linux网络编程与系统编程基础
一.基础socket
主要从三个方面:
- socket的地址API,用于标记一端的(ip,port).
- socket的基础功能API:create,listen,read,write等.
- 网路信息API,一般有主机名和ip转换,服务名称和端口转换等API.
1.socket地址API
计算机系统在表示信息时,有大端和小端之分,基本上我们使用的PC都是小端的,但手机或者其他设备未必.所以不同类型的机器如果想要通信如何统一呢?
解决办法就是:总是采用大端法,这是发送方和接收方达成的协议,因此又将大端称为网络字节序
主要有关于字节序的接口如下:
#include<netinet/in.h>
unsigned long int htonl(unsigned long int hostlong);
unsigned short int htons(unsigned short int hostshort);
unsigned long int ntonl(unsigned long int hostlong);
unsigned short int ntonl(unsigned short int hostshort);其中h表示主机字节序,n表示网络字节序.
一般情况下,l表示长的,适合ip地址,s表示短的,适合端口号.
2.socket地址
1) 通用socket
#include<bits/socket.h>
struct sockaddr{
sa_family_t sa_family;//地址组类型,通常与其他协议组对应
char sa_data[14];//存放socket地址值
}
其实14字节的sa_data无法容纳多数协议族的地址值,所以有新的通用sokcet地址结构体.
#include<bits/socket.h>
struct sockaddr_storage{
sa_family_t sa_family;
unsigned long int __ss_align;
char __ss_padding[128-sizeof(__ss_align)];
}2) tcp/ip协议族地址
struct sockaddr_in{
__SOCKADDR_COMMON (sin_);//表示协议族的类型
in_port_t sin_port; /* Port number. */
struct in_addr sin_addr; /* Internet address. */
/* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof (struct sockaddr)
- __SOCKADDR_COMMON_SIZE
- sizeof (in_port_t)
- sizeof (struct in_addr)];
};
struct in_addr{
in_addr_t s_addr;
};
struct sockaddr_in6{
__SOCKADDR_COMMON (sin6_);//表示协议族类型
in_port_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};由此可见,其中最主要的部分,就是内部有一个表示ip地址的结构体,还有一个端口号(一个16位).
一般情况下,在使用时,我们需要转化成sockaddr类型才可以代入到其他API中.
3) IP转换函数
在程序中.对于ip地址的表示适合使用整数.而平时符合人们习惯的是字符串.所以系统提供了一些接口便于转换.
extern in_addr_t inet_addr (const char *__cp) __THROW;//string to int
extern int inet_aton (const char *__cp, struct in_addr *__inp) __THROW;//转化成整型,返回到__inp
extern char *inet_ntoa (struct in_addr __in) __THROW;//int to string其实in_addr_t就是一个32位整数.
3.基本操作函数
1) 基本API
#include<sys/types.h>
#include<sys/socket.h>
int socket (int __domain, int __type, int __protocol) __THROW;
//协议组,服务类型,protocol一般都设置为0.
int bind(int __fd, const struct sockaddr *__addr, socklen_t __len);//绑定某个socket
int listen(int __fd, int __n) __THROW;//n在linux 2.2之后表示的是处于完全连接数量的上限.
int accept(int __fd, struct sockaddr *__restrict__ __addr, socklen_t *__restrict__ __addr_len);//会将请求链接的addr结构体返回到第二个参数中
int connect(int sockfd,const struct sockaddr *serv_addr,socklen_t addrlen);2) 读写
#include<sys/types.h>
#include<sys/socket.h>
//TCP数据读写
ssize_t recv (int __fd, void *__buf, size_t __n, int __flags);//返回值是接受的长度,有时会小于
//期望的长度
ssize_t send (int __fd, const void *__buf, size_t __n, int __flags);//成功写入时返回长度,否则返回-1设置errno
//UDP数据读写
ssize_t sendto(int __fd, const void *__buf, size_t __n, int __flags, const struct sockaddr *__addr, socklen_t __addr_len);//其中的addr是目的地的addr
ssize_t recvfrom(int __fd, void *__restrict__ __buf, size_t __n, int __flags, struct sockaddr *__restrict__ __addr, socklen_t *__restrict__ __addr_len);//其中的addr是源4.地址信息函数
一般适用于我们需要知道一个连接socket的本端和远端的socket地址.使用下面的这个函数解决问题.
#include<sys/socket.h>
int getsockname(int sockfd,struct sockaddr *address,socklen_t *address_len);
int getpeername(int sockfd,struct sockaddr *address,socklen_t *address_len);前者获取的是socket本端的地址,返回到address中,后者获取的远端的,也是返回到address中.
5.socket选项
暂鸽.
二.高级IO函数
主要分为三类:
- 与创建文件有关,pipe和dup等.
- 与读写函数有关,readv/writev,sendfile,mmap等有关.
- 用于控制I/O行为与属性有关,比如fcntl等.
1.pipe和dup
int pipe (int __pipedes[2]) __THROW __wur;//传入一个数组,代表管道的两端
int socketpair(int __domain,int __type,int __protocol,int __fds[2]) __THROW;//便于建立双向管道
int dup (int __fd) __THROW __wur;
int dup2 (int __fd, int __fd2) __THROW;注意默认是阻塞的,如果当前是空的,那么read将会阻塞,如果是满的,那么write也将会阻塞,知道有足够空间.
内部传输的数据和TCP流一样都是字节流,但是其中不同的地方主要在于,应用层能够往TCP连接写入的字节数量取决于对方的接受窗口和滑动窗口.而管道本身是有一个容量限制的(默认是65536).
可使用fcntl来修改管道限制.
对于dup和dup2来说,两者作用相同,前者是返回一个新的文件描述符与给定的fd相同,后者是将两者映射为相同的文件,管道和连接.
三.Linux服务器程序规范与框架
这里涉及到一些模版式的东西:
- linux服务器程序一般以后台进程运行,也称守护进程.
- 有配套的日志系统,至少能够输出到文件.
