并发控制小叙
1) 锁管理器
对于数据库系统中的锁,有两个容易令人混淆的概念,一个事latch另一个是lock,两者的区别如下.

关于Lock的类型分为共享锁和排他锁.
锁管理器授予锁的条件并非简单地判断是否锁冲突,还会考虑锁请求的先后顺序,之所以考虑这个条件是因为这种情景:假设T2持有共享锁,而T1请求排他锁,T3也请求共享锁.其中请求次序为(T2>T1>T3),如果只是简单地根据锁的互斥条件加锁,就会导致T3有可能先于T1获得锁,如果在考虑有多个事务都需要加互斥锁,这个时候如果T1老是抢不到锁,就会导致“饿死”.因此锁管理器还有一个重要的加锁条件:在一个事务被授予锁之前,确保之前的请求被授予(处理).因此,一个加锁的请求不会被后面的请求阻塞.
2) 可串行化
对于一个事务序列,如果存在有一个调度S1等价于另一个S2,那么就可以说该调度S1是可串行化的.
如何定义“等价”是一个值得考虑的问题.下面有这几种等价的定义方式:
final state serializability
不同的调度,其写操作对相关数据的影响是相同的.但是对于这种状态的检查是相当困难的,依据定义将输出以及相关的数据进行比对不大现实.所以考虑下面的方法判断是否符合.
给定两个事务及其调度:

其中额外引入两个辅助事务,一个是T0,主要包含W操作,相当于将相关数据的初始值写入数据库,还有一个事务Tn主要包含R操作,意味着读取数据库相关数据的最终结果.因此根据调度T0,S,Tn的次序,建立数据流图可以得到如下的情况(对应了两种不同的调度S1,S2):
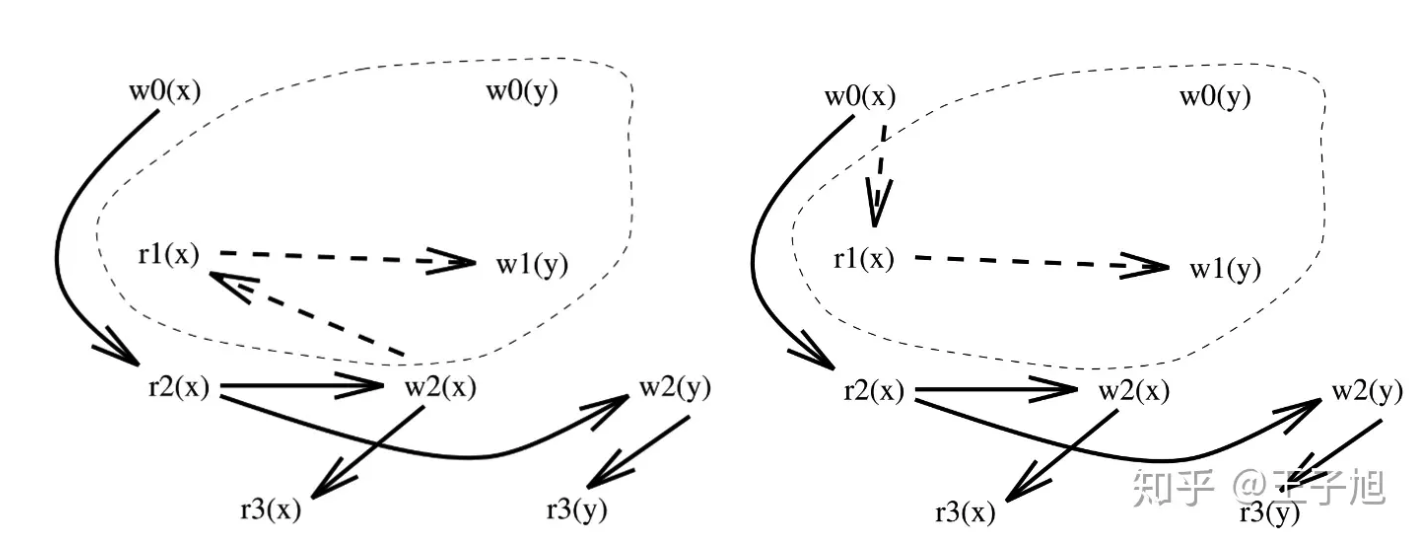
图引用自知乎(Transaction management:可串行性(serializability) https://zhuanlan.zhihu.com/p/57579023)
如果将不同调度数据流图中无法与Tn中对应的R节点联通的节点移除,所剩的图如果一致,那么可以保证两者实现了final state serializability.至此我们可以发现这种算法的实现复杂度比较高的,在数据库系统实现中很少采用.
view serializability
上面提到的一致性方式中,会讲事务视为一个黑盒,只关注事务处理的结果而非过程.而view这种串行化方案,则会关心具体的过程.
对于一个保证了final state serializability的事务序列,未必不存在问题.考虑下面的这种情况:
初始状态是 {x=5,y=5,z=2} .
