mit 6.824:lab 1
0.前言
久仰mit 6.824的威名,上个学期的时候我就一直想抽空学一学,但是一直没有抽出太多时间.假期打算好好做做.
至于做这个实验的语言基础方面,我在大二下学期只接触过一点点go语言,没有写过太多,在lab中我把中途遇到的一些问题写到了另一篇博客中,也算是0的基础吧.
除此之外,在多线程/进程编程和网络方面,当时做计网编程作业时也遇到过类似的,当时x老师布置了一个实现基于分布式系统的ipv6 DNS服务的作业,我花了一些时间去做,虽然实现效果不好,但是一些设计的想法感觉在这里的lab 1还是可以用上的.而且最近也在学习用c++写一个webserver程序(被死锁折磨qaq......)感觉也是有不少东西是相通的.
在真正动手编程之前,读了一下MapReduce的论文,只读了前一半,至于对做这个实验来说,感觉足够了.
1.基本框架和思路
其框架结构图基本上是遵循论文中的架构的.
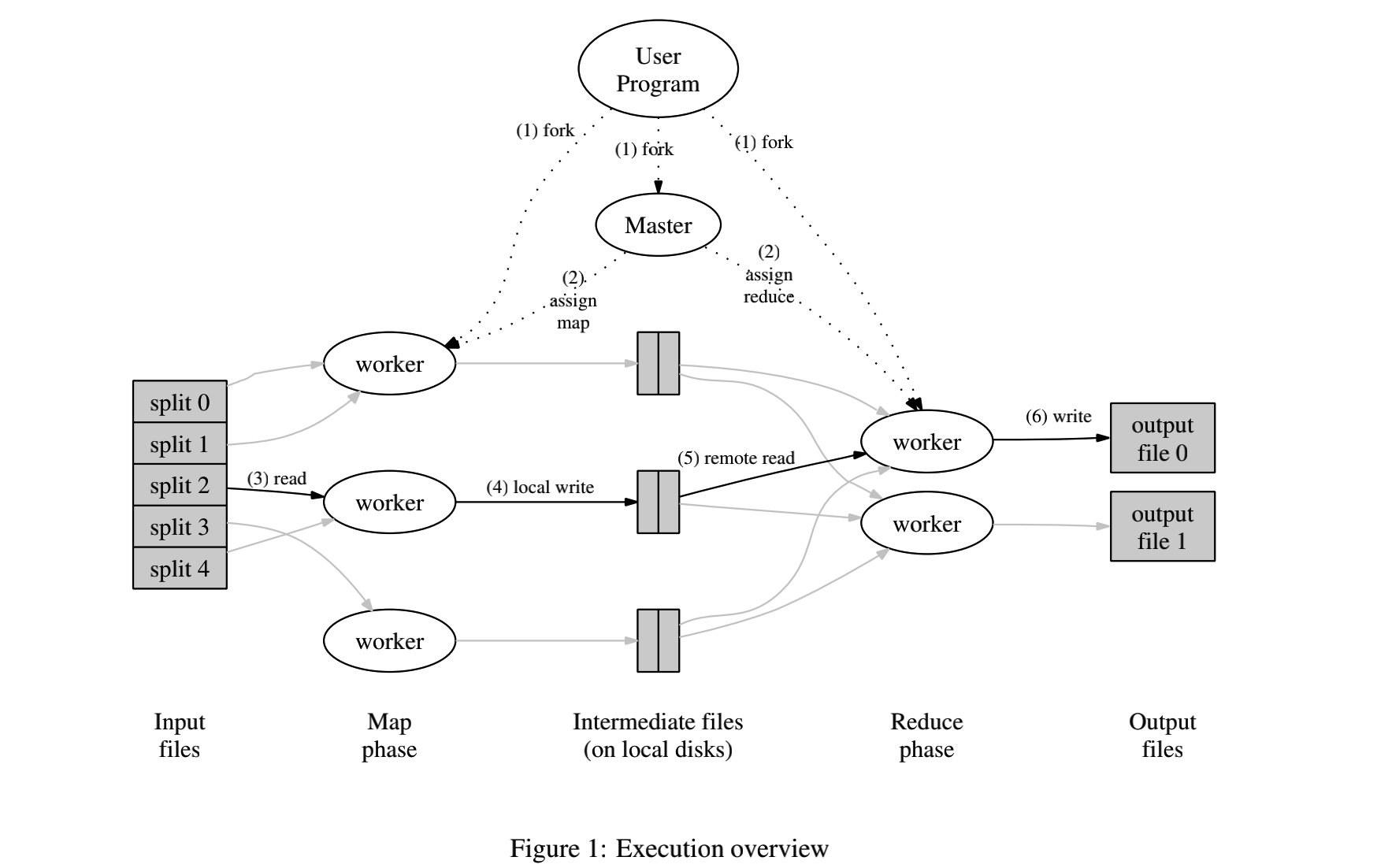
但是若论实现,不同的人肯定还是有不同的实现方式吧,往细节处追究还是会有不小的差别的.
