(); }
_Vector_base(const _Alloc&)
: _M_start(0), _M_finish(0), _M_end_of_storage(0) {}
_Vector_base(size_t __n, const _Alloc&)
: _M_start(0), _M_finish(0), _M_end_of_storage(0)
{
_M_start = _M_allocate(__n);
_M_finish = _M_start;
_M_end_of_storage = _M_start + __n;
}
~_Vector_base() { _M_deallocate(_M_start, _M_end_of_storage - _M_start); }
protected:
_Tp* _M_start;
_Tp* _M_finish;
_Tp* _M_end_of_storage;
typedef simple_alloc<_Tp, _Alloc> _M_data_allocator;
_Tp* _M_allocate(size_t __n)
{ return _M_data_allocator::allocate(__n); }
void _M_deallocate(_Tp* __p, size_t __n)
{ _M_data_allocator::deallocate(__p, __n); }
};简而言之,其内容无非围绕这几个方面:
- allocator以及和分配有关的接口.
- 核心的数据结构(三个指针).
- 其自身(_Vector_base)的构造与析构函数.
而关于vector其代码组成比较复杂,但是仍然是:
template <class _Tp, class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
class vector : protected _Vector_base<_Tp, _Alloc> {...}所以说,我们对于分配器也是可以自己进行重定义的.
a.iterator
我们可以将vector视为一个可变长数组,因此普通指针就可以作为迭代器,并且我们需要向数组一样支持随机存储,因此其迭代器的种类就是Random Access Iterators.
typedef _Tp value_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type* iterator;
typedef const value_type* const_iterator;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;以上代码出现在vector的定义中,可见其迭代器只是普通的指针,更具体地说,是和该容器所存储的数据类型相同的指针.
b.数据结构
在前面说了,vector继承了一个_Vector_base,而核心的数据结构的定义,就在_Vector_base中,代码如下.
template <class _Tp, class _Alloc>
class _Vector_base {
//.............
protected:
_Tp* _M_start;//这一部分是核心的数据结构,也就是3个指针.
_Tp* _M_finish;
_Tp* _M_end_of_storage;
};其核心的数据结构就是三个指针,vector像数组一样维护一片连续的内存空间,而_M_start和_M_finish分别指向这片内存空间中目前已经被使用的范围,而_M_end_of_storage则指向的是这片内存的末尾.需要明确的是,_M_finish未必总是等于_M_end_of_storage因为vector会留有备用空间.内存容量永远大于等于其使用的大小.
下面举几个例子,来看一下怎样借助这几个指针表达出一些操作,比如begin(),end(),size(),empty().这些定义是来源于vector类内部的.
iterator begin() { return _M_start; }
const_iterator begin() const { return _M_start; }
iterator end() { return _M_finish; }
const_iterator end() const { return _M_finish; }
reference operator[](size_type __n) { return *(begin() + __n); }
const_reference operator[](size_type __n) const { return *(begin() + __n);}
以上这几个操作,都是可以只借助这几个指针表达出来的.而对于其他操作insert,push_back等则比较复杂,不仅仅需要使用指针,还需要涉及到内存分配,构造等操作.
c.vector的构造与allocator
这一部分是非常复杂的.
由于vector是具由_Vector_base继承而来的,所以我们分析其构造函数应该分为两个部分.首先来看一下_Vector_base部分.
_Vector_base(const _Alloc&)
: _M_start(0), _M_finish(0), _M_end_of_storage(0) {}
// 初始化,分配空间
_Vector_base(size_t __n, const _Alloc&)
: _M_start(0), _M_finish(0), _M_end_of_storage(0)
{
_M_start = _M_allocate(__n);
_M_finish = _M_start;
_M_end_of_storage = _M_start + __n;
}
// 释放空间
~_Vector_base() { _M_deallocate(_M_start, _M_end_of_storage - _M_start);}
除了对于三个指针进行初始化之外,构造函数还会调用_M_allocate分配内存空间,而_M_deallocate用于析构函数.对于这两个函数的定义,也被封装在了_Vector_base之中,并且只是对allocator中分配和释放的简单的一层封装而已.
_Tp* _M_allocate(size_t __n)
{ return _M_data_allocator::allocate(__n); }
void _M_deallocate(_Tp* __p, size_t __n)
{ _M_data_allocator::deallocate(__p, __n); }而对于vector,这个数据结构对于基类而说并没有扩展额外的数据成员.
其构造函数主要如下:
explicit vector(const allocator_type& __a = allocator_type())
: _Base(__a) {}
//构造拥有 n 个有值 value 的元素的容器
vector(size_type __n, const _Tp& __value,
const allocator_type& __a = allocator_type())
: _Base(__n, __a)
{ _M_finish = uninitialized_fill_n(_M_start, __n, __value); }
explicit vector(size_type __n)
: _Base(__n, allocator_type())
{ _M_finish = uninitialized_fill_n(_M_start, __n, _Tp()); }
//拷贝构造,构造拥有 __x 内容的容器
vector(const vector<_Tp, _Alloc>& __x)
: _Base(__x.size(), __x.get_allocator())
{ _M_finish = uninitialized_copy(__x.begin(), __x.end(), _M_start); }除了对于基类的初始化之外,还多了对于uninitialized_fill_n和uninitialized_copy的调用.关于uninitialized_fill_n,其底层实现使用traits来判别类型,并且决定使用fill_n()算法或者反复调用construct()来完成任务.主要起到填充内存段内内容的作用.填充为参数__value.
而对于其析构函数
~vector() { destroy(_M_start, _M_finish); }主要是调用了destroy来释放内存空间.
关于vector中所使用的分配器,在默认情况下是alloc其机制,在之前分析过.
其中最重要的部分就在于内存动态增长的方式.涉及到此机制的操作主要有push_back(),resize(),reserve()等.首先来分析一下:
void _M_insert_aux(iterator __position, const _Tp& __x);
void _M_insert_aux(iterator __position);其具体实现如下:
template <class _Tp, class _Alloc>
void
vector<_Tp, _Alloc>::_M_insert_aux(iterator __position, const _Tp& __x)
{
if (_M_finish != _M_end_of_storage) {
construct(_M_finish, *(_M_finish - 1));
++_M_finish;
_Tp __x_copy = __x;
copy_backward(__position, _M_finish - 2, _M_finish - 1);
*__position = __x_copy;
}
else {// 没有备用空间
const size_type __old_size = size();//得到当前的元素数量.
const size_type __len = __old_size != 0 ? 2 * __old_size : 1;//根据size是否为0,得出需要分配的空间大小,要么是2倍要么是1.
iterator __new_start = _M_allocate(__len);//调用分配器,分配空间得出start
iterator __new_finish = __new_start;
__STL_TRY {
__new_finish = uninitialized_copy(_M_start, __position, __new_start);
construct(__new_finish, __x);
++__new_finish;
__new_finish = uninitialized_copy(__position, _M_finish, __new_finish);
}
__STL_UNWIND((destroy(__new_start,__new_finish),
_M_deallocate(__new_start,__len)));
destroy(begin(), end());//讲旧的内存区释放.
_M_deallocate(_M_start, _M_end_of_storage - _M_start);
_M_start = __new_start;
_M_finish = __new_finish;
_M_end_of_storage = __new_start + __len;
}
}上面展示的这个函数主要被push_back()所调用.当push_back()备用空间不够时,就会调用这个函数,简而言之,当发生内存不足时:
- 如果没有元素,那么就扩充为1,否则是原来的2倍.
- 分配一片新的内存空间,因此可以说扩充后,元素将不再和扩充前处于同一片内存区.
- 数据拷贝.
- 旧的的内存空间析构并释放内存.
- 设置好新的
_M_start,_M_finish,_M_end_of_storage.
d.vector的主要操作
关于push_back()的实现.需要注意的是_M_finish和`_M_end_of_storage,前者指向的是指向已使用空间的末端位置+1,后者是指向所分配数组的末尾位置+1.
void push_back(const _Tp& __x) {
if (_M_finish != _M_end_of_storage) { // 有备用空间
construct(_M_finish, __x); // 全局函数,将 __x 构造到 _M_finish 指针所指的空间上
++_M_finish; // 调整
}
else
_M_insert_aux(end(), __x); // 无备用空间,从新分配再插入
}关于pop_back()
void pop_back() {
--_M_finish;
destroy(_M_finish);
}实现地比较简单,主要是移动_M_finish,并且析构末尾的元素.为什么不释放相应的内存呢?因为预留空间总是大于等于已用空间,所以预留空间的内存是不能随便释放的.
iterator erase(iterator __position) {//返回值是迭代器,也就是一个指针.
if (__position + 1 != end())
copy(__position + 1, _M_finish, __position); // 全局函数
--_M_finish;
destroy(_M_finish);
return __position;
}如果是最后一个,就不会执行if分支中的内容,因此就和pop_back()一样了,只不过多了一个拷贝内存的函数,和一般的数组进行erase()区别不大.clear()的实现非常简单,只是一个封装了的erase(),以迭代器为参数的版本.
而关于resize()则是基于erase()和insert()(以迭代器为参数的版本)实现的.
关于insert()的实现是比较复杂的.
iterator insert(iterator __position, const _Tp& __x) {
size_type __n = __position - begin();//判断这之间的元素数量
if (_M_finish != _M_end_of_storage && __position == end()) {
construct(_M_finish, __x);//如果只是插入到末尾并且还有储备空间
++_M_finish;//和一般的push_back()没有区别.
}
else
_M_insert_aux(__position, __x);
return begin() + __n;//返回的也是指针,指向所插入元素的地址.
}最后,总体来说,vector就是一种封装了的,可以动态增长空间的高级数组,需要注意的是每次需要动态扩容时,扩容前后的所使用的内存空间往往不是同一块.这种现象容易带来的陷阱就是是已获取的迭代器失效,因为发生扩容之后,旧的内存空间已经释放,此时迭代器可能指向旧的内存地址,所以就是无效的.