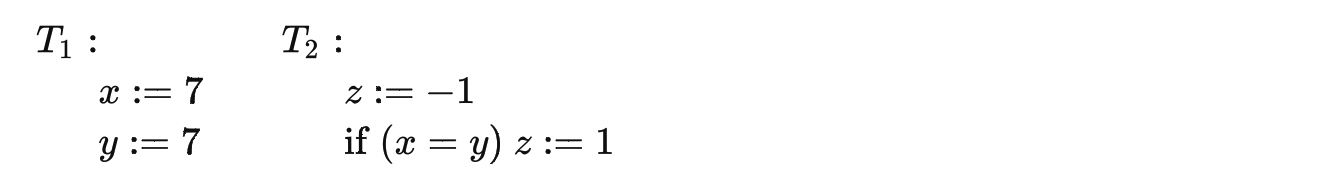
其中可以发现无论是按照T1,T2还是T2,T1都不会违背final state serializability,最终z都是1.但是在事务执行的过程中,比如T2,这两种调度在事务2读取x和y的结果是不相同的,前者是{7,7}后者是{5,5}.因此这种现象也就是:一个事务在不同的调度方案中,中途涉及到的读操作不能保证是一致的.
对于如何根据前面提到的模型判断view serializability:如果两个数据流图完全一致,那么可以保证view
serializability.可见,这种串行性更加严格,同时满足final state
serializability.
conflict serializability
倘若将事务对于数据的操作,考虑成一个个对于数据读写的序列,那么破坏ACID的关键原因在于,这些操作的顺序问题,如果某一对操作可以满足可交换律,这对操作可以不收调度顺序的影响.我们将这种操作定义为非冲突操作,否则就是冲突操作.
如何判断一对事务是否中途呢?
- 不属于同一个事务.
- 其中一个是写操作.
因此对于不同的调度,我们又有冲突等价的概念,如果两者对于冲突操作的调度顺序一样.
此外对于conflict serializability,也有相关的模型用来判断,对于一个调度,我们根据调度中事务之间的依赖关系来构造一个优先图.如果在图中存在环的话,就是违背conflict serializability的.
3) 两阶段锁
数据库的理想目标是实现可串行化.其中2PL机制就是为了维护这种性质而设计的.
简而言之就是将一个事务分为两个阶段,一个growing,一个shrinking.前者只能加锁,一旦出现第一个解锁行为,就会进入shrinking,该阶段不能再上新的锁.
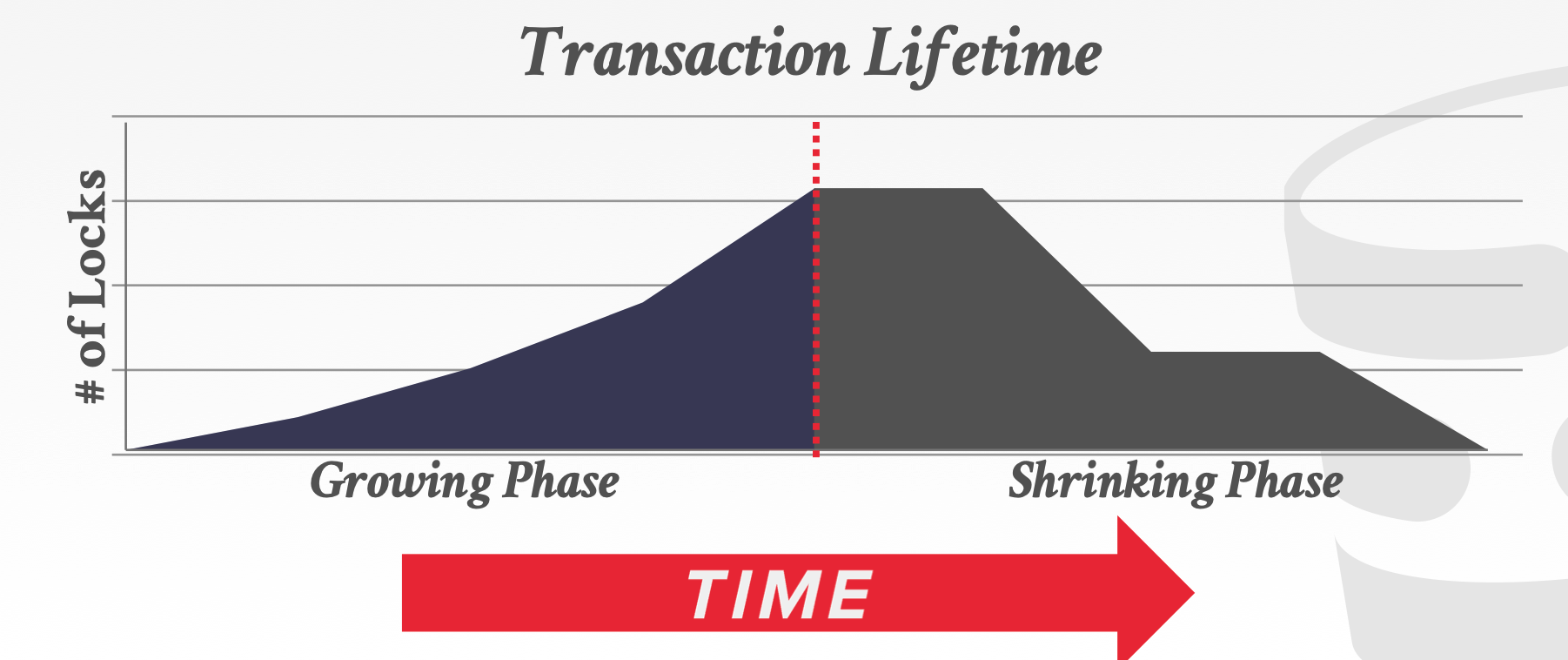
实现这种锁协议的目的是为了实现事务的可串行化调度,我们一般追求的是冲突可串行化,也就是前面所说的,可以构造出一个无环有向图.