- 服务器程序一般以某个专门的非root用户身份运行.
- 通常是可配置的,能处理很多命令行选项,甚至有配置文件管理.
- 在启动时会生成一个PID文件并且存入/var/run目录,从而记录该后台的PID.
- 考虑系统资源和限制.
1.日志
现在大多数linux系统使用的是rsyslogd.
其工作体系简而言之:
- 内核通过printk()输出到内核环状buffer,此buffer会映射到文件/proc/kmsg.
- 用户调用syslog()输出到/dev/log(UNIX本地socket).
- rsyslogd或者syslogd接受/proc/kmsg和/dev/log的日志,根据配置文件输出到特定的日志文件/var/log/*.
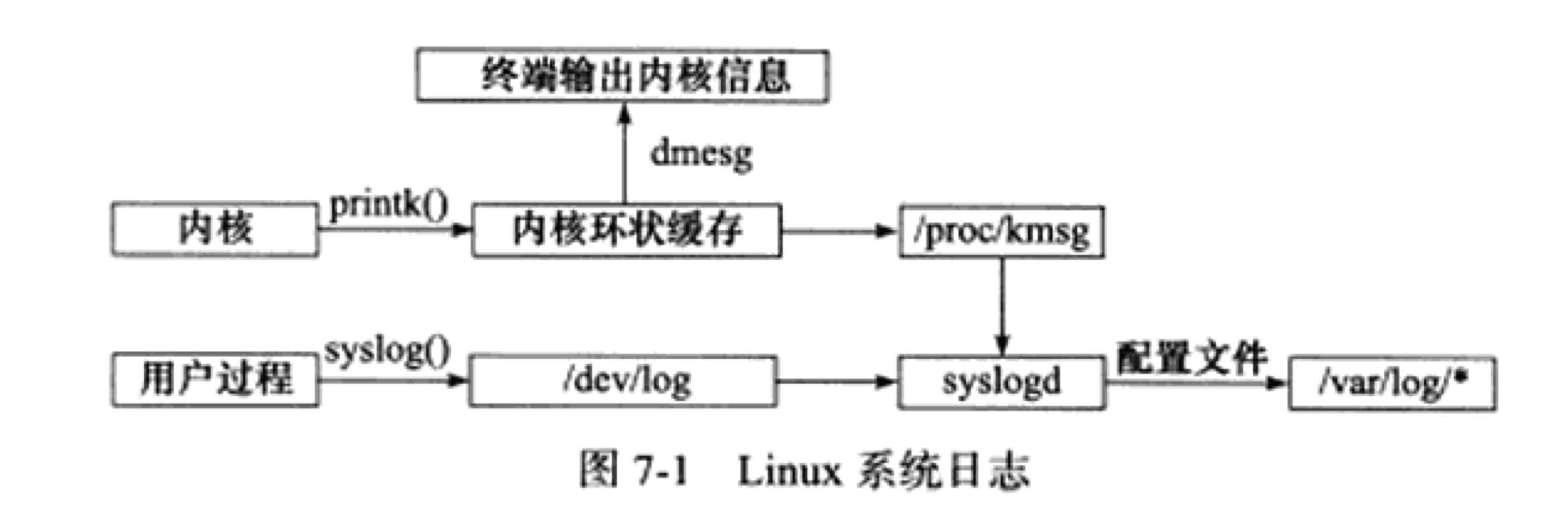
用户进程使用的syslog与守护进程rsyslogd通信.
void syslog (int __pri, const char *__fmt, ...){
__syslog_chk (__pri, __USE_FORTIFY_LEVEL - 1, __fmt, __va_arg_pack ());
}
#define LOG_EMERG 0 /* system is unusable */
#define LOG_ALERT 1 /* action must be taken immediately */
#define LOG_CRIT 2 /* critical conditions */
#define LOG_ERR 3 /* error conditions */
#define LOG_WARNING 4 /* warning conditions */
#define LOG_NOTICE 5 /* normal but significant condition */
#define LOG_INFO 6 /* informational */
#define LOG_DEBUG 7 /* debug-level messages */
void openlog (const char *__ident, int __option, int __facility);
#define LOG_PID 0x01 /* log the pid with each message */
#define LOG_CONS 0x02 /* log on the console if errors in sending */
#define LOG_ODELAY 0x04 /* delay open until first syslog() (default) */
#define LOG_NDELAY 0x08 /* don't delay open */
#define LOG_NOWAIT 0x10 /* don't wait for console forks: DEPRECATED */
#define LOG_PERROR 0x20 /* log to stderr as well */
int setlogmask (int __mask) __THROW;//
void closelog (void);//用于关闭日志.Syslog其中第二个和第三个参数和printf类似用于结构化输出.priority是所谓的设施值和日志级别的按位或.
openlog用于设置syslog的默认行为,其中ident指定的字符串被添加到日志消息的日期和时间之后.logopt对后续的syslog行为进行配置.facility用来修改syslog函数中的默认设施值.
setlogmask通过设置掩码使得,日志级别大于日志掩码的日志信息被忽略.
2.用户信息
一般来说服务器程序会以root身份启动,非root身份运行.
下面代码展示了如何将root用户切换到非root用户.
static bool switch_to_user(uid_t user_id,gid_t gp_id){
if(user_id == 0 && gp_id == 0){//首先保证当前用户不是root
return false;
}
gid_t gid = getgid();
uid_t uid = getuid();
//确保当前用户合法
if((gid != 0 || uid != 0) && (gid != gp_id || uid != user_id)){
return false;
}
if(uid != 0){
return false;
}
//切换到目标用户
if((setgid(gp_id) < 0) || (setgid(user_id) < 0)){
return false;
}
return true;
}一个进程是存在两个用户的:
- UID启动程序的用户ID.
- EUID,设置有效用户的权限.
- EGID:给运行目标程序的组用户提供有效组的权限.