2) list
list简而言之是一种链表.
a.list的数据结构
首先我们来看一下,链表节点的实现方式:
struct _List_node_base {
_List_node_base* _M_next;
_List_node_base* _M_prev;
};
template <class _Tp>
struct _List_node : public _List_node_base {
_Tp _M_data;
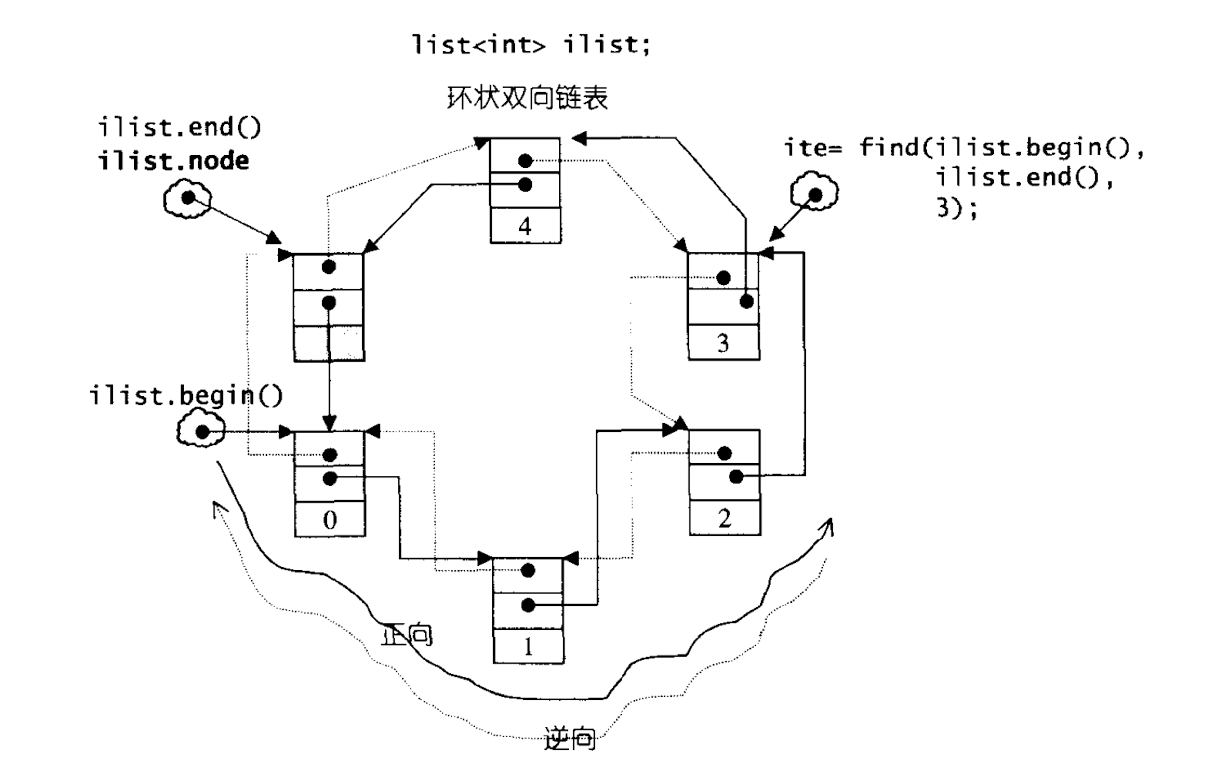
};一个节点主要分为两个部分,一个数据部分是我们所指定的类型,还有一个部分就是指针部分,指针部分的类型是固定的,始终就是_List_node_base.并且是一个双向链表.
在SGI中是一种环状双向链表.首先分析的是_List_base.
template <class _Tp, class _Alloc>
class _List_base
{
//............省略
protected:
// 专属之空间配置器,每次配置一个节点大小,下面这一部分就是对于分配器的封装部分
typedef simple_alloc<_List_node<_Tp>, _Alloc> _Alloc_type;
_List_node<_Tp>* _M_get_node() { return _Alloc_type::allocate(1); } // 分配一个节点并返回地址
void _M_put_node(_List_node<_Tp>* __p) { _Alloc_type::deallocate(__p, 1); } // 释放一个节点
protected:
_List_node<_Tp>* _M_node; // 只要一个指针,便可表示整个环状双向链表,空白节点
};
之后还有一个继承了_List_base的类list,也就是用户直接接触的list.这一部分除了继承了_List_base之外没有什么涉及到核心数据结构的东西.
b.List Iterator
这里迭代器的实现方式,也是采用了一个基类在加派生类的方式实现的,其中迭代器的基类中也说明了一个迭代器的类型.
struct _List_iterator_base {
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef bidirectional_iterator_tag iterator_category; // 双向移动迭代器
_List_node_base* _M_node; // 迭代器内部当然要有一个普通指针,指向 list 的节点
_List_iterator_base(_List_node_base* __x) : _M_node(__x) {}
_List_iterator_base() {}
void _M_incr() { _M_node = _M_node->_M_next; } // 前驱
void _M_decr() { _M_node = _M_node->_M_prev; } // 后继
// 比较两个容器操作
bool operator==(const _List_iterator_base& __x) const {
return _M_node == __x._M_node;
}
bool operator!=(const _List_iterator_base& __x) const {
return _M_node != __x._M_node;
}
}; 其中说明了迭代器是一种双向迭代器,并且核心在于一个_List_node_base *,也就是说是一个指向节点指针部分的指针.
其迭代器相比vector有一个重要的特征,vector会因为扩容导致的内存空间变化而导致迭代器失效,但是list的迭代器往往除了被删除的节点之外,都不会面临这种问题.
template<class _Tp, class _Ref, class _Ptr>
struct _List_iterator : public _List_iterator_base {
typedef _List_iterator<_Tp,_Tp&,_Tp*> iterator;
typedef _List_iterator<_Tp,const _Tp&,const _Tp*> const_iterator;
typedef _List_iterator<_Tp,_Ref,_Ptr> _Self;
typedef _Tp value_type;
typedef _Ptr pointer;
typedef _Ref reference;
typedef _List_node<_Tp> _Node;
_List_iterator(_Node* __x) : _List_iterator_base(__x) {}
_List_iterator() {}
_List_iterator(const iterator& __x) : _List_iterator_base(__x._M_node) {}
reference operator*() const { return ((_Node*) _M_node)->_M_data; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
_Self& operator++() {
this->_M_incr();
return *this;
}
_Self operator++(int) {
_Self __tmp = *this;
this->_M_incr();
return __tmp;
}
_Self& operator--() {//这个是前置++,和后置++不同其返回参数是self &.
this->_M_decr();
return *this;
}
_Self operator--(int) {
_Self __tmp = *this;
this->_M_decr();
return __tmp;
}
};简单总结如下:
- 关于++和--的重载,主要是迭代器在节点上的移动.
- *和->分别是取节点的数据值和成员存取.
- 构造函数也主要是初始化基类.
c.List的构造与内存管理
关于构造函数的话,要在List_base中.
_List_base(const allocator_type&) {
_M_node = _M_get_node();
_M_node->_M_next = _M_node;
_M_node->_M_prev = _M_node;
}
~_List_base() {
clear();
_M_put_node(_M_node);
}和一般我们在实现一个双向链表的初始化操作没什么两样.而对于list的构造函数
list(const _Tp* __first, const _Tp* __last,
const allocator_type& __a = allocator_type())
: _Base(__a)
{ this->insert(begin(), __first, __last); }
list(const_iterator __first, const_iterator __last,
const allocator_type& __a = allocator_type())
: _Base(__a)
{ this->insert(begin(), __first, __last); }d.list的主要操作
其操作还是挺多的.
3) deque
首先来看一些deque相关的文件组成:deque---->deque.h---->stl_deque.h,将重点放在对于stl_deque.h的分析上.
a.数据结构
deque即为双向队列,适合需要频繁地从首部和尾部取出或者增加元素的场景.
deque所使用的内存空间和vector一样,都是线性的.不过相比vector,并没有容量和保留的概念,其内存空间是以分段连续内存空间组合而成的,随时可以有新的内存空间拼接起来.
和其他容器一样,其数据结构的基本实现体现在base类里,此容器仍然分了两层类去实现.
template <class _Tp, class _Alloc>
class _Deque_base {
public:
//......
protected:
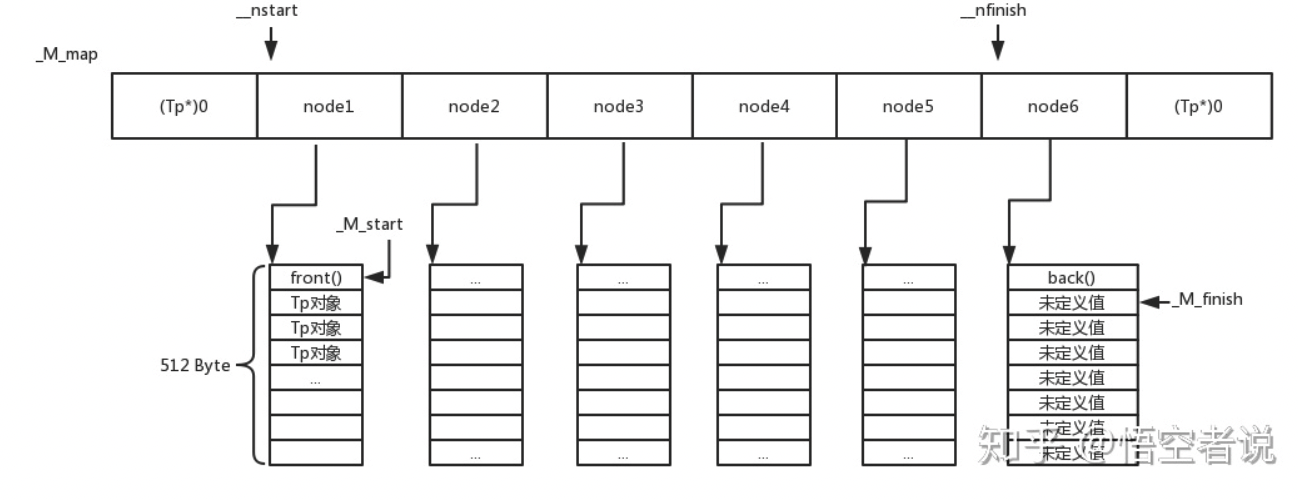
_Tp** _M_map;//指向指针的指针,可以说每一个指针都指向一个连续的内存空间
size_t _M_map_size;//_M_map的指针数
iterator _M_start;//指向首部元素
iterator _M_finish;//指向尾部元素
//......