2.具体实现
1) master(coordinator)
从总体上看的话,master相当于一个接收处理rpc请求的服务器,这些请求也正是来自于那些worker.所以说其主要部分就是实现一些rpc函数.
但是master还有个重要的任务在于,追踪在线的worker,并且记录整个MapReduce任务的状态.所以说还需要一些数据结构,来保存这些信息,并且这些信息还应该在处理rpc的过程中改变.
就像论文中所说:

其实我的在实现时,和它还是有一些区别的.我在记录状态时,不仅仅记录了非空闲worker的状态.·master的总体数据结构如下:
type Coordinator struct {
// Your definitions here.
isShut bool
nMap int //map任务的总数
nReduce int //reduce任务的总数
mapfinishM map[int]int //已经完成的map任务
mapfinishR map[int]int //已经完成的reduce任务
maplist list.List //待分配的map任务
reducelist list.List //待分配的reduce任务
inputFiles []string //输入map任务的文件路径
interFiles []string //输入reduce任务的文件路径,也是由map任务所产生的
mapWorker map[int]workerState //worker的状态记录
mutex sync.Mutex //锁
wg sync.WaitGroup
}最初我在考虑记录任务完成的情况,只是考虑使用一个表示完成数量的变量,但现在之所以考虑使用map是与我所设计的容错机制有关的,会在后面再详细说明.其中这里map的key是每个worker的编号,这个编号是每个worker进程的pid,关于worker状态,则有相应的数据结构进行描述:
type workerState struct {
tasktype int //记录最近一次所处理任务的类型,只在任务分配时更新
tid int //最近处理任务类型的编号
deadtime int64 //倒计时,当过期时判定该worker为crash
}为什么要考虑使用tasktype和tid这一对变量呢?这用于,当检查到某个worker宕机的时候,可以因此确定其最近所处理的任务类型和任务编号,然后再根据mapfinishM或者mapfinishR来判断这个宕机worker所处理的任务有没有完成,如果已经完成了,就此作罢,否则就将其重新加入到分配队列maplist或者reducelist,将该任务重新等待分配.
说完这些,看一下RPC函数:
func (c *Coordinator) ReplyTask(args *AskTaskArgs, reply *Task) error
func (c *Coordinator) GetFinishSig(args *Task, reply *FinishReply) error
func (c *Coordinator) BeatReponse(args *BeatArgs, reply *BeatReply) error其中ReplyTask用来为worker分配任务,GetFinishSig则用于接收完成任务的worker的通知,进而对相关的状态信息进行变化.
