DDIA:Chapter 5 Replication
数据复制就是对相同的数据维护多个副本于多个机器上.
其意义有:分散读取负载,容错.除此之外,可以在地理意义上有多个副本,从而使得用户可以访问更近的副本.
复制所带来的主要难点在于:当数据需要被写时,维持数据读取时的一致性.
其中主要模式有:单主,多主,无主.
1.领导者与追随者
其中主要的问题在于,如何维护数据以及数据的更新一致于每个机器上.
这个问题的关键在于,写操作的处理方式.最常见的处理方式:leader-based replication.
其主要过程在于:
- 其中一个维护副本的机器被选定为
leader,leader才可以处理用户的写请求,先在本地更新. - 其他节点为
follower,当leader执行写操作后,还会发送日志或者变化流给follows.进而followr作出更新. - 对于client的读取请求,既可以从leader中读也可以从follow中读.
1) 同步复制与异步复制的比较

关于对这两个方式的说明,图中就很清楚,follower1处理的是同步的,这个时候请求者会等待请求返回结束后,才会继续做其他事情,而异步则是调用者不主动地等待返回结果,而是继续向下运行,直到该请求返回成功过后,调用者才会收到相应的完成讯号.所以其要点在于是否主动等待响应,
所以可以说,使用同步的方式,能够对某个请求是否已经在follower上生效具有确定的把握,如果是异步,就不能确定在发送请求后的某个时间点究竟有没有生效.但是同步会阻塞请求的处理.
实际上,半同步的使用较多,比如说选一个follower作为同步的,其他都是异步的.
2) 安装新的Followers
当需要加入新的follower的时候,该做什么才能保证follower准确地含有完备的副本?
一般采用“快照+追加日志”的方式:
- 新来的
follower先通过leader获得某一个时间点的快照. - 然后通过和
leader比对日志,将缺失的日志追平(快照一般会标识其所到达的日志索引点).
3)对于节点宕机的处理
分布式系统的重要目标:即使局部某些设备发生宕机,但也应该在整体上维持正常且可靠的服务.
下面分两种情况进行讨论,分别是leader出错和follower出错的情况.
对于follower宕机的情况,比如说disconnect等情况,出现这种情况可以借助log进行恢复,等到重连后即可根据日志记录,去追平leader.
如果是leader宕机的情况,则是比较复杂的,
这个过程需要涉及到,新leader的更迭,client重试当前请求到新的leader,并且对于其他follower来说,可能为了和leader一致,而更新一些数据.这个过程称为failover.
其中一种自动地failover处理过程如下:
- 确定某
leader已经宕机.这大多数时候,借助心跳包来实现. - 选举出新的
leader,其中持有的日志比较新的节点是比较好的candidate. - 系统的
recongiguring.这个时候client重试写记录到新的leader中,确保旧的leader活过来后成为follower.
在failover中有如下几个容易出错的问题:
- 采用异步复制时,如果选出的新leader并没有完全更新到和旧leader一样新的log,并且又接受了一些来自client的写操作,那么当旧leader重回,应该怎么做呢?应该使旧leader丢弃其中自己未复制的写入,紧紧与新leader追平.
- 可能出现
split brain的现象,这使得对外会有两个接收写操作的leader.
4) 复制日志的实现
首先介绍一下基于语句的复制.将每个写入请求做成一个log,进而复制给follower.比如说kv数据库中的put,append,get等.如果遇到以下的情况,这种方式将会不适用:
- 每个语句会调用不确定性函数.比如说NOW,RAND等.这破坏了“相同的log序列下,状态机状态相同的准则”.
- 如果依赖于数据库中的现有数据或者含有自增序列.
- 有副作用(触发器,存储过程等).
总体来说,基于语义的复制其最主要的就是相同的log序列下,状态机状态相同的准则.也就是raft博士论文中所提到的复制状态机一致理论.
除此之外,还有基于行的日志复制,也称为逻辑日志,以及基于触发器的日志.
2.复制滞后引发的问题
单主模式对于写少读多的场景非常合适,当follower比较多的时候,能更好的负载均摊,读性能也更好.这只对异步复制比较适合,如果必须同步地复制到所有的follower,这使得一旦出现一个follower宕机,整个系统都会阻塞无法继续正常运行.