3.其他函数
1)查看资源限制
2)改变目录
#include<unisted.h>
char *getcwd(char *buf,size_t size);//获取当前目录
int chdir(const char *path);//切换到指定的目录4.服务器进程后台化
其核心思想在于创建子进程和关闭父进程.
bool daemonize(){
pid_t pid = fork();
if(pid < 0){
return false;
}else if(pid > 0){
exit(0);//退出父进程
}
umask(0);//设置权限掩码,当进程创建出新文件时,将会是mode & 0777.
pid_t sid = setsid();//称为新回话的首领,并新建一个进程组,其中pgid就是调用进程pid
if(sid < 0){
return false;
}
if((chdir("/")) < 0){
return false;
}
close(STDIN_FILENO);
close(STDOUT_FILENO);
close(STDERR_FILENO);
open("/dev/null",O_RDONLY);
open("/dev/null",O_RDWR);
return true;
}或者有
#include<unistd.h>
int daemon(int nochdir,int noclose);5.服务器编程框架
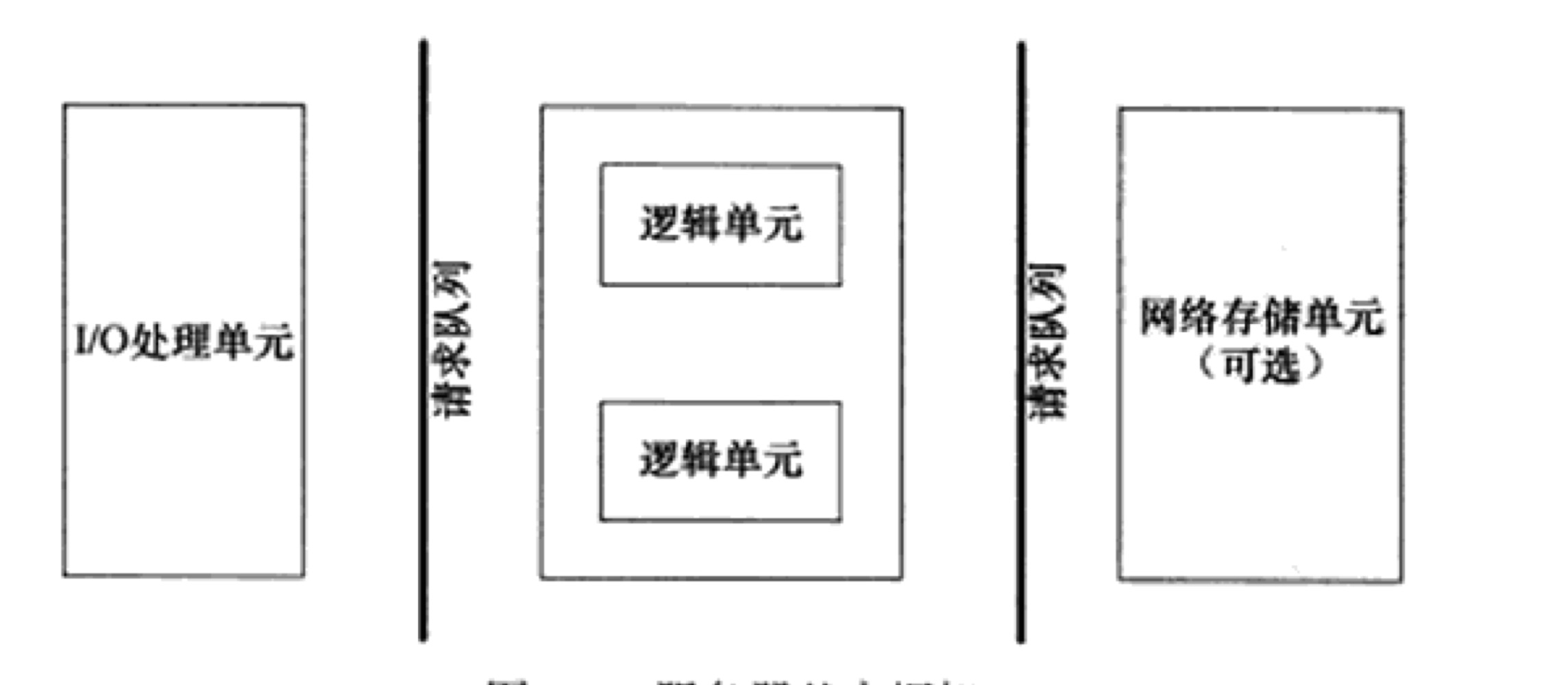
- IO处理单元,等待并接受客户连接,接受客户数据,将服务器响应数据返回给客户端.
- 通常有一个或者多个线程或者进程组成,分析并处理数据,将结果返回给I/O处理单元或者直接发给客户端.
- 网路存储单元包括数据库,缓存和文件.
6.事件处理模式
服务器程序主要处理三类事件:I/O,信号,定时事件.
总体介绍一下:Reactor,Proactor.
1) Reactor
主线程只是监听文件描述符上是否有事件发生,如果有就通知工作线程,不做实质性的处理工作.这里主线程仅仅起到等待就绪和通知的作用.