};其中_M_start和_M_finish都是迭代器类型的,而duque迭代器的相关如下:
typedef _Deque_iterator<_Tp,_Tp&,_Tp*> iterator;至于迭代器的实现的细节,在后面会说,但是简而言之,这里的_M_start和_M_finish是指向_M_map上元素的指针,也就是指向指针的指针.
所以至此,我们发现虽然说deque是连续的,但也只是分段连续而已.
B.迭代器
template <class _Tp, class _Ref, class _Ptr>
struct _Deque_iterator {
typedef _Deque_iterator<_Tp, _Tp&, _Tp*> iterator;//迭代器
typedef _Deque_iterator<_Tp, const _Tp&, const _Tp*> const_iterator;
static size_t _S_buffer_size() { return __deque_buf_size(sizeof(_Tp)); }
typedef random_access_iterator_tag iterator_category;//关联类型的定义
typedef _Tp value_type;
typedef _Ptr pointer;
typedef _Ref reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef _Tp** _Map_pointer;
typedef _Deque_iterator _Self;
_Tp* _M_cur;
_Tp* _M_first;
_Tp* _M_last;
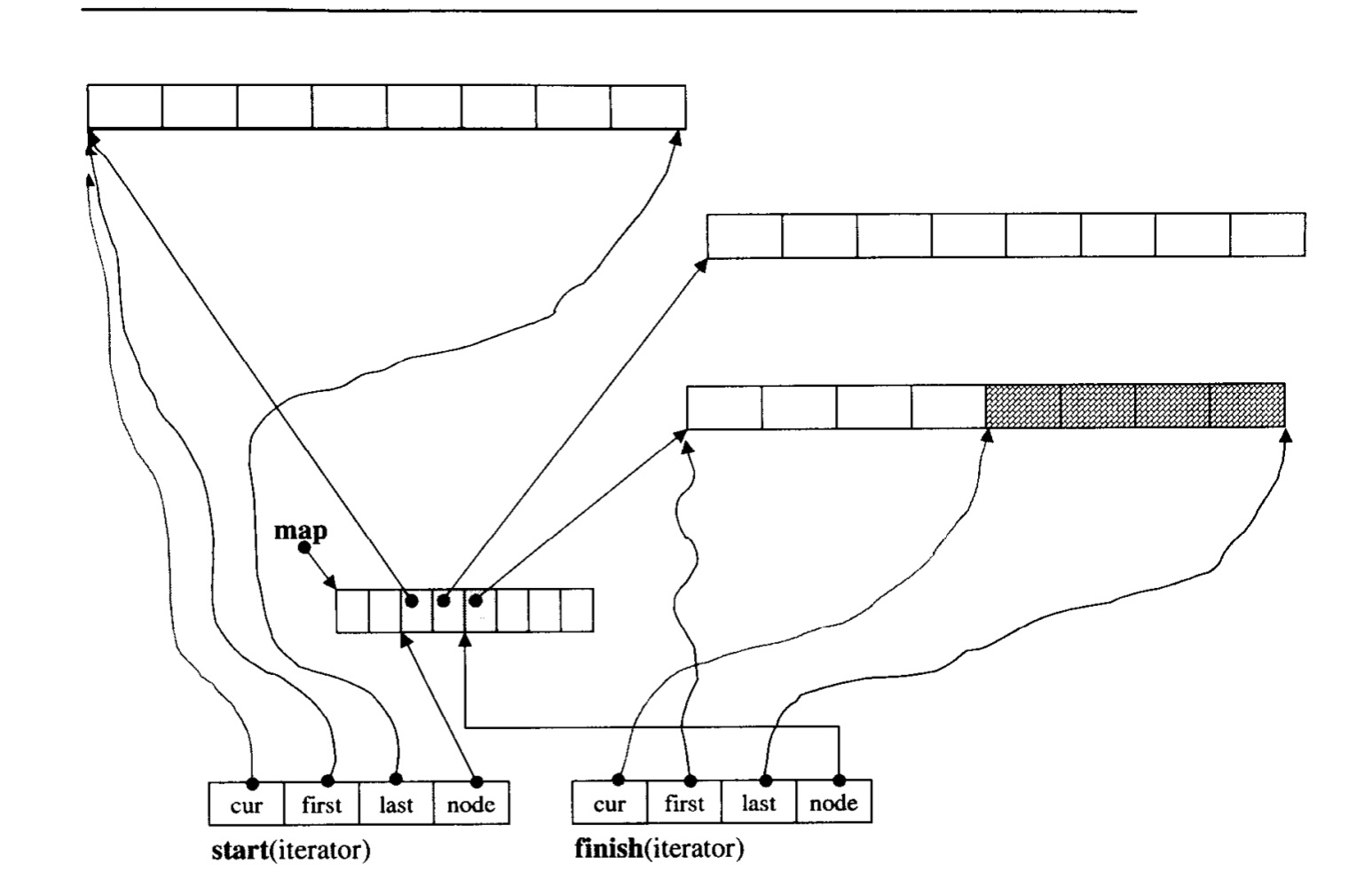
_Map_pointer _M_node;这一部分是支撑起整个迭代器发挥作用的几个指针,其中_M_cur,_M_first,_M_last此三者都是直接指向某个元素的,这三者都是局限于同一个缓冲区中的,而_M_node则是一个指向指针的指针,指向某个缓冲区.
由于之前了解到,deque实质上只是分段连续的容器,而不想vector是整一个数组都是连续的.所以在指针移动时,有一个问题就在于如何维护这种整体连续的假象,尤其是当到达了某个缓冲区的边界的时候,怎样移动才能移动到其他缓冲区,从而得出正确的位置?这主要取决于迭代器中关于++,--等运算符重载的实现.
_Self& operator++() {
++_M_cur;
if (_M_cur == _M_last) {
_M_set_node(_M_node + 1);
_M_cur = _M_first;
}
return *this;
}
_Self operator++(int) {//这个指的是后++,实现方式上可以看作是接住了前置++实现的
_Self __tmp = *this;
++*this;
return __tmp;
}
_Self& operator--() {
if (_M_cur == _M_first) {
_M_set_node(_M_node - 1);
_M_cur = _M_last;
}
--_M_cur;
return *this;
}
_Self operator--(int) {//借助前置--实现
_Self __tmp = *this;
--*this;
return __tmp;
}简而言之,相比全连续容器单纯地++或者--,deque则多了特判,主要作用在于判断是否已经达到缓冲区边界了.关于缓冲区的边界,需要关注_M_last和_M_first.也就是当前所处缓冲区的边界两个指针.当到达边界时,移动_M_map并且设置_M_cur在此缓冲区的位置,一般是开头或者末尾.其中_M_set_node实现的细节如下:
void _M_set_node(_Map_pointer __new_node) {
_M_node = __new_node;
_M_first = *__new_node;
_M_last = _M_first + difference_type(_S_buffer_size());
}这个函数的主要作用在于当cur移动到其他缓冲区时,对相应的_M_node,_M_first,_M_last进行调整.,其参数为cur所移动到的缓冲区的指针.
主要用于改变`_M_node(所处的缓冲区),_M_first和_M_last.进而可以适应所处缓冲区的变化.
除此之外,为了支持内存的随机访问,考虑这几个迭代器中的实现.
_Self& operator+=(difference_type __n)
{
difference_type __offset = __n + (_M_cur - _M_first);
if (__offset >= 0 && __offset < difference_type(_S_buffer_size()))//如果处于同一个缓冲区内
_M_cur += __n;//就直接移动_M_cur指针
else {
difference_type __node_offset =
__offset > 0 ? __offset / difference_type(_S_buffer_size())
: -difference_type((-__offset - 1) / _S_buffer_size()) - 1;//首先计算跨越的缓冲区数量
_M_set_node(_M_node + __node_offset);//移动缓冲区,以及相应的first和finish指针
_M_cur = _M_first + //移动在cur在新缓冲区的位置
(__offset - __node_offset * difference_type(_S_buffer_size()));
}
return *this;
}+=的重载对于其他运算符比如+,-,[]都具有重要的意义,也可以说这些运算符重载的实现一定程度上都是基于+=实现的.简单地说,+=的意义在于直接跳跃几个元素.其在实现时根据是否出现缓冲区的跨越来分为不同的分支.
关于+,[],-等都是基于+=实现的一层封装,
_Self operator+(difference_type __n) const
{
_Self __tmp = *this;
return __tmp += __n;
}
_Self& operator-=(difference_type __n) { return *this += -__n; }
_Self operator-(difference_type __n) const {
_Self __tmp = *this;
return __tmp -= __n;
}
reference operator[](difference_type __n) const { return *(*this + __n); }在关于比较的几个运算的重载,主要是比较迭代器中指针的地址,如果在同一个缓冲区就比较_M_cur,否则就只比较缓冲区的地址.
bool operator==(const _Self& __x) const { return _M_cur == __x._M_cur; }//只比较cur即可
bool operator!=(const _Self& __x) const { return !(*this == __x); }
bool operator<(const _Self& __x) const {//区分了是否处于同一个缓冲区的情况.
return (_M_node == __x._M_node) ?
(_M_cur < __x._M_cur) : (_M_node < __x._M_node);
}
bool operator>(const _Self& __x) const { return __x < *this; }//根据<变换而来
bool operator<=(const _Self& __x) const { return !(__x < *this); }
bool operator>=(const _Self& __x) const { return !(*this < __x); }所以,迭代器中有关于运算符重载的实现上有这几类:
++,--的实现.+,-,[]等实现,这些主要是为实现随机访问服务的,这些实现中最基础的部分就是+=的实现.==,<=,!=等比较运算符的实现,其中==,<是最基础的,其他的主要根据逻辑关系进行变换实现的.
总的来说,deque的迭代器是四个指针组成的,其中有一个指向缓冲区的指针,还有三个指针表示该缓冲区的首尾边界,以及指向当前处于的位置.对于运算符重载方面,其中和vector最大的不同在于,需要特判是否到达该缓冲区的边界,并且需要把握好各重载运算符之间的关系,其中++,--,+=等运算符是最基础的.记住,这些操作的实现总是围绕着:deque的内存利用是分段式的连续.
所以我们可以发现,当我们需要访问需要跨越比较长的一段内存空间时,可能需要跨越map的多个段,其开销将会比较显著.
c.deque的构造与内存管理
在这里,与构造和内存管理息息相关的是push_back,push_front,以及deque的构造函数等.