func (c *Coordinator) ReplyTask(args *AskTaskArgs, reply *Task) error {
wid := args.Wid
c.mutex.Lock()
nfinishMap := len(c.mapfinishM)
allocatedMap := c.maplist.Len()
allocatedReduce := c.reducelist.Len()
reply.Nreduce = c.nReduce
reply.FilesTask = []string{}
if nfinishMap != c.nMap && allocatedMap != 0 { //分配一个map任务,在这里的nalloc和nmap的判断其实不对
Front := c.maplist.Front()
reply.Tid = Front.Value.(int)
c.maplist.Remove(Front) //直接从front移除
reply.TaskType = MapTask
reply.FilesTask = append(reply.FilesTask, c.inputFiles[reply.Tid]) //暂时先按照一个来算
tmp := c.mapWorker[wid]
tmp.tasktype = MapTask
tmp.tid = reply.Tid
c.mapWorker[wid] = tmp
} else if nfinishMap == c.nMap && allocatedReduce != 0 {
Front := c.reducelist.Front()
reply.Tid = Front.Value.(int)
c.reducelist.Remove(Front)
reply.TaskType = ReduceTask
re := regexp.MustCompile("[0-9]+")
//fmt.Println(re.FindAllString("mr-intermadiate-0-4", -1))
for _, filename := range c.interFiles {
findstrs := re.FindAllString(filename, -1)
number, _ := strconv.Atoi(findstrs[1])
if number == reply.Tid { //对应的文件应该分配给worker
reply.FilesTask = append(reply.FilesTask, filename)
}
}
tmp := c.mapWorker[wid]
tmp.tasktype = ReduceTask
tmp.tid = reply.Tid
c.mapWorker[wid] = tmp
} else {
reply.Tid = -1
reply.TaskType = IdleTask
}
c.mutex.Unlock()
return nil
}首先来看一下这个rpc参数和返回值的数据结构:
type AskTaskArgs struct {
Wid int //该worker的编号
}
type Task struct { //这个将会作为reply返回,也可以用来作为已经完成的任务的信息
Tid int //任务号
TaskType int //任务类型
Nreduce int //任务数量
FilesTask []string //任务对应的处理文件
}其中的Wid作用在于因为需要更新worker的状态,更新为最近处理的任务.而返回值,除了任务类型和任务编号,还有对应的文件.
代码看上去有点长,但是大体上可以分为四个分支:
- Map任务还没有分配完,应该分配Map任务.
- Map做完了,应该分配Reduce了,所以分配Reduce任务.
- 所有任务完成或者其他情况,都是不分配任务的.
当有任务分配给一个worker时,首先从待分配队列中摘出一个任务,这个任务就是分配给这个worker的任务,根据这个任务的tid来确定相应的处理文件,进而设置好reply,然后更新此worker的任务状态(tid,tasktype).
下面是关于接收到finish的处理.
func (c *Coordinator) GetFinishSig(args *Task, reply *FinishReply) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if args.TaskType == MapTask {
_, isfinish := c.mapfinishM[args.Tid]
if isfinish {
return nil
}
c.mapfinishM[args.Tid] = 1
c.interFiles = append(c.interFiles, args.FilesTask...)
if len(c.mapfinishM) == c.nMap { //表示所有map已完成
fmt.Printf("The Map is finished\n")
}
} else if args.TaskType == ReduceTask {
_, isfinish := c.mapfinishR[args.Tid]
if isfinish {
return nil
}
c.mapfinishR[args.Tid] = 1
if len(c.mapfinishR) == c.nReduce {
fmt.Printf("The Reduce is finished\n")
}
}
return nil
}主要分为两种不同的任务,也就是Map和Reduce两种情况,首先检查此任务之前是否已经完成,如果之前就已经完成则将不继续处理,否则就设置该任务的finishmap为1,如果是Map就将生成的文件追加到interFiles中.对于FinishReply,其实并没有派上什么用场.
func (c *Coordinator) BeatReponse(args *BeatArgs, reply *BeatReply) error {
//fmt.Println("A worker ping the coordinator......")
wid := args.WorkerId
tmpargs := workerState{}
tmpargs.deadtime = args.DeadLine + 3
c.mutex.Lock()
defer c.mutex.Unlock()
tmpargs.tid = c.mapWorker[wid].tid
tmpargs.tasktype = c.mapWorker[wid].tasktype
c.mapWorker[wid] = tmpargs //相当于只有deadtime变了
//fmt.Printf("the worker %v deadtime is %v\n", wid, tmpargs.deadtime)
if len(c.mapfinishR) == c.nReduce {
c.isShut = true
reply.IsShut = true
fmt.Printf("The master shut\n")
} else {
c.isShut = false
reply.IsShut = false //无需关机
}
return nil
}在这里核心在于更新worker状态中的时间,不过我把总任务终止的判断也写在这里了,这看上去不太好,似乎把这一部分放到GetFinishSig中是更符合人直觉的,但是我认为放到BeatReponse有一个优点就在于,每个在线的worker都会通过心跳包来和master交互,因而每个worker都可以通过心跳包的响应得出退出的信号.如果在GetFinishSig中实现的话,只有当时完成任务的worker才可以得知mastershut的信号,就难以做到通知所有worker了.此外还有一个问题,就是master应当等待其他worker退出后,自己再退出,在这里的实现上,我做的方式比较笨,我是通过sleep等待来实现的,让mastersleep的时间长一些,这样一般就能保证其他的worker已经都退出了.如下:
func (c *Coordinator) Done() bool {
ret := false
c.mutex.Lock()
ret = c.isShut
// Your code here.