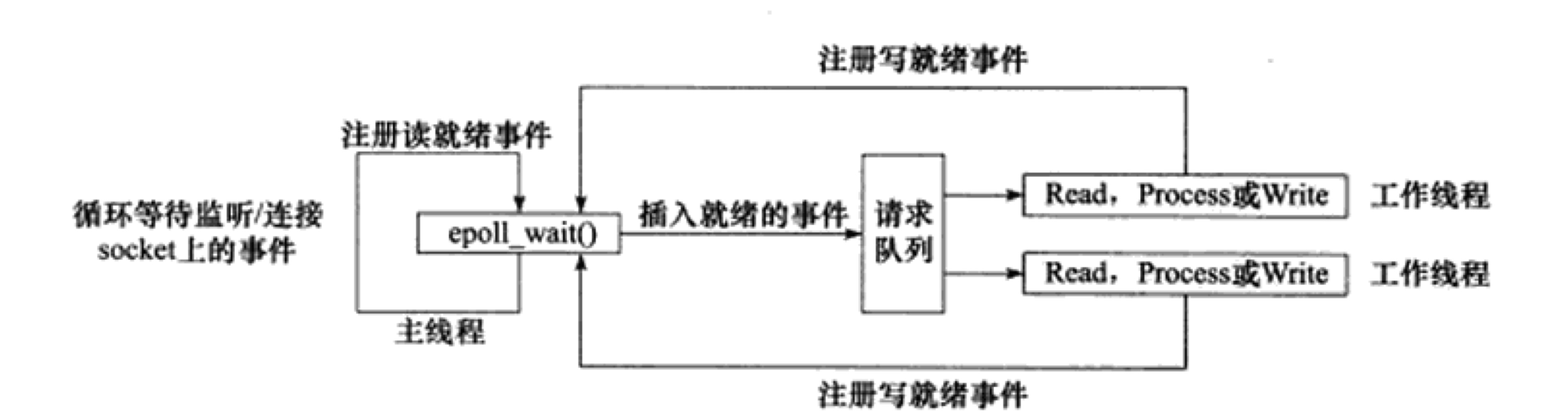
其工作过程简而言之:
- 主线程利用epoll等注册号就绪事件,就绪后将就绪的事件放入到请求队列,这时唤醒一个工作线程.
- 被唤醒的工作线程从socket读取数据,处理请求,借助epoll注册写就绪事件.
- 主线程调用epoll_wait等待可写,就绪后,将可写事件放入请求队列,唤醒某个工作线程,进而进行写操作.
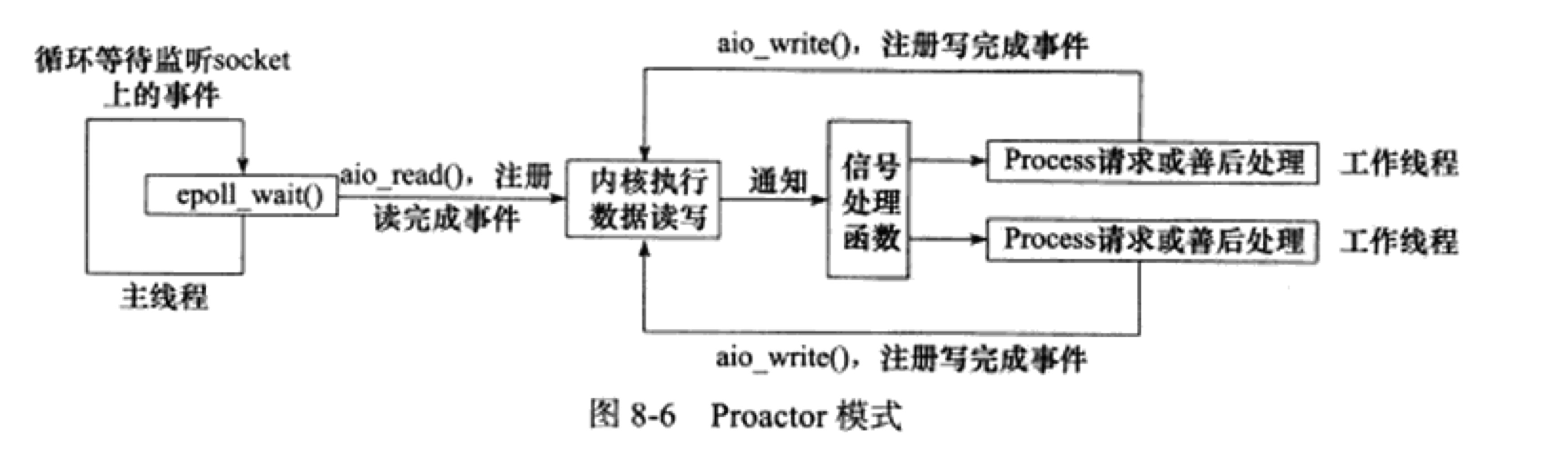
2) Proactor
这种模式将所有I/O操作都交给主线程和内核处理,工作线程仅仅处理业务逻辑.
7.并发模式
8.其他
1) 有限状态机
便于在逻辑单元中实现高效地处理业务.
2) 池
池这个概念的核心思想在于牺牲空间换时间.池是一种预先分配好的资源的集合.
在一般情况下,采用的方式是先创建好一个资源,当结束时释放掉.但是创建和释放的过程会带来较大的开销.采用池的话,直接从池中取出一个已经分配好的资源即可,使用完之后在放回到池中.因此减少了因为分配和释放资源所带来的开销.
在系统编程方面,很多创建资源的操作是需要访问内核的,比如说fork,socket等.而采用池的方式就减少了对内核的访问,因而提高了性能.
常见的池种类有:
- 内存池.
- 连接池.以数据库为例,连接池是实现创建好的服务器与数据库连接的集合,避免了每次访问都需要进行连接的创建和释放.
- 进程或者线程池.当有新的任务请求到来时,无须创建新的线程或者线程(避免fork或者pthread_create),直接从池中取出一个实体即可.
3) 数据复制
尽可能地减少数据的拷贝.多用指针.
4) 上下文切换和锁
并发程序由于多线程或者多进程会存在上下文切换的问题,尤其是对于I/O密集型的服务器来说,使用过多的工作线程会占用大量的CPU时间.所以对每个客户连接都创建一个线程的模式不可取!
如果,线程的数量小于CPU的数量,那么上下文切换就不会带来太大的开销问题.
共享资源往往需要借助锁,但是锁会带来效率低下等问题.如果避免使用锁,就可以带来更少的开销,或者考虑减小锁的粒度.
五.I/O复用
一般用于能够支持同时监听多个socket的情况:
- 客户端同时处理多个socket.
- 客户端处理多个输入和网络连接.
- TCP服务器同时处理和监听socket和连接socket,最最重要.
- 同时处理TCP请求和UDP请求.
- 同时处理多个端口或者多种服务.