对于异步读取follower的情况,由于follower完全与leader达成一致是一个过程,所以当这个过程还没有完成时,所读取到的结果并不是最新的,然而这是一个暂时性的状态,倘若等到follower和leader一致即可避免,这也就是最终一致性问题.
最终一致性可以用来描述follower到leader一致的延迟时间,这无法从根本上避免,但是可以尽可能地缩小.
下面介绍一下一些复制延迟相关的情景.这些问题本质上是复制延迟导致.
1) 读自己的写
这主要针对的是这样的一个情景,一个用户写入数据后,又要进行读.
但是在异步复制中,该用户可能在该写log没有达成一致性复制的时候,读取了某个还没有得到复制的follower,这样读取的就是旧的值.
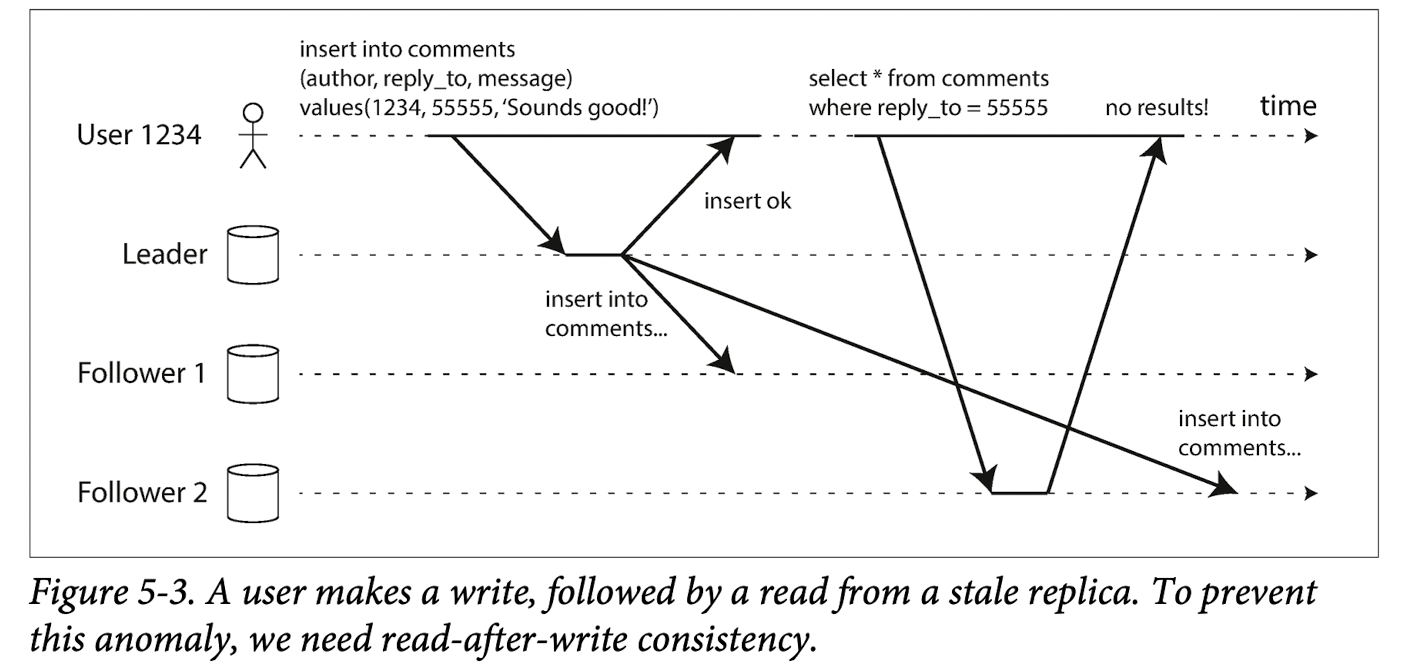
这里提供了一种解决思路,即保证读写一致性.即总是向一个client保证他自己提交的更新可以被自己读取到,不是自己的更新则不保证.
其实现方式有如下几种:
- 读取也从leader中进行读取.mit 6.824中的kvraft的Get也要经过leader实现.