关于deque中的分配器,主要有两个部分,一个是用于分配元素(node)的,另一个用于分配缓冲区指针(map)的.
在_Deque_base中的定义如下:
template <class _Tp, class _Alloc>
class _Deque_base {
public:
//......
protected:
//......
typedef simple_alloc<_Tp, _Alloc> _Node_alloc_type;//每次用于为一个元素分配空间
typedef simple_alloc<_Tp*, _Alloc> _Map_alloc_type;//每次为一个缓冲区指针(map)分配空间
_Tp* _M_allocate_node()//直接调用node分配器,为一个node分配空间
{ return _Node_alloc_type::allocate(__deque_buf_size(sizeof(_Tp))); }
void _M_deallocate_node(_Tp* __p)//调用node分配器中的deallocate,释放一个元素的空间
{ _Node_alloc_type::deallocate(__p, __deque_buf_size(sizeof(_Tp))); }
_Tp** _M_allocate_map(size_t __n) //调用map分配器,为一个map分配空间
{ return _Map_alloc_type::allocate(__n); }
void _M_deallocate_map(_Tp** __p, size_t __n) //调用map分配器中的deallocate
{ _Map_alloc_type::deallocate(__p, __n); }
//......
};在这里,这几个函数可以说是对分配器allocate和deallocate最直接的封装,这些函数往往会被调用于其他的构造或创建的操作中,如下:
template <class _Tp, class _Alloc>
void _Deque_base<_Tp,_Alloc>::_M_create_nodes(_Tp** __nstart, _Tp** __nfinish)
{
_Tp** __cur;
__STL_TRY {
for (__cur = __nstart; __cur < __nfinish; ++__cur)//从一段map中创建新的节点
*__cur = _M_allocate_node();
}
__STL_UNWIND(_M_destroy_nodes(__nstart, __cur));
}
template <class _Tp, class _Alloc>
void
_Deque_base<_Tp,_Alloc>::_M_destroy_nodes(_Tp** __nstart, _Tp** __nfinish)
{
for (_Tp** __n = __nstart; __n < __nfinish; ++__n)//逐个释放
_M_deallocate_node(*__n);
} 其中关于_M_create_nodes中主要借助for循环,由于+=,++重载的作用,每一步都是+1的,所以才从__nstart到__nfinish的访问,在外界看来适合一个完全连续的线性表一样.
而对于_M_initialize_map一般用于_Deque_Base部分的构造函数,初始化map和节点,一般是先创建map再创建nodes.
_Deque_base(const allocator_type&, size_t __num_elements)
: _M_map(0), _M_map_size(0), _M_start(), _M_finish() {
_M_initialize_map(__num_elements);
}
template <class _Tp, class _Alloc>
void
_Deque_base<_Tp,_Alloc>::_M_initialize_map(size_t __num_elements)
{
size_t __num_nodes =
__num_elements / __deque_buf_size(sizeof(_Tp)) + 1;
_M_map_size = max((size_t) _S_initial_map_size, __num_nodes + 2);
_M_map = _M_allocate_map(_M_map_size);//创建一份map
_Tp** __nstart = _M_map + (_M_map_size - __num_nodes) / 2;//计算出map上起始的指针
_Tp** __nfinish = __nstart + __num_nodes;//计算出map上末尾的指针
__STL_TRY {
_M_create_nodes(__nstart, __nfinish);//对_M_create_nodes的封装
}
__STL_UNWIND((_M_deallocate_map(_M_map, _M_map_size),
_M_map = 0, _M_map_size = 0));
_M_start._M_set_node(__nstart);
_M_finish._M_set_node(__nfinish - 1);
_M_start._M_cur = _M_start._M_first;
_M_finish._M_cur = _M_finish._M_first +
__num_elements % __deque_buf_size(sizeof(_Tp));
}下面来分析一下push_back,push_front的内部实现.
void push_back(const value_type& __t) {//这里列举有参数的版本了.
if (_M_finish._M_cur != _M_finish._M_last - 1) {//这个时候是不要扩容的情况
construct(_M_finish._M_cur, __t);//在cur所指的内存空间上构造一个元素即可.
++_M_finish._M_cur;//移动cur节点.
}
else
_M_push_back_aux(__t);//这个指的是需要内存扩容的情况.
}
void push_front(const value_type& __t) {//其实现和上面的大同小异.
if (_M_start._M_cur != _M_start._M_first) {
construct(_M_start._M_cur - 1, __t);
--_M_start._M_cur;
}
else
_M_push_front_aux(__t);
}下面来分析_M_push_front_aux,_M_push_front,分析一下其内存扩容的机制.
在这里以_M_push_front为例:
template <class _Tp, class _Alloc>
void deque<_Tp,_Alloc>::_M_push_front_aux(const value_type& __t)
{
value_type __t_copy = __t;
_M_reserve_map_at_front();//如果是back相关的,这里将会是_M_reserve_map_at_back,
*(_M_start._M_node - 1) = _M_allocate_node();//在新的缓冲区中分配node
__STL_TRY {
_M_start._M_set_node(_M_start._M_node - 1);//更新finish,start,map
_M_start._M_cur = _M_start._M_last - 1;//更新cur
construct(_M_start._M_cur, __t_copy);//再此地址构造其值
}
__STL_UNWIND((++_M_start, _M_deallocate_node(*(_M_start._M_node - 1))));
} 在这里可以发现,对于首部所扩充出的内存空间,这块空间在使用时并不是从“start”开始使用的,而是从“last”开始使用,内存使用的方向是反方向的.而相比之下,在末尾的操作是从start开始的.
而新的缓冲区是怎么扩充来的呢?主要看_M_reserve_map_at_back,_M_reserve_map_at_front.其实现如下:
void _M_reserve_map_at_back (size_type __nodes_to_add = 1) {//关于参数,一般在调用时都是用的默认的1.
if (__nodes_to_add + 1 > _M_map_size - (_M_finish._M_node - _M_map))//如果尾部空间不足
_M_reallocate_map(__nodes_to_add, false);//拷贝旧的,释放原来的.
}
void _M_reserve_map_at_front (size_type __nodes_to_add = 1) {
if (__nodes_to_add > size_type(_M_start._M_node - _M_map))//头部空间不足.
_M_reallocate_map(__nodes_to_add, true);
}简单来说,当出现map的重新分配时,会讲旧的map内容拷贝,原有的map释放.在这个过程中,会有Map地址的转换,而相应的start,finish也会有相应的调整.
在最后,梳理一下内存管理与构造相关的模块:
- 在
_Deque_Base中,会有两种分配器(map和node),及其allocate,deallocate的封装.这些接口,被用于deque的构造函数,以及一些需要创建元素或者map的操作. _M_create_nodes等创建和销毁元素的函数,一方面是基于allocate,deallocate等实现的,另一方面,接住了因重载+=,++等运算符,所带来的“连续内存空间假象”,因此可以在nstart到nfinish之间进行操作._Deque_Base部分的构造函数,除了几个指针的初始化,还需要_M_initialize_map,建立初始的空间,即一定的map和node.push_back和push_front在关于内存的使用和扩充上是反方向的.其中在需要内存扩充时,调用_M_push_back_aux,_M_push_front_aux,这两个函数先预留出在首部或者尾部的map,然后调整指针,构造新元素.- 关于
map相关的内容扩容,体现在_M_reserve_map_at_back,_M_reserve_map_at_front中,需要将旧的map拷贝,然后释放.
d.元素操作的实现
在这里以pop_back,pop_front,clear,erase,insert等为例.
void pop_front() {
if (_M_start._M_cur != _M_start._M_last - 1) {
destroy(_M_start._M_cur);
++_M_start._M_cur;
}
else
_M_pop_front_aux();
}
void pop_back() {
if (_M_finish._M_cur != _M_finish._M_first) {
--_M_finish._M_cur;
destroy(_M_finish._M_cur);
}
else
_M_pop_back_aux();
}在这里,再次体现了操作的对称性,其中_M_pop_back_aux和_M_pop_front_aux也是需要重点关注的.
暂鸽
e.与stack和queue的关系
可以说stack,queue是基于deque实现的,它们是只提供了一部分接口的deque.
queue等效于隐藏了接口push_front和pop_back的deque,而stack等效于隐藏了接口push_front和pop_front的deque.
template <class _Tp, class _Sequence>
class queue {
//......
protected:
_Sequence c;
public:
queue() : c() {}
explicit queue(const _Sequence& __c) : c(__c) {}
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference front() { return c.front(); }
const_reference front() const { return c.front(); }
reference back() { return c.back(); }
const_reference back() const { return c.back(); }
void push(const value_type& __x) { c.push_back(__x); }
void pop() { c.pop_front(); }
};从中可见,很多接口其实在底层是调用了deque的接口.
5.Associative Containers
总体而言,有set和map两类.这些容器的底层实现都是以RB-tree实现的.这有利于获得良好的查询效率.
关联式容器每个数据都有key和value.容器的内部根据键值的某种特定规则放在适当位置.
1) RB-tree
一些关于树的基础知识就不在这里开展叙述.直接从平衡二叉搜索树开始.
平衡二叉搜索树防止的是:有时输入的节点会比较特殊,或者经过插入或者删除后,导致二叉搜索树不够平衡,查询效率会逐渐退化成线性.
关于AVL其核心定义在于:任何节点的左右子树高度相差为1.因此,当有节点变化后,如果违反定义,就会采取一些方法处理,分为单旋和双旋.
下面简要地说明一些RB-tree的原理,并且分析在SGI STL中的实现.
但无论怎样,都不要忘了,它始终是二叉搜索树!