虽然看上去同时监听多个文件描述符,但本身是阻塞的,当文件描述符就绪时,如果不采取额外的措施,就只能串性地处理.
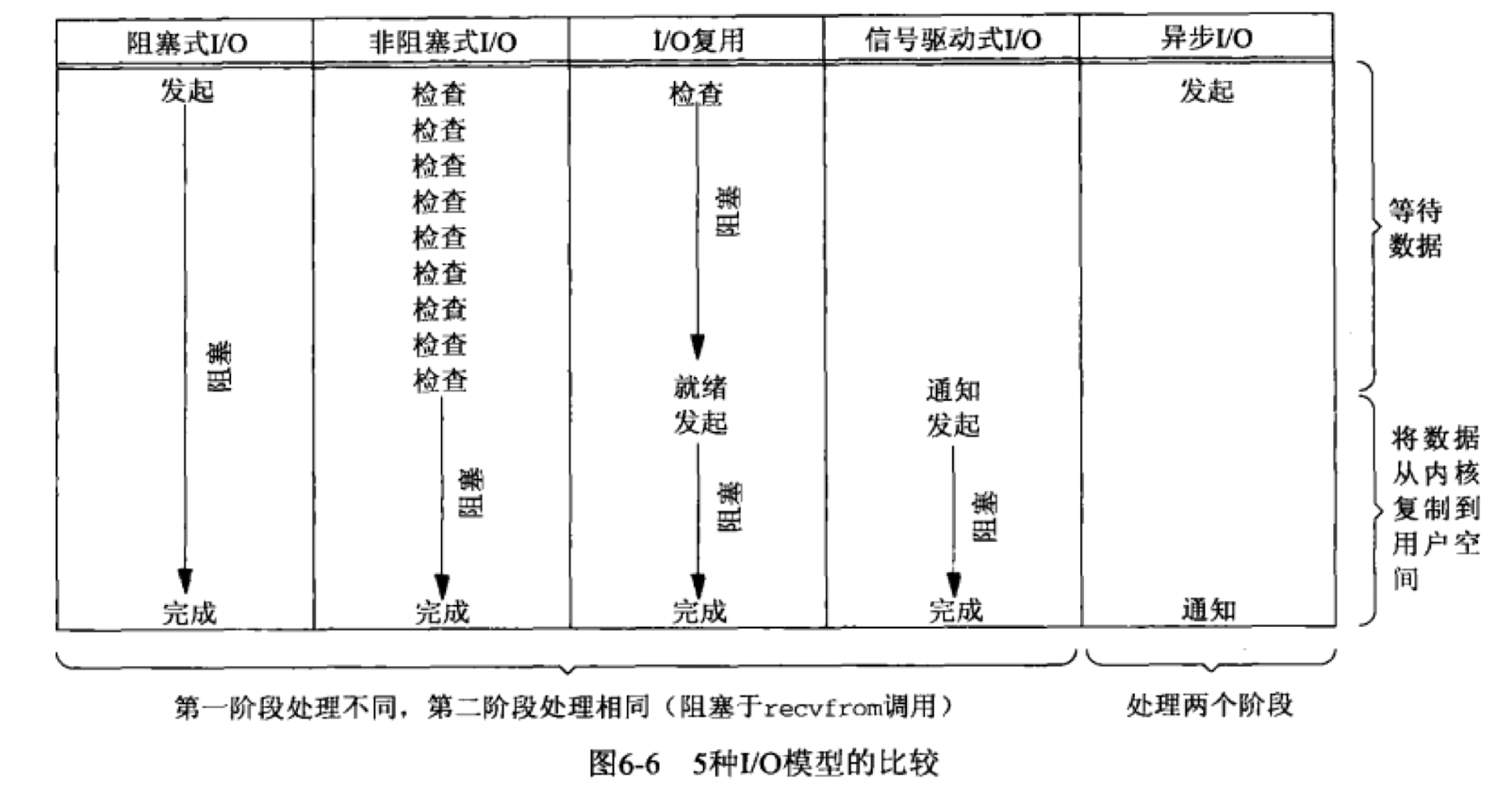
1.I/O模型
我们将IO分为阻塞和非阻塞.
前者等待某些事件,直到就绪才会唤醒.后者直接返回.
一般来说,当事件就绪时在执行非阻塞I/O才能提高效率,可以结合I/O复用和SIGIO信号使用.
I/O复用就是利用了这种方法,通过I/O复用函数向内核注册事件,当事件就绪内核会通知给应用程序.其本身其实是阻塞的,但是拥有监听并通知事件就绪的能力.
除此之外,还有信号驱动式I/O.
2.select,poll,epoll
1)select
基本用途在于再给定的一段时间内,能够监听用户感兴趣的文件描述符上的可读,可写和异常等事件.
int select(int __nfds,fd_set *__restrict __readfds,fd_set *__restrict __writefds,fd_set *__restrict __exceptfds,struct timeval *__restrict __timeout);//成功返回则是就绪的文件描述符总数
typedef struct{
/* XPG4.2 requires this member name. Otherwise avoid the name
from the global namespace. */
#ifdef __USE_XOPEN
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->fds_bits)
#else
__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->__fds_bits)
#endif
} fd_set;第一个参数代表所要监听的文件描述符的总数,一般设置为所有文件描述符中最大值+1.
中间三个参数代表的是,文件描述符的集合,分别对应可读,可写,异常三种事件的文件描述符的集合.
对于fd_set这个数据结构,主要是有一个向量的数组构成,而这个数组中每个元素中的每一个bit都代表一个文件描述符.
timeout则代该函数等待超时的时间.select返回的timeout当失败时,timeout是不确定的.
文件描述符就绪的条件
可读:
- socket内核缓冲区中字节数>=SO_RCVLOWAT.
- 通信的对方关闭连接.
- 所监听的socket有新的连接请求.
- 有未处理错误,应该使用getsockopt读取或者清除.
可写:
- socket内核缓冲区中字节数>=SO_SNDLOWAT
- 写操作被关闭.
- 使用非阻塞connect连接成功或者超时之后.