- 但是上面的方法,会使得
leader的负载过于集中.可以将从leader读取的节点放宽,比如说对于更新小于一定时间的数据,从leader中读. - 如果是多个集群的话,则还需要一个控制中心,用来将请求路由到某个含有该数据的集群中.
2) 单调读
当1234用户对某个数据进行写,但是不同的follower延迟不同.
当一个用户从不同的follower对同一个数据进行读取时,先从延迟小已完成的follower读了,后从延迟大未完成的follower中读了.这导致一种时光倒流的现象.
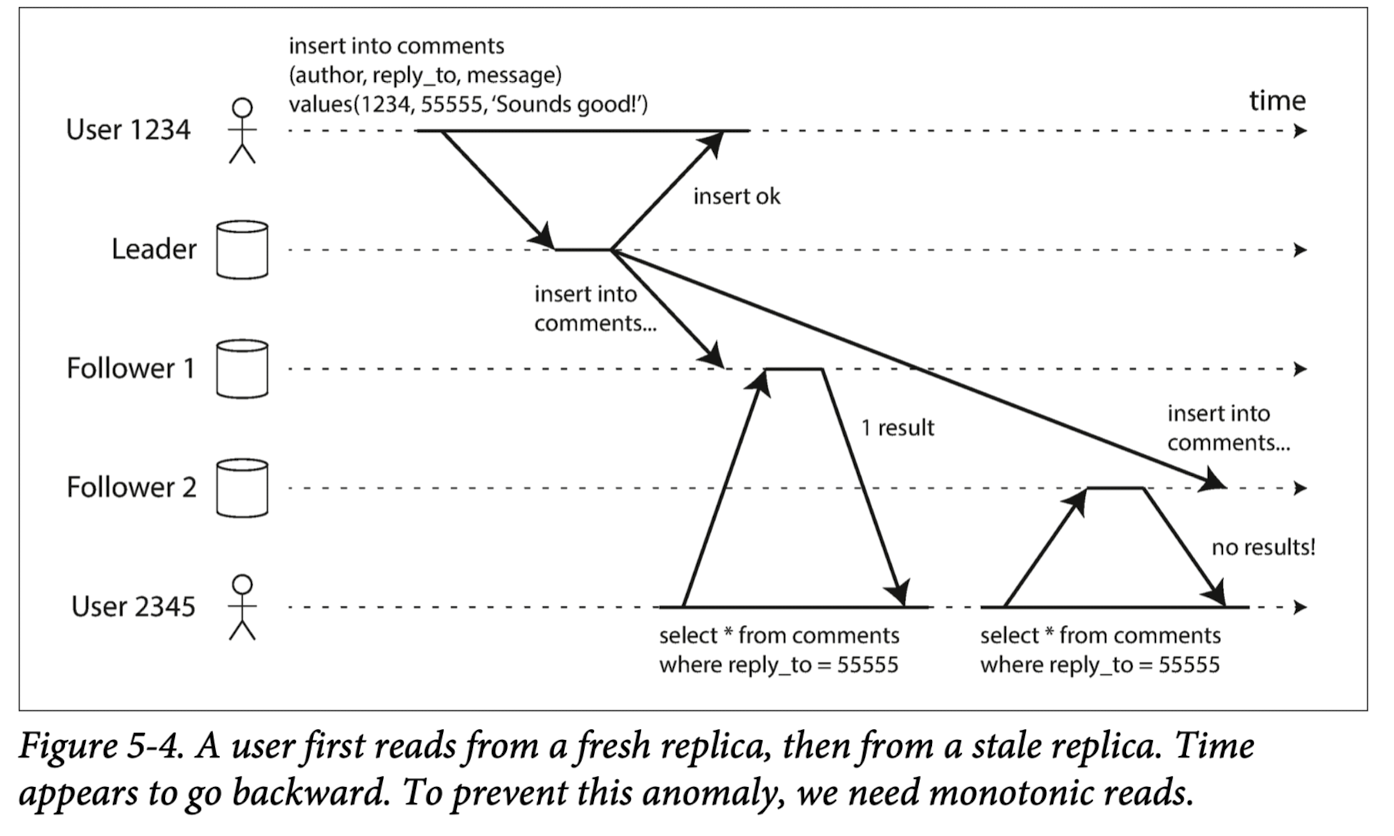
其中采用单调读的方式避免,即保证一个client总是从同一个副本中读取.如果出现某个副本失败,就要重新绑定.