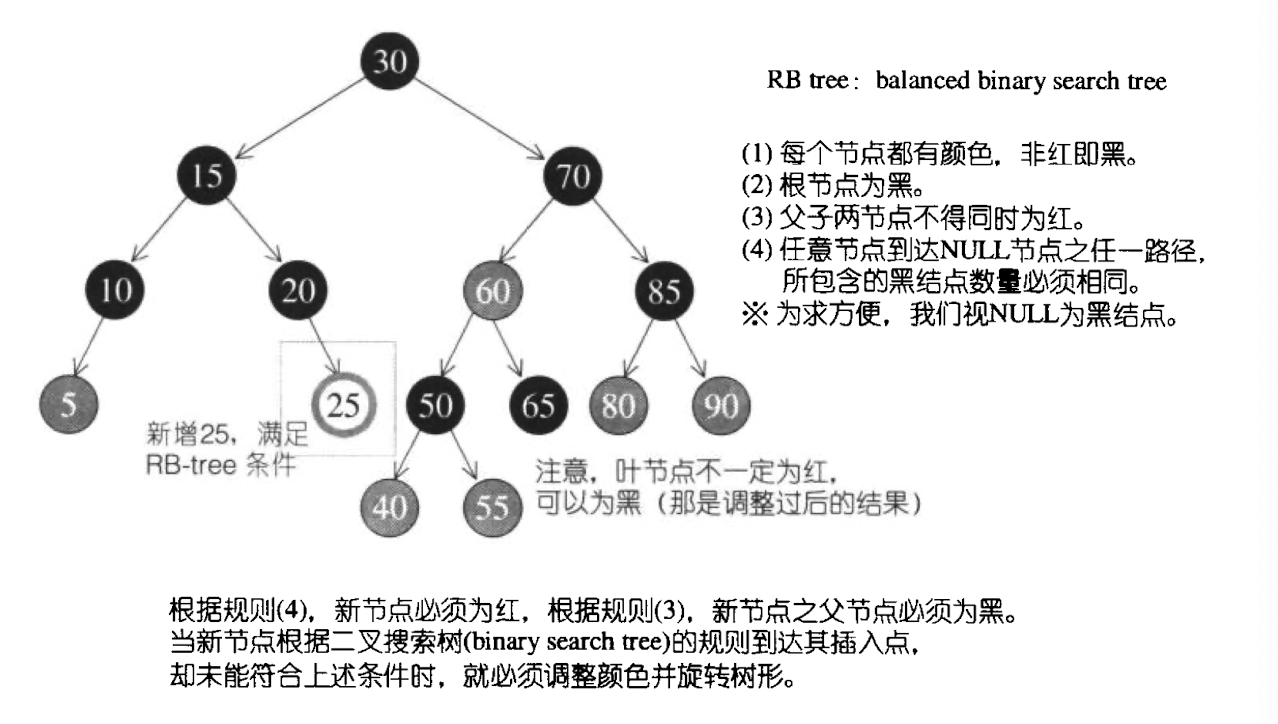
当违背了规定时,仍然需要旋转的方法实现调整.
其中规则3是重点,也是维护操作的重点所在.
a.插入节点
有一个前提需要强调,也就是新插入的节点为红色.
首先,可以思考到的是,如果新插入一个新的节点时,P本身就是黑的,那么这次操作就不要调整.所以下面这几个情况,有一个共同特征,就是P都是红色.
当有一个新的节点插入时,主要考虑4种情况:
- S为黑且X为外侧输入,对此情况先对P,G做单旋,在更改P,G颜色.
- 如果S为黑,X为内侧插入,先对P,X做一次单旋转,并且更改G,X颜色.然后对G做一次单旋转.
- 如果S为红,X为外侧插入,对此情况先对P,G做一次单旋,并且改变X的颜色,如果GG是黑色就已经完成.
- 这一种情况,就是上一种情况中GG时红色的情况.这个时候需要递归向上.
简而言之,其算法,将新的节点作为红节点,先按照普通的搜索树的规则插入,如果违背规则,其依据的维度有:(外侧,父节点颜色,伯父节点颜色).然后进行旋转调整,并调整颜色.
由于情况四,如果一直向上递归,就会造成低效,所以使用一种top-down procedure的方法进行改良.
这种方法就是:当有一个新的节点插入时,将root到此新节点的路径上,如果一个节点的两个子节点为红色,就将两个子节点改为黑色,它自己为红.
也就是说,尽可能避免这种情况:
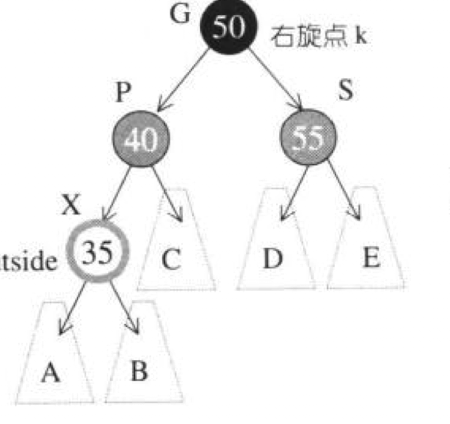
这种情况,也就是上面列举的3和4容易发生的情况.
b.数据结构实现
节点和前面设计的很多数据结构一样,是分为两层的,一层为_Rb_tree_node_base,另一层为_Rb_tree_node,后者继承了前者.
首先下面是_Rb_tree_node_base.
struct _Rb_tree_node_base
{
typedef _Rb_tree_Color_type _Color_type;
typedef _Rb_tree_node_base* _Base_ptr;
_Color_type _M_color; // 节点颜色,非红即黑,是一个bool类型的变量
_Base_ptr _M_parent; // 父节点,用于向上回溯的需要
_Base_ptr _M_left; // 左节点
_Base_ptr _M_right; // 右节点
static _Base_ptr _S_minimum(_Base_ptr __x)//为获取极值提供了巨大的方便.
{
while (__x->_M_left != 0) __x = __x->_M_left;//一直向左递归
return __x;
}
static _Base_ptr _S_maximum(_Base_ptr __x)
{
while (__x->_M_right != 0) __x = __x->_M_right;//一直向右递归
return __x;
}
};其代码还是比较简单的.总结而言,base部分和list_node的base部分有类似之处,它们都包含了节点的指针部分.
而对于_Rb_tree_node的部分.如下定义.
template <class _Value>
struct _Rb_tree_node : public _Rb_tree_node_base
{
typedef _Rb_tree_node<_Value>* _Link_type;
_Value _M_value_field; // 节点值
};这一部分对于base之外的部分,增加一个值域,也就是该节点的值.
下面介绍关于RB-tree的定义,也是分为两层的,首先是_Rb_tree_base,这一部分的内容可以分为:
- 核心的数据成员:
_Rb_tree_node<_Tp>* _M_header.一个指向节点的指针,类似于list中的虚头节点. - 基本的构造与析构函数.这一部分是基于分配器实现的,与此类中分配相关的定义有紧密的联系.
- 分配器相关的定义与操作.
下面结合代码进行分析:
template <class _Tp, class _Alloc>
struct _Rb_tree_base
{
typedef _Alloc allocator_type;
allocator_type get_allocator() const { return allocator_type(); }
//返回分配器的类型
_Rb_tree_base(const allocator_type&) //是对于分配器_M_get_node的简单封装
: _M_header(0) { _M_header = _M_get_node(); }
~_Rb_tree_base() { _M_put_node(_M_header); }
protected:
_Rb_tree_node<_Tp>* _M_header;//这个是核心的数据成员,也就是指向根节点的指针.
typedef simple_alloc<_Rb_tree_node<_Tp>, _Alloc> _Alloc_type;
_Rb_tree_node<_Tp>* _M_get_node()//调用分配器中的allcator的分配空间,对allocate直接的封装,用来分配一个节点.
{ return _Alloc_type::allocate(1); }
void _M_put_node(_Rb_tree_node<_Tp>* __p)//deallocate的直接封装,用来释放一个节点
{ _Alloc_type::deallocate(__p, 1); }
};所以总体来看,与分配有关的操作,主要是简单地对于allocate和deallocate进行的简单的封装,并且提供给构造函数和析构函数调用,这里的构造函数,会将分配分配内存空间的指针返回给_M_header,关于_M_header,其父节点指向红黑树的根节点,左子节点指向最左端的节点,右子节点指向最右端的节点.如下所示:
_Link_type& _M_root() const
{ return (_Link_type&) _M_header->_M_parent; }
_Link_type& _M_leftmost() const
{ return (_Link_type&) _M_header->_M_left; }
_Link_type& _M_rightmost() const
{ return (_Link_type&) _M_header->_M_right; }而对于_Rb_tree这一部分,其代码实现比较复杂,代码很长.所以只摘取核心的部分进行分析.
c.RB-tree iterator
提到迭代器,其类型为双向迭代器,其成员访问与操作与list是非常相似的.也可以说,其迭代器是指向树节点的指针.
其实现方式上,仍然是两层结构.
struct _Rb_tree_base_iterator
{
typedef _Rb_tree_node_base::_Base_ptr _Base_ptr;//指向节点的指针
typedef bidirectional_iterator_tag iterator_category; // 双向迭代器
typedef ptrdiff_t difference_type;
_Base_ptr _M_node; //这是一个指向节点的指针
// 供 operator++() 调用
void _M_increment(){....}
// 供 operator--() 调用
void _M_decrement() {.....}
};其中定义主要是,定义好iterator_category和difference_type.提供了两个函数,供后来的++和--使用.相比线性的数据结构,树形的数据结构在++,--上的区别又是什么呢?其前进和后退是遵照二叉搜索树的节点排列法则的.
void _M_increment()//移动到右子树节点的最左叶.或者
{
if (_M_node->_M_right != 0) { // 如果有右子节点,先进入右子树,然后一直向左走
_M_node = _M_node->_M_right;
while (_M_node->_M_left != 0)
_M_node = _M_node->_M_left;//这样可以确定,这样最终到达的节点就是大于该节点中的最小的一个
}
else {
_Base_ptr __y = _M_node->_M_parent; // 没有右子节点,找其父节点
while (_M_node == __y->_M_right) { // 当该节点为其父节点的右子节点,就一直向上找父节点
_M_node = __y;
__y = __y->_M_parent;
}
if (_M_node->_M_right != __y)//如果此时的右子节点不等于此时的父节点
_M_node = __y;
}
}
// 供 operator--() 调用
void _M_decrement()
{ // 红色节点,父节点的父节点等于自己
if (_M_node->_M_color == _S_rb_tree_red &&
_M_node->_M_parent->_M_parent == _M_node)
_M_node = _M_node->_M_right;
else if (_M_node->_M_left != 0) { // 找出 node 的左子树最大值
_Base_ptr __y = _M_node->_M_left;
while (__y->_M_right != 0)
__y = __y->_M_right;
_M_node = __y;
}
else {
_Base_ptr __y = _M_node->_M_parent;
while (_M_node == __y->_M_left) {
_M_node = __y;
__y = __y->_M_parent;
}
_M_node = __y;
}
}关于_M_increment,如果有右节点,就向右走并且一直递归到左子树,如果没有右子节点,就从父节点向上遍历,如果找到一个本身是一个右子节点就一直递归.