c.mutex.Unlock()
if ret == true {
time.Sleep(time.Duration(3) * time.Second)
}
return ret
}之后是关于crash的判断,这一部分并不是一个rpc请求,而是分出一个单独的线程运行.
func (c *Coordinator) CheckCrash() error {
for {
current := (time.Now().Unix())
//fmt.Printf("The current time is %v\n", current)
c.mutex.Lock()
for key, value := range c.mapWorker {
if current > value.deadtime { //只要出现一个crash的,直接从头remake
tid := value.tid
flag := false //加入
if value.tasktype == MapTask {
for node := c.maplist.Front(); node != nil; node = node.Next() {
if node.Value == tid {
flag = true //分配队列中如果已经有了
}
//fmt.Printf("the node in maplist is %v\n", node.Value)
}
_, isfinish := c.mapfinishM[tid]
flag = flag || isfinish
if flag == false {
c.maplist.PushBack(tid)
}
} else {
for node := c.reducelist.Front(); node != nil; node = node.Next() {
if node.Value == tid {
flag = true
}
//fmt.Printf("the node in maplist is %v\n", node.Value)
}
_, isfinish := c.mapfinishR[tid]
flag = flag || isfinish
if flag == false {
c.reducelist.PushBack(tid)
}
}
//fmt.Printf("The crash......\n")
delete(c.mapWorker, key) //移除,将其持有的任务放入list中
//c.isCrash = true
}
}
if c.isShut == true {
c.mutex.Unlock()
fmt.Printf("The check thread exit\n")
return nil
}
c.mutex.Unlock()
time.Sleep(time.Duration(5) * time.Second)
}
return nil
}这一部分的设计,简而言之就是周期性地检查mapWorker.如果其中某个节点的已经过期了,就判断为此worker宕机,所以这个时候就跟绝workerState中记录的其所处理的task的状态,其中这个任务记录的是这个worker最近一次处理的任务类型和tid,所以这个任务有可能早已运行完了,也可能正在运行.所以对于这个响应的任务,首先判断待分配任务队列里有没有,这个队列里的任务一定是还没有完成的,需要分配的.除此之外,还需要判断这个任务有没有完成,如果已经完成所以就免了.最后如果符合“(待分配队列中没有&&未完成)”的任务,才会加入到待分配队列中.最后,对于这个worker再`mapWorker中对应的项,也将会被移除.
由于这是一个单独的线程,所以对于其退出的判断也需要点讲究,所以每次还会检查isShut是否为真,否则就会返回.
至此,关于master的主干部分就说完了.
2) worker
worker的实现相对比较复杂.