3) 一致前缀读
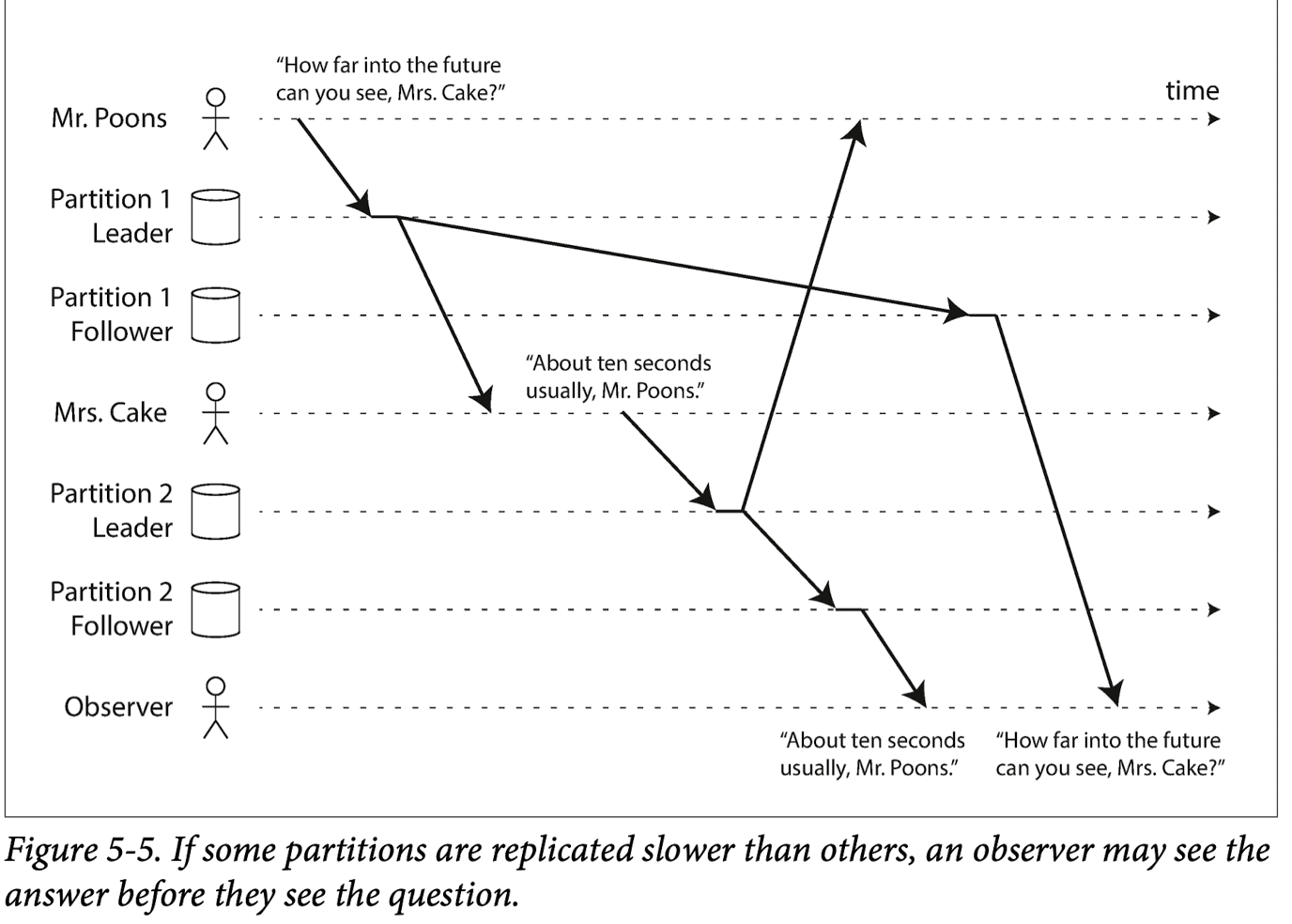
首先介绍一下一致前缀读这个概念:如果一系列写入按照某个顺序发生,那么任何人读这些请求时,也会看到它们以同样的顺序出现.