关于_M_decrement.
为什么要将这两个函数定义为这个呢?有什么用呢?
在_Rb_tree_iterator中,
template <class _Value, class _Ref, class _Ptr>
struct _Rb_tree_iterator : public _Rb_tree_base_iterator
{
typedef _Value value_type;
typedef _Ref reference;
typedef _Ptr pointer;
typedef _Rb_tree_iterator<_Value, _Value&, _Value*>
iterator;
typedef _Rb_tree_iterator<_Value, const _Value&, const _Value*>
const_iterator;
typedef _Rb_tree_iterator<_Value, _Ref, _Ptr>
_Self;
typedef _Rb_tree_node<_Value>* _Link_type;
_Rb_tree_iterator() {}
_Rb_tree_iterator(_Link_type __x) { _M_node = __x; }
_Rb_tree_iterator(const iterator& __it) { _M_node = __it._M_node; }
reference operator*() const { return _Link_type(_M_node)->_M_value_field; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
// RB-tree 迭代器 ++,-- 操作
_Self& operator++() { _M_increment(); return *this; }
_Self operator++(int) {
_Self __tmp = *this;
_M_increment();
return __tmp;
}
_Self& operator--() { _M_decrement(); return *this; }
_Self operator--(int) {
_Self __tmp = *this;
_M_decrement();
return __tmp;
}
};虽然这些代码看起来挺长的,但是实际上没有太多难以理解的东西,所以也就不说太多了.
最终我们可以概括,迭代器和节点的关系是这样的·.
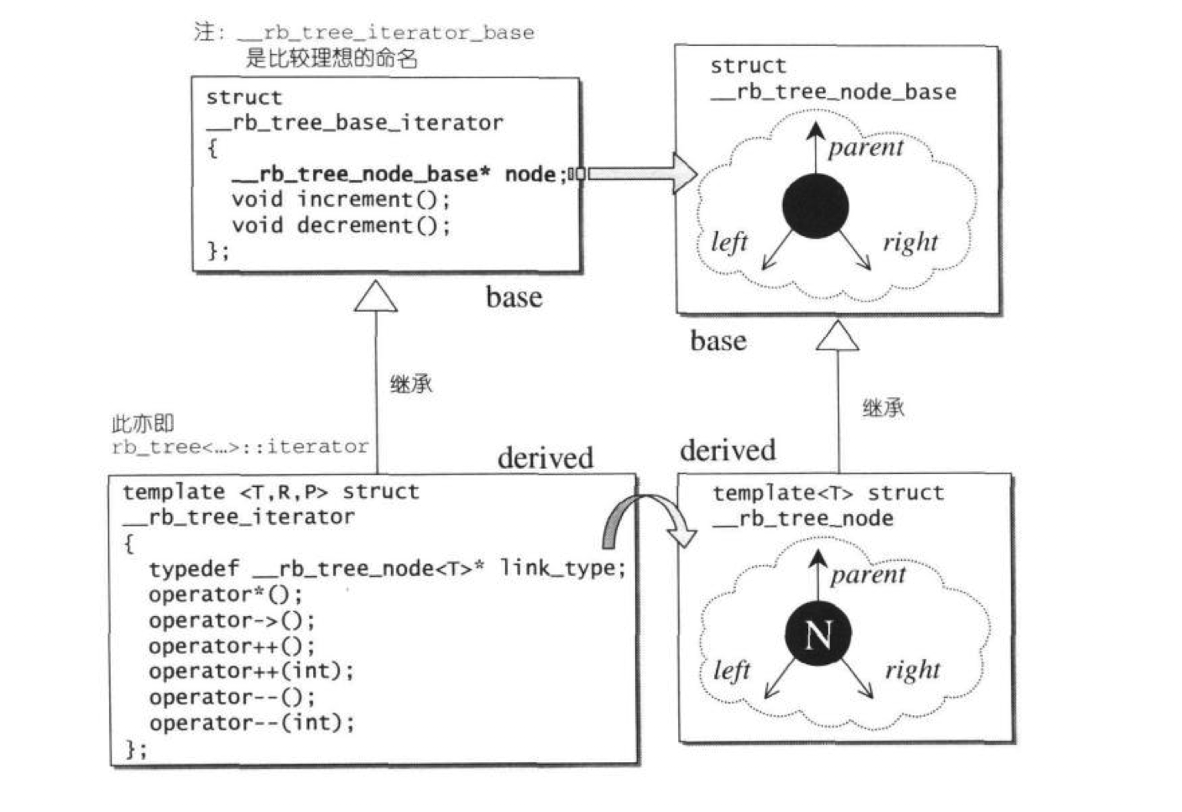
总体来说,其迭代器主要是一个指向节点基类的指针,然后围绕着指针展开重载++,--,*,->等运算符.其中还有最基本的构造函数.
d.内存管理与构造
e.元素操作
2) set
红黑树的实现,主要是为set和map服务的.
set的特定就是,对于加入或者删除的元素都会进行自动地排序,map是k-v的,而set的key和value是一体的.
set的元素值不能修改的.其迭代器类型是constant iterators.
template <class _Key, class _Compare, class _Alloc>
class set {
//......
public:
typedef _Key key_type;
typedef _Key value_type;
typedef _Compare key_compare;
typedef _Compare value_compare;
private:
typedef _Rb_tree<key_type, value_type,
_Identity<value_type>, key_compare, _Alloc> _Rep_type;
_Rep_type _M_t; // red-black tree representing set在上面的这部分代码中可以发现,其内部有一个_Rb_tree,因此可以说是对红黑树的一层封装.其中key_type,value_type是一种数据类型.所以这体现key和value是一体的.
除此之外,关于set的迭代器,指针,分配器等,都是借助_Rb_tree的迭代器实现的.我们可以发现,关于set向外所开放的指针,迭代器,引用等,都是const类型的,不允许我们对于某个节点的值进行修改.
public:
typedef typename _Rep_type::const_pointer pointer;
typedef typename _Rep_type::const_pointer const_pointer;
typedef typename _Rep_type::const_reference reference;
typedef typename _Rep_type::const_reference const_reference;
typedef typename _Rep_type::const_iterator iterator;
typedef typename _Rep_type::const_iterator const_iterator;
typedef typename _Rep_type::const_reverse_iterator reverse_iterator;
typedef typename _Rep_type::const_reverse_iterator const_reverse_iterator;
typedef typename _Rep_type::size_type size_type;
typedef typename _Rep_type::difference_type difference_type;
typedef typename _Rep_type::allocator_type allocator_type;而在构造方面,主要是对于内部_Rb_tree的初始化.
set() : _M_t(_Compare(), allocator_type()) {}
explicit set(const _Compare& __comp,
const allocator_type& __a = allocator_type())//构造函数的主要参数是比较器和分配器.
: _M_t(__comp, __a) {}下面来分析一下,set相关的操作的实现.总体来说,这些操作基本上是调用的_Rb_tree中的操作.对于这些操作,不再一一叙述,主要分析一下关于insert的部分,set的插入操作有一个重要的特征,就是插入的元素具有唯一性.
iterator insert(iterator __position, const value_type& __x) {
typedef typename _Rep_type::iterator _Rep_iterator;
return _M_t.insert_unique((_Rep_iterator&)__position, __x);
}
void insert(const_iterator __first, const_iterator __last) {
_M_t.insert_unique(__first, __last);
}
void insert(const value_type* __first, const value_type* __last) {
_M_t.insert_unique(__first, __last);
}可以发现,基本上都是基于insert_unique实现的,这个函数的实现如下:
template <class _Key, class _Value, class _KeyOfValue,
class _Compare, class _Alloc>
pair<typename _Rb_tree<_Key,_Value,_KeyOfValue,_Compare,_Alloc>::iterator,
bool>
_Rb_tree<_Key,_Value,_KeyOfValue,_Compare,_Alloc>
::insert_unique(const _Value& __v)
{
_Link_type __y = _M_header;//获取header
_Link_type __x = _M_root();//获取根节点
bool __comp = true;//比较器的flag,再此以小于为例,进行分析
while (__x != 0) {//寻找插入点
__y = __x;
__comp = _M_key_compare(_KeyOfValue()(__v), _S_key(__x));
__x = __comp ? _S_left(__x) : _S_right(__x);//如果__v < __x就向左递归,否则向右.
}
iterator __j = iterator(__y);
if (__comp)
if (__j == begin())
return pair<iterator,bool>(_M_insert(__x, __y, __v), true);
else
--__j;
if (_M_key_compare(_S_key(__j._M_node), _KeyOfValue()(__v)))
return pair<iterator,bool>(_M_insert(__x, __y, __v), true);
return pair<iterator,bool>(__j, false);
}所以总的来说,重点把握这几个特点:
- key和value一体.
- 不可对某个节点的值,进行修改.
- 插入的节点,其key具有唯一性.
3) map
map是一种k-v存储的数据结构,其元素类型是pair,所以还需要简单了解一下pair的实现.其中first对应key,second对应value.
template <class _T1, class _T2>
struct pair {
typedef _T1 first_type;
typedef _T2 second_type;
_T1 first;
_T2 second;
pair() : first(_T1()), second(_T2()) {}
pair(const _T1& __a, const _T2& __b) : first(__a), second(__b) {}
#ifdef __STL_MEMBER_TEMPLATES
template <class _U1, class _U2>
pair(const pair<_U1, _U2>& __p) : first(__p.first), second(__p.second) {}
#endif
};在map中,也是有一个红黑树,相比于set,主要是value_type上的不同.对于map来说,对于其节点,也是键值不能修改,但是value是可以进行修改的.
public:
// requirements:
__STL_CLASS_REQUIRES(_Tp, _Assignable);
__STL_CLASS_BINARY_FUNCTION_CHECK(_Compare, bool, _Key, _Key);
// typedefs:
typedef _Key key_type;
typedef _Tp data_type;
typedef _Tp mapped_type;
typedef pair<const _Key, _Tp> value_type; //每一个元素类型是一个pair
typedef _Compare key_compare;
private:
typedef _Rb_tree<key_type, value_type,
_Select1st<value_type>, key_compare, _Alloc> _Rep_type;
_Rep_type _M_t;关于迭代器相关的typedef如下所示:
public:
typedef typename _Rep_type::pointer pointer;
typedef typename _Rep_type::const_pointer const_pointer;
typedef typename _Rep_type::reference reference;
typedef typename _Rep_type::const_reference const_reference;
typedef typename _Rep_type::iterator iterator;
typedef typename _Rep_type::const_iterator const_iterator;
typedef typename _Rep_type::reverse_iterator reverse_iterator;
typedef typename _Rep_type::const_reverse_iterator const_reverse_iterator;
typedef typename _Rep_type::size_type size_type;
typedef typename _Rep_type::difference_type difference_type;
typedef typename _Rep_type::allocator_type allocator_type;其中和set最大的不同在于,map不仅仅开放了const类型的迭代器,指针,引用等.这在此体现了map在修改节点上与set的差别,这使得用户可以修改其value.