worker相比master来说,只需要记录与自己有关的数据和信息就行了.对于一个worker来说,其全局性的信息如下:
const ( //表示状态机的状态
IdleState = 0
MapState = 1
ReduceState = 2
FinishedState = 3
EndState = 4
)
type worker struct {
state int //状态,用于状态机的表示
wid int //这个worker的编号
taskDoing Task //正在做的任务
taskFinish Task //已经完成的任务
funcM func(string, string) []KeyValue //Map对应的处理函数
funcR func(string, []string) string //Reduce对应的处理函数
mutex sync.Mutex //锁
}为了便于实现,我对于worker采用了状态机的模式来进行处理,不过也不算非常规范的状态机.其中
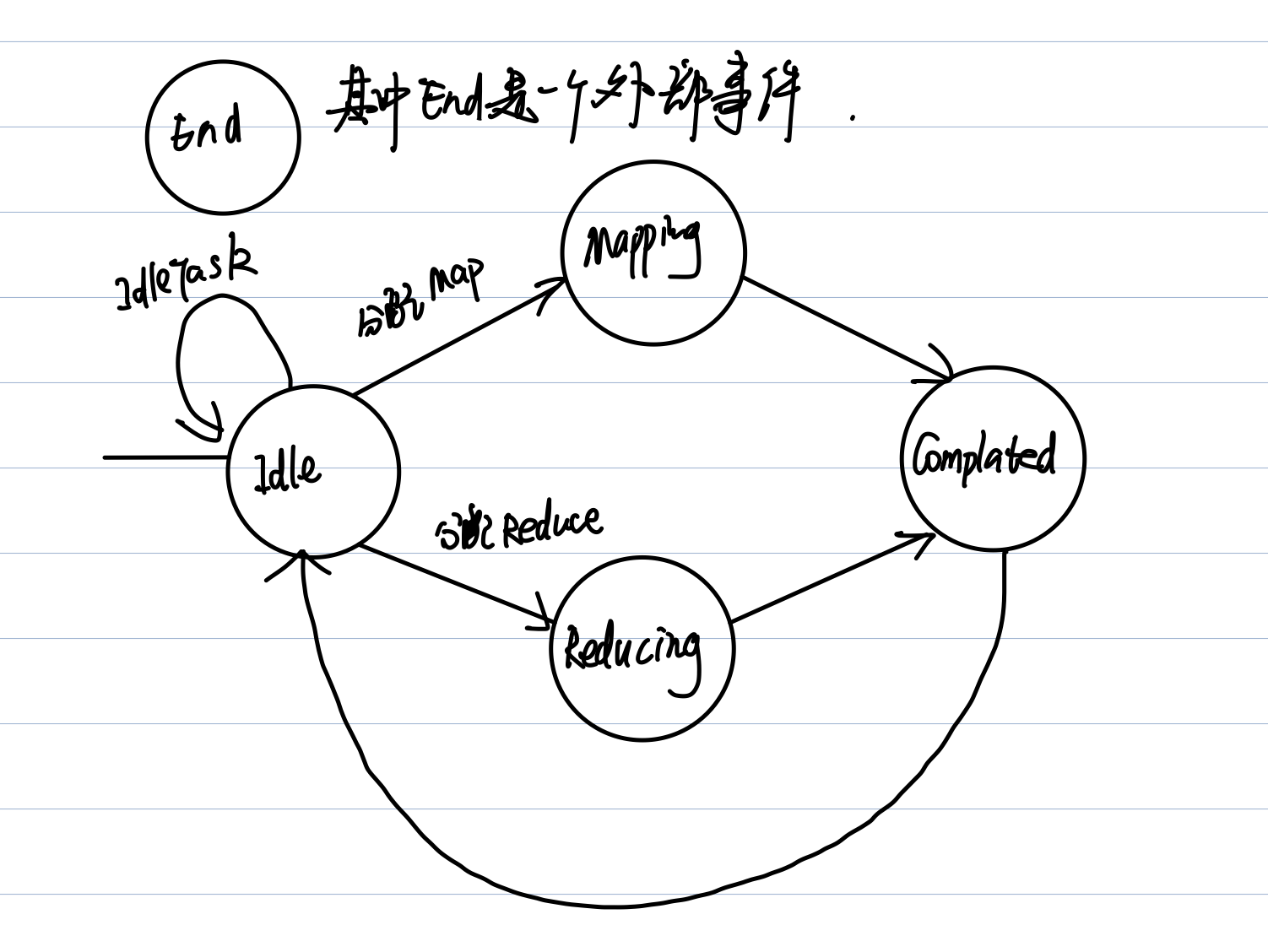
对于各个状态:
- IdleState,就是初始状态,出于此状态时发送任务请求,如果没有任务仍然保持在Idle否则,进入Mapping或者Reducing.
- Mapping,Reducing,调用相应的处理函数,处理完就进入
Complated状态. - Completed,向
master发送完成信号,之后进入Idle状态. - End状态,可以看做是一个由外部事件触发的(也就是在心跳包中如果收到
isShut为true).