这个问题主要是sharded中的一个特殊的问题.
4) 复制延迟的解决方案
以上谈论到的请求,其本质上都是由于复制延迟所导致的.
其实很多时候,可以考虑在应用程序中作出更强的保证.或者可以考虑事务,这在后来的章节中进行介绍.
3.多主模式
简而言之,客户端发送多个写入到其中的某个leader中,进而该leader给其他节点复制.
1)应用场景
其中最主要的场景就是多个数据中心的情况,也就是shard的情况.
每一个集群(数据中心)都会有一个leader,每一个集群内部都是常规的单主模式.
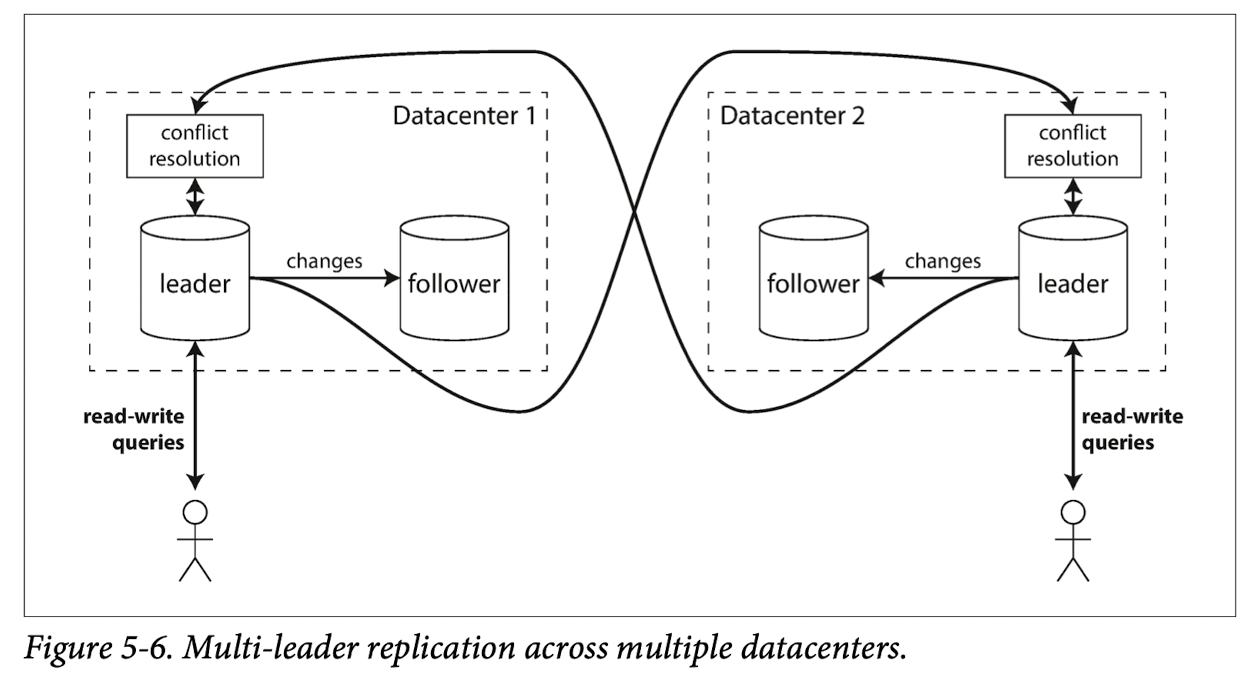
在下面的分析中,将对比单leader多group的情况进行分析,对于single-leader的来说,日志的复制需要跨越多个集群,性能很差.多个leader的情况,每个leader都之会在自己的group中写入,性能较好,此外不同的group之间还会有异步复制.
对于数据中心的停机的容忍度较高,如果是单主的模式,当leader所在集群crash之后,需要另一个集群中选出leader,而在多主配置中,只要等到故障的数据中心恢复,复制就会自动赶上.