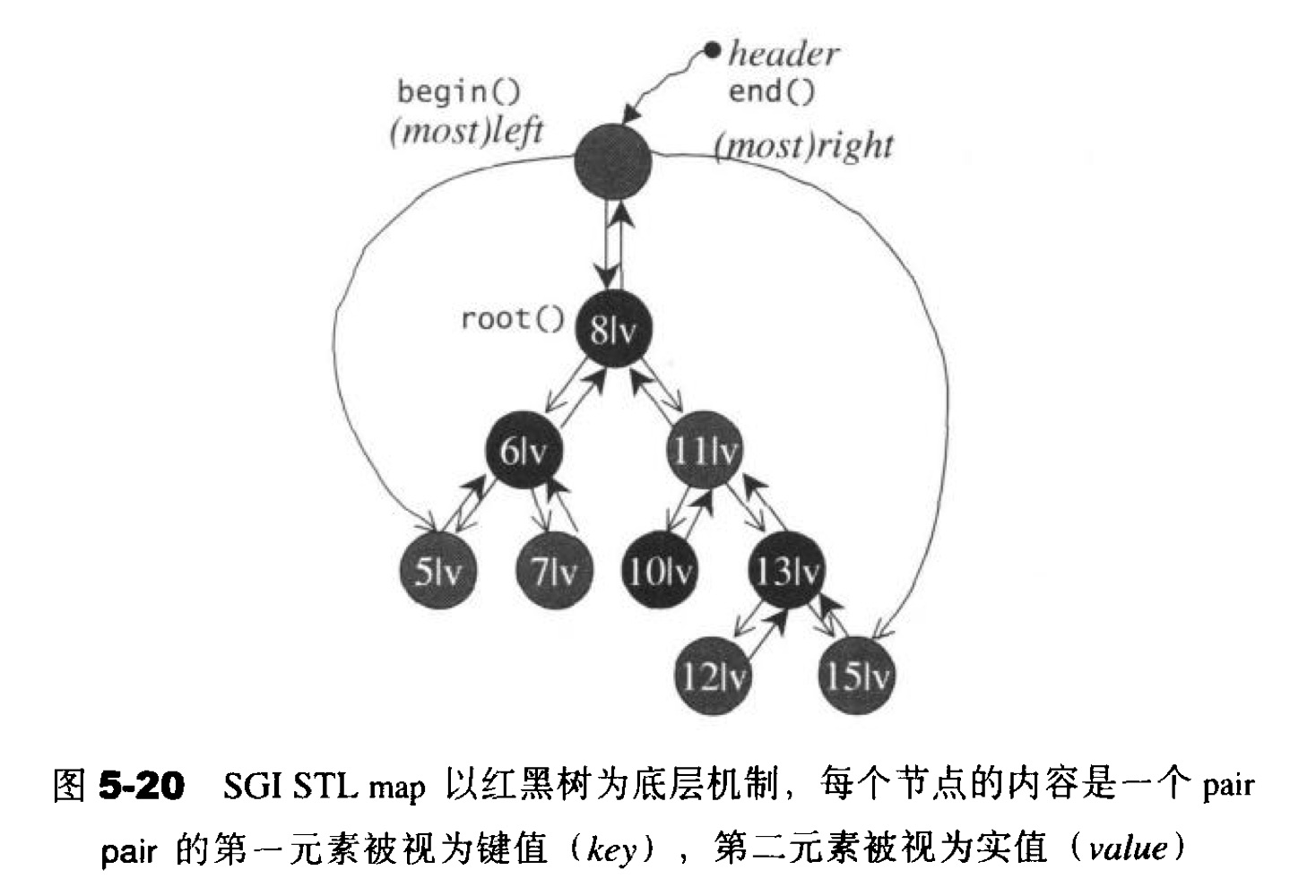
关于map的insert相关的操作,同样用到了insert_unique.确保插入时,避免键值的重复.
6.Algorithms
STL中常见的算法有:排序,查找以及删除,复制,比较等.
特定的算法往往是用于特性的容器.
我们在设计算法时,一个重要的目标在于尽可能地适用于各种数据结构.为此,仅仅借助template的泛化是有有限的,就如下来说:
template<typename T>
T* find(T *begin,T *end,const T &value){
while(begin != end && *begin != value)
++begin;
return begin;
}在上述实现中,其实还不足以泛化到很多容器,对于一般的像vector这样的数据结构或许可以,但是如果begin,end属于list,deque等其他数据结构,那么这种遍历方式将会失效.这里就可以借助迭代器来实现,所以说STL中算法的泛化很大程度上得益于迭代器的设计与运用.所以采取迭代器的实现如下,大大提高算法的泛化程度.
因为迭代器在这里可以算是在裸指针之上的一种中间层,这个中间层可以对外屏蔽++,--等操作的细节,进而可以被算法调用.
template <class _InputIter, class _Tp>
inline _InputIter find(_InputIter __first, _InputIter __last,
const _Tp& __val,
input_iterator_tag){
while (__first != __last && !(*__first == __val))
++__first;
return __first;
}下面来结合一些具体的例子,分析算法的实现.
1) <stl_numeric.h>
这一部分,主要涉及到的函数有:accumulate, adjacent_difference,inner_product,partial_sum等,这些算法在实现上,其基本思路是一致的,即以迭代器作为操作容器中数据的桥梁,迭代器所定义的++,--,*运算符屏蔽了容器内部的细节.
除此之外,这些算法还不止有一个版本,往往有两个,一个是参数中不含有仿函数的,一种是有的.对比如下:
template <class _InputIterator, class _Tp>
_Tp accumulate(_InputIterator __first, _InputIterator __last, _Tp __init)
{
__STL_REQUIRES(_InputIterator, _InputIterator);
for ( ; __first != __last; ++__first)
__init = __init + *__first;//没有仿函数的版本中,直接使用的是加法
return __init;
}
template <class _InputIterator, class _Tp, class _BinaryOperation>
_Tp accumulate(_InputIterator __first, _InputIterator __last, _Tp __init,
_BinaryOperation __binary_op)
{
__STL_REQUIRES(_InputIterator, _InputIterator);
for ( ; __first != __last; ++__first)
__init = __binary_op(__init, *__first);//这里的运算采用的是仿函数.
return __init;
}
//这里是应用时,使用仿函数和不使用的区别.
accumulate(iv.begin(),iv.end(),0) //0+1+2+3+4+5
accumulate(iv.begin(),iv.end(),0,minux<int>()) //0-1-2-3-4-52)<stl_algobase.h>
1)主要算法
首先说明一下,其中的主要算法的基本功能:
equal,判断两个序列在区间内是否相等,对于序列2多出来的部分不考虑.fill,fill_n,将区间内填充为某个值.max,min.mismatch,判断两个区间的第一个不匹配点.
在这里关于equal的实现,并没有太多难以理解的地方,仍然是遍历迭代器,并进行比较,两个版本的不同在于,一个借助了!=,另一个版本接住了仿函数来进行比较.在这里如果迭代器中的元素是一种对象,我们在使用equal需要注意的!=的重载问题.
template <class _InputIter1, class _InputIter2>
inline bool equal(_InputIter1 __first1, _InputIter1 __last1,
_InputIter2 __first2) {
__STL_REQUIRES(_InputIter1, _InputIterator);
__STL_REQUIRES(_InputIter2, _InputIterator);
__STL_REQUIRES(typename iterator_traits<_InputIter1>::value_type,
_EqualityComparable);
__STL_REQUIRES(typename iterator_traits<_InputIter2>::value_type,
_EqualityComparable);
for ( ; __first1 != __last1; ++__first1, ++__first2)
if (*__first1 != *__first2)
return false;
return true;
}
template <class _InputIter1, class _InputIter2, class _BinaryPredicate>
inline bool equal(_InputIter1 __first1, _InputIter1 __last1,
_InputIter2 __first2, _BinaryPredicate __binary_pred) {
__STL_REQUIRES(_InputIter1, _InputIterator);
__STL_REQUIRES(_InputIter2, _InputIterator);
for ( ; __first1 != __last1; ++__first1, ++__first2)
if (!__binary_pred(*__first1, *__first2))
return false;
return true;
}关于fill的实现,其基本思路也是一样的,需要注意的是其拷贝操作是借助assignment实现的.
mismatch的实现,则是遍历迭代器,其中会用到数据的==.最终会返回一个pair.
关于iter_swap的实现:
template <class _ForwardIter1, class _ForwardIter2, class _Tp>
inline void __iter_swap(_ForwardIter1 __a, _ForwardIter2 __b, _Tp*) {
_Tp __tmp = *__a;
*__a = *__b;
*__b = __tmp;
}
template <class _ForwardIter1, class _ForwardIter2>
inline void iter_swap(_ForwardIter1 __a, _ForwardIter2 __b) {
__STL_REQUIRES(_ForwardIter1, _Mutable_ForwardIterator);
__STL_REQUIRES(_ForwardIter2, _Mutable_ForwardIterator);
__STL_CONVERTIBLE(typename iterator_traits<_ForwardIter1>::value_type,
typename iterator_traits<_ForwardIter2>::value_type);
__STL_CONVERTIBLE(typename iterator_traits<_ForwardIter2>::value_type,
typename iterator_traits<_ForwardIter1>::value_type);
__iter_swap(__a, __b, __VALUE_TYPE(__a));
}其中需要用到__VALUE_TYPE()因为交换时,需要一个临时变量,这个变量的定义需要知道其类型,这个时候可以借助迭代器中所表明的数据类型.