其状态机相关实现如下:
func (w *worker) doMachine() {
w.mutex.Lock()
defer w.mutex.Unlock()
switch w.state {
case IdleState: //这个时候的任务在于发送请求
task := w.AskForTask()
if task.TaskType == MapTask { //根据所分配的任务变化状态
w.state = MapState
w.taskDoing = task
} else if task.TaskType == ReduceTask {
w.state = ReduceState
w.taskDoing = task
} else if task.TaskType == IdleTask {
w.state = IdleState
}
break
case MapState:
w.doMap()
w.state = FinishedState
break
case ReduceState:
w.doReduce()
w.state = FinishedState
break
case FinishedState:
w.SignalFinish()
w.taskDoing = Task{} //清空
w.taskFinish = Task{}
w.state = IdleState
break
case EndState:
break
}
}此外running是一个状态机的主线程,如下:
func (w *worker) running(wg *sync.WaitGroup) bool {
defer wg.Done()
for {
w.doMachine()
//第一次一般就是申请任务的动作.
w.mutex.Lock()
if w.state == EndState {
//return true //终止
fmt.Printf("the state is end\n")
w.mutex.Unlock()
return true
}
flag := (w.state == IdleState)
w.mutex.Unlock()
if flag {
time.Sleep(time.Duration(1) * time.Second) //状态机采用轮询的方式
}
}
return false
}在这里之所以对于IdleState状态时,进行sleep处理,是为了防止空闲状态出现过多无用的任务请求和响应包.当处于EndState状态时,这个线程就会终止,这也就意味着整个worker将要终止.
下面是关于worker中心跳请求的实现
func (w *worker) beatRequest(wg *sync.WaitGroup) bool {
defer wg.Done()
args := BeatArgs{}
reply := BeatReply{}
args.WorkerId = w.wid
w.mutex.Lock()
args.WorkerState = w.state
w.mutex.Unlock()
for {
args.DeadLine = (time.Now().Unix())
w.mutex.Lock()
if w.state == EndState {
w.mutex.Unlock()
return true
}
w.mutex.Unlock()
ok := call("Coordinator.BeatReponse", &args, &reply)
w.mutex.Lock()
if !ok {
fmt.Println("beat a time error,the wid is %v", args.WorkerId)
w.state = EndState
}
if reply.IsShut == true {
//fmt.Printf("the state is end")
w.state = EndState
w.mutex.Unlock()
return true //心跳程序关闭
}
w.mutex.Unlock()
time.Sleep(time.Duration(3) * time.Second) //每3秒心跳一次
}
return false
}心跳线程主要就是一个loop,所以这一部分是作为一个额外的goroutine存在的,与running作为并行的.这个loop中每隔3s进行一次,每一轮首先要获取当前时间这是RPC请求中的重要参数,除此之外,参数中还需要这个worker的编号与状态.这个编号用于使master定位此心跳对应的状态表,而这个状态则与容错的处理有关.
当RPC接收到请求之后,其中我们关闭机制是通过心跳包来进行通知的,所以对于reply的判断中一个IsShut将会决定是否将要退出.
除此之外,还有两个相对比较简单的RPC调用.
func (w *worker) AskForTask() Task {
args := AskTaskArgs{}
args.Wid = w.wid
reply := Task{}
ok := call("Coordinator.ReplyTask", &args, &reply)
if !ok {
}
return reply
}
func (w *worker) SignalFinish() {
args := w.taskFinish //传递已经完成的任务的信息
reply := FinishReply{}
ok := call("Coordinator.GetFinishSig", &args, &reply)
if !ok {
}
}前者用于当worker处于空闲状态时,向master请求任务.后者用于worker完成一个任务时(处于完成状态)时,将任务进行通知,其中参数是一个Task结构体类型,这个结构体描述了一个任务.其中对于w.taskFinish的设置会出现在处理完Map和Reduce末尾的部分,可以将这个数据成员理解为最近一次所完成的任务.
//Map和Reduce相应的处理函数中,末尾对taskFinish进行设置
w.taskFinish.Tid = rid
w.taskFinish.TaskType = ReduceTask
w.taskFinish.FilesTask = append(w.taskFinish.FilesTask, oname)3.测试
测试结果并不完美,对于crash test之前的测试用例可以达到100%的正确率.
但是对于crash test会存在一定的问题,偶尔也会出错,正确率一般在95%以上.

4. 简单地复盘
我认为这个系统的设计,其中最核心的部分就在于心跳(状态跟踪),分配,容错.