对于网络问题的容忍度也更好,写操作只局限于一个group相比需要跨越多个group来说,其网络更可靠稳定.而多个group进行的异步复制:临时的网络终端并不会妨碍正在处理的写入.
但多主复制也存在明显问题:不同的group修改相同数据,容易造成写冲突.
2) 处理写入冲突
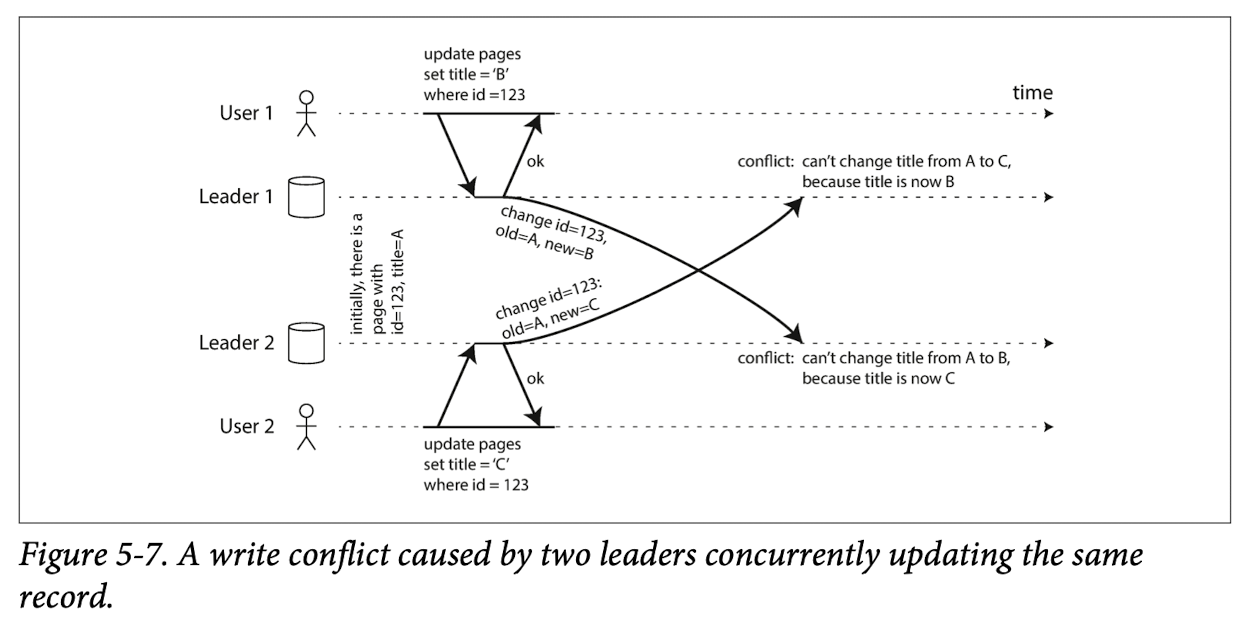
多主模式中的常见冲突如图所示.
下面考虑以下解决方式:
避免冲突
这是一种经常被推荐的方法.可以考虑对于某个数据的写入操作只会被路由到一个group中,就像6.824中shardkv的实现一样.或者保证特定的用户始终路由到同一个group,也就是说特定的用户对应特定的group.但是这种方法再需要对配置进行更改时,会出现问题.
收敛至一致的状态
在单主模式中,面临这种并发的写操作,只有最后一个(被leader接受的)写操作决定该数据的最终值.
但是在多主模式中,由于不再局限于一个leader,由无法确定一个全局的顺序表,所以导致图中的两个操作没有顺序之分,并不会出现单主模式中顺序大的覆盖顺序小的的情况.
一种思路是从这些冲突的写操作中只保留一个,比如说,每一个写入都有一个唯一的ID,其中最高者为有效的写入,其他的丢弃,或者为不同的副本有多个ID,其中ID高的副本上的写操作有效.但是这样丢会涉及到对某些写操作的丢弃,容易造成数据丢失.
或者考虑将这些值合并起来表示,或者引入额外的冲突记录,并且在应用层中编写处理冲突的代码.这也就是自定义冲突解决逻辑.
4.无主模式
这种模式相对比较复杂,暂且不做深究.