#define __VALUE_TYPE(__i) value_type(__i)
template <class _Tp, class _Distance>
inline _Tp* value_type(const input_iterator<_Tp, _Distance>&)
{ return (_Tp*)(0); }其实在此可以发现,fill,equal,mismatch等算法,对其数据类型是有一定的要求的,需要考虑一些运算符是否有意义,就比如说fill中的assignment,equal中的!=等.这是我们在设计对象时,应该注意的地方.
7.Functions
1)仿函数概述
仿函数又被称为函数对象,对于调用者来说,可以像函数一样被调用,对于被调用者来说,其实利用了对象中重载的function call operator,也就是operator().
在STL的许多算法中,一般有两个版本,参数提供仿函数和不提供仿函数的,前者可以由用户指定仿函数进而影响算法的“策略”.如下所示:
template <class _InputIterator, class _Tp>
_Tp accumulate(_InputIterator __first, _InputIterator __last, _Tp __init)
{
__STL_REQUIRES(_InputIterator, _InputIterator);
for ( ; __first != __last; ++__first)
__init = __init + *__first;//没有仿函数的版本中,直接使用的是加法
return __init;
}
template <class _InputIterator, class _Tp, class _BinaryOperation>
_Tp accumulate(_InputIterator __first, _InputIterator __last, _Tp __init,
_BinaryOperation __binary_op)
{
__STL_REQUIRES(_InputIterator, _InputIterator);
for ( ; __first != __last; ++__first)
__init = __binary_op(__init, *__first);//这里的运算采用的是仿函数.
return __init;
}其中的_BinaryOperation就是仿函数.
仿函数在实现上关键在于,对该对象中operator()的重载.
greater<int> ig;
ig(4,6);//调用该对象的operator().
greater<int> ()(6,4)//产生临时对象,并调用临时对象的operator().仿函数可以有一元,二元之分.
仿函数可配接性的关键在于有相应型别的定义,以typedef的方式实现,这点上类似于迭代器.这使得可以在外边取出一个仿函数对象的某些信息.
其中主要定义了参数和返回值.
如下所示:
template <class _Arg, class _Result>
struct unary_function {
typedef _Arg argument_type;
typedef _Result result_type;
};
template <class _Arg1, class _Arg2, class _Result>
struct binary_function {
typedef _Arg1 first_argument_type;
typedef _Arg2 second_argument_type;
typedef _Result result_type;
}; 如此定义之后,用户再想获取相应型别也是很简单的.
template <class _Predicate>
class binary_negate
: public binary_function<typename _Predicate::first_argument_type,
typename _Predicate::second_argument_type,
bool> {
protected:
_Predicate _M_pred;
public:
explicit binary_negate(const _Predicate& __x) : _M_pred(__x) {}
bool operator()(const typename _Predicate::first_argument_type& __x,
const typename _Predicate::second_argument_type& __y) const
{
return !_M_pred(__x, __y);
}
};2) 算术类,关系类与逻辑类仿函数
在此以源码实现和应用的角度上分析.
算术类中,主要包括+,-,*,/,%,!,前面这些二元运算的仿函数在实现上几乎是一样的.在这里只列举加法为例.
template <class _Tp>
struct plus : public binary_function<_Tp,_Tp,_Tp> {
_Tp operator()(const _Tp& __x, const _Tp& __y) const { return __x + __y; }
};而否定运算是一元运算,其实现如下:
template <class _Tp>
struct negate : public unary_function<_Tp,_Tp>
{
_Tp operator()(const _Tp& __x) const { return -__x; }
};再次验证了,这些在实现上都是对类中operator()的重载而已.
而在应用上,如果是单独应用的话,如下:
plus<int> plusobj;//定义对象.
plusobj(3,5);//调用了对象的operator(),其作用就像函数.
plus<int>() (3,5);//产生临时对象,调用了临时对象的operator().如果应用在STL中一些算法中.比如说:
accmulate(iv.begin(),iv.end(),multiplies<int>());//产生了一个multiplies类型的临时对象在accmulate的底层会调用仿函数对象的operator().
而对于关系型运算和逻辑型运算来说,其中和一般的算数类最大的区别就在于其返回值是固定类型bool的,一般算数类参数和返回值类型一致.关系型运算常见的有:equal_to,not_equal_to,greater.less,greater_equal,less_equal等.
template <class _Tp>
struct equal_to : public binary_function<_Tp,_Tp,bool>
{
bool operator()(const _Tp& __x, const _Tp& __y) const { return __x == __y; }
};
template <class _Tp>
struct logical_and : public binary_function<_Tp,_Tp,bool>
{
bool operator()(const _Tp& __x, const _Tp& __y) const { return __x && __y; }
};3) identity,select,project
暂鸽
8.Adapters
adapters也是一种设计模式,这种设计模式一般用于将一个类的接口转化成用户所希望的接口.
其中常见的分类有:
container adapters,比如说stack,queue都是对deque接口的修饰而成.iterator adapters.
1) container adapters
关于queue和stack就不说太多了,它们很多操作都是对deque的直接封装,或者说他们就是提供了一部分接口的deque.
2) iterator adapters
a. insert iterators
template <class _Container>
class back_insert_iterator {
protected:
_Container* container;//在底层维护了一个容器
public:
typedef _Container container_type;
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
explicit back_insert_iterator(_Container& __x) : container(&__x) {}
back_insert_iterator<_Container>&
operator=(const typename _Container::value_type& __value) {
container->push_back(__value);
return *this;
}
back_insert_iterator<_Container>& operator*() { return *this; }
back_insert_iterator<_Container>& operator++() { return *this; }
back_insert_iterator<_Container>& operator++(int) { return *this; }
};可见其内部有一个指向容器的指针,其核心在于对于assignment的重载,对于assignment的重载即为调用该容器的push_back.
对于++等操作都是没有意义的,和*一样.
如果是front_insert_iterator的话,不是调用的push_back而是push_front.
其中insert_iterator还是比较不同的.
protected:
_Container* container;
typename _Container::iterator iter;
//......
insert_iterator<_Container>&
operator=(const typename _Container::value_type& __value) {
iter = container->insert(iter, __value);
++iter;
return *this;
}除了有一个容器指针外,还有一个该容器的迭代器.
b. reverse iterators
这种迭代器将一般迭代器的移动行为逆转,是从尾到首处理元素的.
用户所使用的rbegin(),rend()就是可以直接使用的反向迭代器接口.
以vector中的有关实现为例:
typedef reverse_iterator<const_iterator, value_type, const_reference,
difference_type> const_reverse_iterator;
typedef reverse_iterator<iterator, value_type, reference, difference_type>
reverse_iterator;
iterator begin() { return _M_start; }
const_iterator begin() const { return _M_start; }
iterator end() { return _M_finish; }
const_iterator end() const { return _M_finish; }
reverse_iterator rbegin()
{ return reverse_iterator(end()); }
const_reverse_iterator rbegin() const
{ return const_reverse_iterator(end()); }
reverse_iterator rend()
{ return reverse_iterator(begin()); }
const_reverse_iterator rend() const
{ return const_reverse_iterator(begin()); }在duque,list等容器中的实现也是这样的,一般是基于正向迭代器的接口实现的.
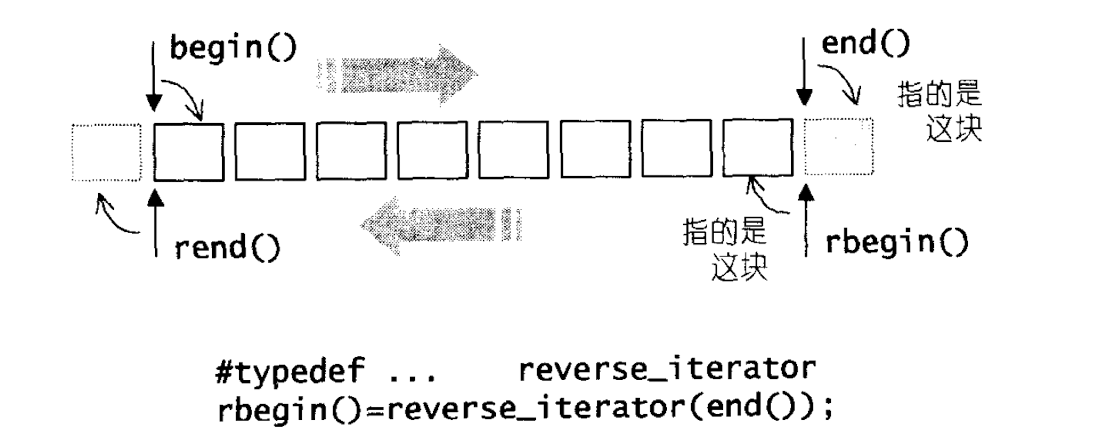
迭代器总是遵循前闭后开的特性,这是需要注意的begin()和rend(),end()和rbegin()所指向的元素不同.
下面分析一下reverse iterator的源代码.
class reverse_bidirectional_iterator {
typedef reverse_bidirectional_iterator<_BidirectionalIterator, _Tp,
_Reference, _Distance> _Self;
protected:
_BidirectionalIterator current;//这里可以体现,逆向迭代器是基于双向迭代器实现的.
public:
typedef bidirectional_iterator_tag iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Tp* pointer;
typedef _Reference reference;
reverse_bidirectional_iterator() {}
explicit reverse_bidirectional_iterator(_BidirectionalIterator __x)
: current(__x) {}
_BidirectionalIterator base() const { return current; }
_Reference operator*() const {
_BidirectionalIterator __tmp = current;
return *--__tmp;
}
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
_Self& operator++() {
--current;
return *this;
}
_Self operator++(int) {
_Self __tmp = *this;
--current;
return __tmp;
}
_Self& operator--() {
++current;
return *this;
}
_Self operator--(int) {
_Self __tmp = *this;
++current;
return __tmp;
}
};从源码中我们可以看出来,其中很多操作是基于_BidirectionalIterator的接口实现的.尤其是++,--,-=,+=等,所以再次体现了adapters能够根据已有接口进行改变,从而提供出用户所希望的接口的作用.
c. stream iterators
将迭代器绑定到istream或者ostream对象上,也就是说stream iterators内会维护指向流对象的指针.
3) function adapters
暂鸽