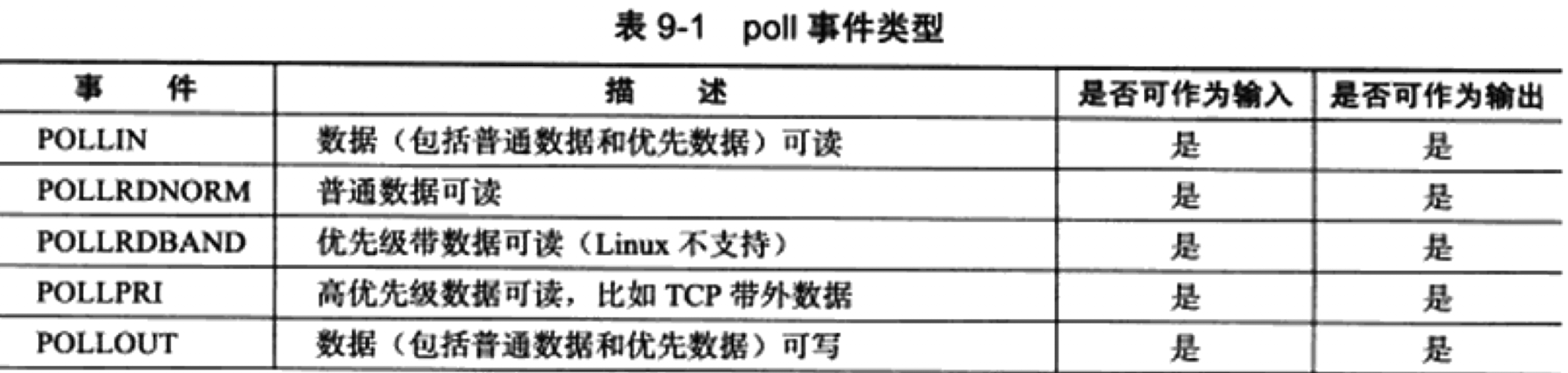
2) poll
其作用在于在指定时间内轮询一定数量的文件描述符,测试是否有就绪者.
int poll (struct pollfd *__fds, nfds_t __nfds, int __timeout);
struct pollfd{
int fd; /* File descriptor to poll. */
short int events; /* Types of events poller cares about. */
short int revents; /* Types of events that actually occurred. */
};其中不同之处在于fds.events代表这个文件描述符就绪所关心的事件,revents由内核修改,返回的是实际发生的事件.

六.进程间通信
Posix IPC和System V IPC的区别是什么?
1.消息传递
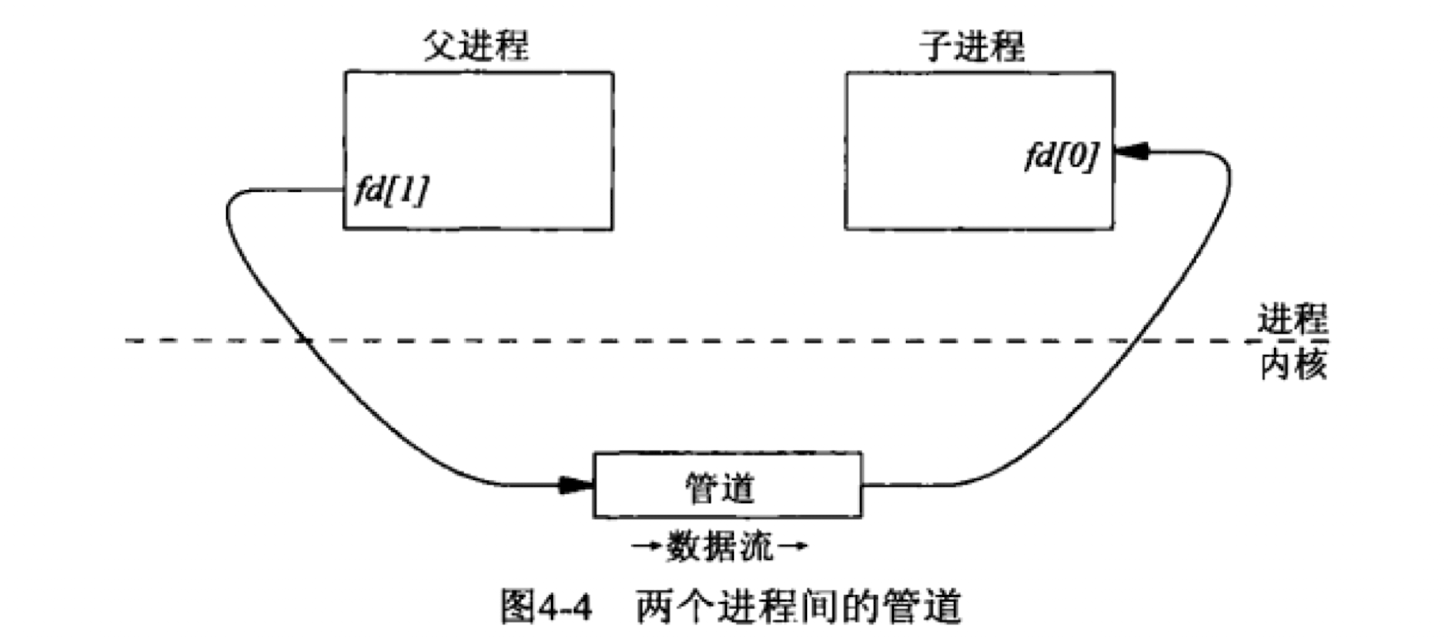
1)通道

图中“路径名”和“文件内容或出错消息”描述了管道的作用.可以理解为一个提供单向数据流的连接.
#include<unistd.h>
int pipe(int fd[2]);//一般情况下,是单向的,fd[0]是读者,fd[1]是写者.不仅仅可以局限于一个进程中两个描述符的通信,更经常作为两个不同进程之间的通信.
