MapReduce
0.Abstract
MapReduce是一种编程模型,一般用于在分布式系统上并行地处理大规模数据.
对于在此框架上开发的程序员来说,主要制定map和reduce这两个函数,一般情况下,前者的输入和输出都是k-v的,后者则合并前者生成的中间结果.
1.Introduction
其实在很多大规模计算的场景下,难点并不在于原始计算本身,而在于在分布式系统中,如何并行计算,分配数据,容错处理等问题.
MapReduce的核心作用就在于提供一种抽象,不需要考虑太多上述问题.
其设计思想:很多计算可以视为,将数据分解为一个个记录,每个记录可以经过一个Map函数,形成一个k-v元组,而Reduce可以将相同key值的元组合并在一起.
这是一种分而治之的思想.
2. Programming Model
User在设计时,主要考虑的是Map和Reduce.
一个比较简单的应用就是统计单词数量.

一个map处理的是一个k-v对,每处理一个k-v对,就将相应的w的value
+ 1.
一个reduce只处理一个key,参数中的迭代器是从中间结果中收集的values,将这些values
累加起来即可.累加结束后,形成最终的key对应的结果.
除此之外还有其他应用:
- 从日志文件中,统计
url的访问频率. - Reverse Web-Link Graph.
- 倒序索引.
- 分布式排序.
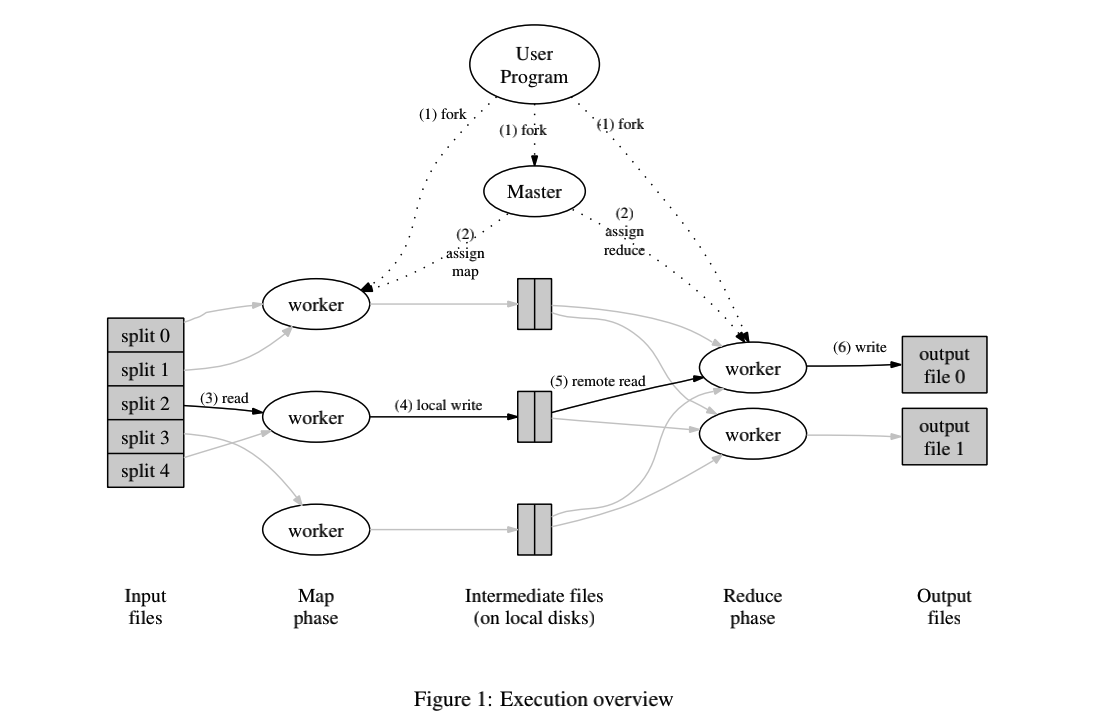
总体的运行图如下:
3.Implementation
这一部分描述的实现方式主要适用于(使用交换式以太网连接的):
- x86双处理器,linux系统,内存2-4GB.
- 一个集群数百或者上千个机器.
- 网络方面,一般有100Mb/s或者1Gb/s.
- 存储硬件上,每个机器有直连的IDE硬盘,同时有运行的分布式文件系统,提供容错服务.
- 用户像调度系统提交一组任务,每组任务可经过调度系统分配给某些机器.
所以,一般来说,描述一个集群的配置,往往从如下角度分析:
- 机器的硬件(处理器,内存等),操作系统.
- 规模(机器数量).
- 网络带宽与存储(硬件和软件).
3.1 Execution Overview
再次复现一下这个过程,结合上面的图片:
- 在用户程序中所使用的
MapReduce库,将输入的文件split成(16-64 MB)大小的部分(M个),然后 MapReduce 在一个机器集群上启动很多个程序的副本. - 在这些启动的程序副本中,分为
master和worker,前者是特殊的,一般有一个.由M个Map任务,R个Reduce任务,master具有为worker分工的功能. - 对于分工到
Map任务的worker读取到一份split,然后解析出输入的k-v,并带入Map函数,进而产生结果,结果缓存在内存中. - 缓存在内存中的
intermediate pairs会被写的disk中,会被partitioning function分成R份,被写到的disk的位置会告知master,进而可以使master在分配Reduce任务时,告知worker的需要的输入路径. - 当
worker收到了master通告的disk地址,就通过rpc从相应的disk读取内容,读取完之后,根据key进行排序. worker将排好序的数组进行遍历,将每个key值对应的values集合,根据reduce得出结果,最终输出到文件.- 当所有
map和reduce结束,master唤醒用户进程,MapReduce调用返回.
3.2 Master Data Structures
- 记录任务状态.包括
Map和Reduce的状态(空闲,处理中,完成). - R个中间结果的位置与大小.
3.3 Fault Tolerance
Worker Failure
master会周期性地ping
workers.超出特定时间没有回应就说明此worker宕机.
宕机的worker相应的任务会被设置为空闲,然后进行重新分配.
Reduce已经完成但是宕机的任务无需重新执行,因为其输出文件在全局文件系统中,而Map则需要重新做,因为其输出文件一般在已经故障的机器的本地disk上.
如果有一个Map任务因故障而重新分配了,此时所有正在运行的Reduce都需要重做.
Master Failure
一般情况下,只有一个master故障的可能性比较低,一旦故障就会终止整个MapReduce.
对于任务的状态,master会进行维护,故障后新的master可以继续从最近的任务状态检查点进行.
Semantics in the Presence of Failures
暂鸽
3.4 Locality
网络带宽是一种稀缺的资源.
论文中的实验部署在GFS中,GFS 将每个文件划分为多个 64MB 的块,每个块都会存几个副本(一般是 3 个)在不同的机器上.
尽可能地从本地磁盘上读取数据是一种节省网络带宽的好办法.所以master在分配Map任务时,尽可能保证分配到一个有该任务相应副本的机器.
最终呈现的效果是,在大规模运行时,worker大多数输入数据是从本地读取的.