下面是一个例子,实现子进程和父进程之间的双工管道.
void client(int,int);
void server(int,int);
int main(int argc,char **argv){
int pipe1[2],pipe2[2];
pid_t childpid;
pipe(pipe1);
pipe(pipe2);
if((childpid = fork())==0){
close(pipe1[1]);
close(pipe2[0]);
server(pipe1[0],pipe2[1]);
exit(0);
}
close(pipe1[0]);
close(pipe2[1]);
client(pipe2[0],pipe1[1]);
waitpid(childpid,NULL,0);
exit(0);
return 0;
}对于子进程来说,要从pipe1[0]中读,从pipe2[1]中写.对于父进程来说,要从pipe1[1]中写,从pipe2[0]中读.进程最好关闭不再需要用到的文件描述符.
除此之外,标准I/O还提供了popen函数,用于创建一个管道并且启动另外一个进程,该进程要么从管道读入标准输入,要么写入标准输出.
FILE *fpr,*fpw;
if((fpr = popen("ls","r"))==NULL){//“r”返回的是output
printf("error r\n");
}
if(((fpw = popen("ls","w"))==NULL)){
printf("error w\n");
}
fclose(fpw);
fclose(fpr);
return 0;2)FIFO
进程的缺点在于缺乏名字的标识,一般只能用于具有亲缘关系的进程之间进行通信.FIFO的像管道一样,作为单向数据流,但是可以有路径名与之关联,也可以说是有名管道.
#include<sys/types>
#include<sys/stat.h>
int mkfifo(const char *, mode_t);至于在使用上,我们可以将其视为,在文件系统中建立了一个文件,这个文件就对应了一个管道,之后使用管道的进程通过调用
open来获取读/写的一端(返回文件描述符).当结束使用时,除了关闭获取的文件描述符,还应该将创建的FIFO文件
unlink.
注意,当不能正确使用FIFO会出现问题,尤其是open的顺序和读写的设置.如果一系列的顺序如下,就会触发死锁,因为读者在写着存在之前是阻塞的.
child:
open(FIFO1,O_RDONLY,0);
open(FIFO2,O_WDONLY,0);
parent:
open(FIFO2,O_RDONLY,0);
open(FIFO1,O_WDONLY,0);3)管道和FIFO的额外属性与限制
系统对于管道和FIFO的限制为:
- OPEN_MAX,一个进程在任意时刻,可以打开的最大描述符的数量.
- PIPE_BUF,可以原子地写往一个管道或者FIFO的最大数据量.
(base) ➜ network_programming getconf OPEN_MAX
1048575
(base) ➜ network_programming getconf PIPE_BUF /
512上面展示了,如何查看系统对两个变量的限制.
4)消息队列
这里,以Posix 消息队列为例.
可以将其视为一个消息组成的list,有写权限的线程可以从中放置消息,有足够写权限的可以从中取出消息.
相比pipe和fifo,消息队列的写者不依赖于读者的存在,而像pipe和fifo,如果不存在读者就先有写者,那么写者就是没有意义的.
除此之外,消息队列具有随内核的持续性,而pipe和fifo一旦被关闭,内部数据也就消失了.
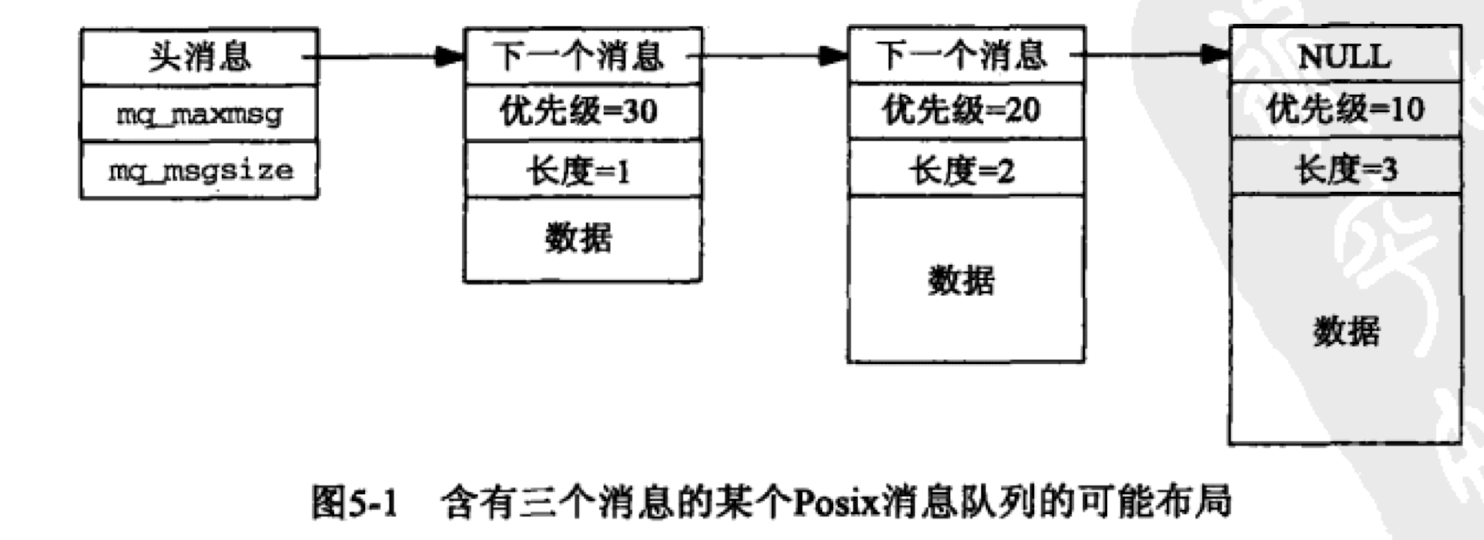
#include<mqueue.h>
mqd_t mq_open (const char *__name, int __oflag, ...) __THROW __nonnull ((1));//mqd_t是一个整型,消息队列描述符
int mq_close (mqd_t __mqdes) __THROW;
int mq_unlink (const char *__name) __THROW __nonnull ((1));每一个消息队列,像文件一样有底层名称,并且维护着一个引用计数.对于close来说,将一个mq关闭,但没有将消息队列从系统删除,unlink则类似于文件删除的机制,如果引用计数不会减到0,那么只是将此name消除,知道引用计数减到0,这个消息队列就彻底被删除了.
除此之外,还有设置消息队列属性的几个API.
首先,我们先了解一下,一个消息队列都包含哪些属性
struct mq_attr{
__syscall_slong_t mq_flags; /* Message queue flags. */
__syscall_slong_t mq_maxmsg; /* Maximum number of messages. */
__syscall_slong_t mq_msgsize; /* Maximum message size. */
__syscall_slong_t mq_curmsgs; /* Number of messages currently queued. */
__syscall_slong_t __pad[4];
};具体而言,相关的API为:
int mq_getattr (mqd_t __mqdes, struct mq_attr *__mqstat) __THROW __nonnull ((2));//将__mqdes对应的属性返回到__mqstat中.
int mq_setattr (mqd_t __mqdes,const struct mq_attr *__restrict __mqstat,struct mq_attr *__restrict __omqstat)
__THROW __nonnull ((2));//下面简要介绍一下关于发送和接受的API.
ssize_t mq_receive (mqd_t __mqdes, char *__msg_ptr, size_t __msg_len,unsigned int *__msg_prio) __nonnull ((2));
int mq_send (mqd_t __mqdes, const char *__msg_ptr, size_t __msg_len,unsigned int __msg_prio) __nonnull ((2));在这两个API中前三个参数和一般前面所提到的send相似.
而第四个参数,对于receive来说,用于返回所接受消息的优先级,对于send来说,则是所发送消息的优先级,要求必须小于MQ_PRIO_MAX.
如果不想使用优先级,将send中的设置为0,receive设置为NULL.
此外就像pipe和fifo一样,系统对于消息队列也存在一定的限制:
- MQ_OPEN_MAX,一个进程能够打开的消息队列的最大数量.
- MQ_PRIO_MAX,任意消息的最大优先级+1.
下面是有关于System V 的消息队列的API:
int msgget (key_t __key, int __msgflg) __THROW;//创建或者获取一个已存在的消息队列.
int msgsnd (int __msqid, const void *__msgp, size_t __msgsz,int __msgflg);
ssize_t msgrcv (int __msqid, void *__msgp, size_t __msgsz,long int __msgtyp, int __msgflg);
int msgctl (int __msqid, int __cmd, struct msqid_ds *__buf) __THROW;2.同步
3.共享内存区
共享内存效率是很高的,因为不需要涉及到进程的数据传输,但是共享内存作为一份共享资源,处理不慎就容易造成竞争条件.
其中以System V的共享内存方法为例,主要的API如下:
#include<sys/shm.h>
int shmget (key_t __key, size_t __size, int __shmflg) __THROW;
void *shmat (int __shmid, const void *__shmaddr, int __shmflg)
__THROW;
int shmdt (const void *__shmaddr) __THROW;
int shmctl (int __shmid, int __cmd, struct shmid_ds *__buf) __THROW;- shmget用于创建或者获取一个已经存在的共享内存.
- shmat,用于将某个共享内存和进程中的某个地址关联起来.
- shmdt,将__shmaddr关联的共享内存解除绑定.
- shmctl用于控制共享内存的某些属性.
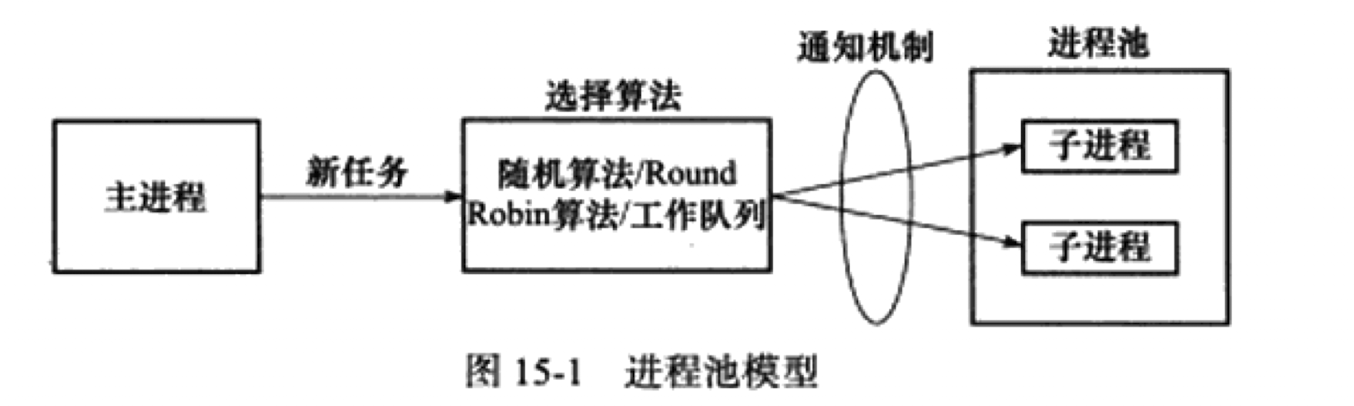
4.进程池与线程池
池这个概念,我们之前阐述过,主要用于避免动态创建和释放带来的一些问题.
就动态创建子进程或者子线程,主要问题如下:
- 动态创建是耗时的.
- 动态创建,往往会采用一个客户对应一个进程的方式,这样容易导致过多进程/线程,进程/线程切换的开销将会很大.
- 子进程往往和其父进程有写时复制的特性,复制过多是一种开销极大的行为.
进程池由服务器程序预先创建好,当又新的客户需要服务时,就从池中选取一个,使用完就放回池中.
其中选取方式有以下几种:
- 设计选取算法.随机,轮转等.
- 采用工作队列,闲置的线程在队列中休眠,当需要处理客户时,从中唤醒一个.