关于2PL对于可串行化的保证,证明如下:

上述证明引用了文章Transaction management:两阶段锁(two-phase locking)
4) 事务隔离级别
提到事务隔离级别,首先考虑数据库系统中所涉及到的几种异常的数据访问情况,事务隔离级别将会深刻地影响锁管理器处理锁的方式以及上锁方式.
首先了解这几个基本问题:
- 脏读:某个事务更新一份数据,另一个事务读取到结果,但是后来更新该数据的事务又进行了回滚,这个时候读取到的结果是不正确的.
- 不可重复读:一个事务多次重复读取某个数据时,由于中间插入其他事务的写,因此导致前后读取的结果不一致.
- 幻读:事务1首先读取一些数据(比如说范围查询,或者查询整个表之类的),此时有事务2插入新的行或者列并提交,然而新加入的数据对于事务1来说并不知道.
其中有:
- 可重复读:只允许读取已经提交的数据,并且一个事务在多次读取时,中间不允许插入其他事务对该数据的更新.可以理解为不允许一个事务在多次读取某数据时有其他事务对该数据的更新介入.
- 已提交读:只允许读已经提交了的数据,不要求可重复读.
- 未提交读:这种事务的隔离级别下,一个事务的读操作可以随意进行,不考虑其他事务是否在进行一些与之冲突的操作.会出现:脏读,幻读或者不可重复读.
- 可串行化.前面提到过,一般要求冲突可串行化.
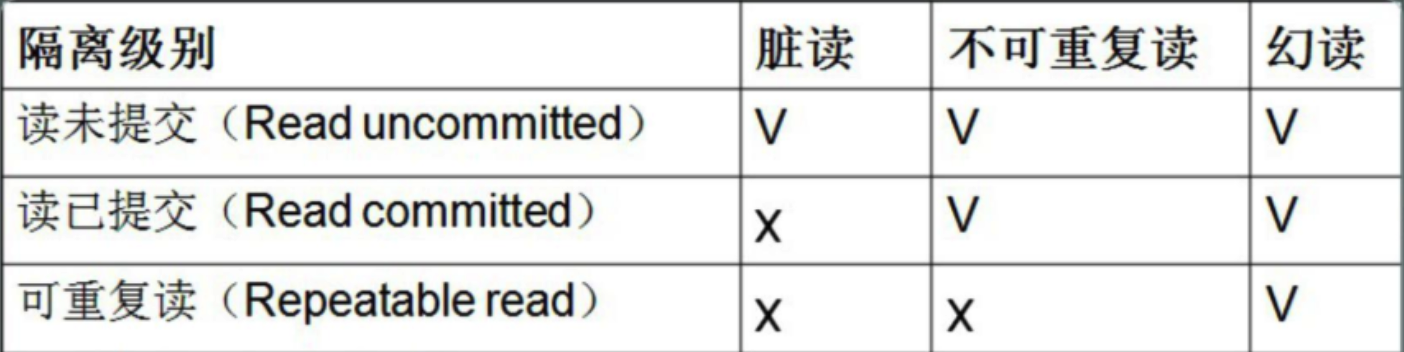
可串行化可以将这几个问题都避免.
其实这几个隔离级别顾名思义,”读未提交“意味着读取数据时,正在对该数据进行更新操作的事务还没有提交,对于一个没有提交的事务,要么最后ABORT,要么COMMIT,而其容易导致脏读就是因为不能保证没有ABORT的情况.而“读已提交”就保证了会被ABORT的事务不会被其他事务读到,因此避免了脏读.
5) 死锁预防策略
在这里只说明一下wound-wait算法.
《数据库系统概念》中提到,关于对于死锁预防,有两种实现思路,第一种是所有事务开始前就确定某一个不会出现死锁的次序,然后按照该顺序加锁.第二种则使用了抢占和回滚.比如在此要说的wound-wait算法.
简而言之,这种算法基于对每个事务赋予一个时间戳,该时间戳往往表示的是该事务创建的时间,时间戳大的是年轻事务,小的是年老事务.在这种算法下,不允许某个年轻事务先于一个年老事务获取对于某个数据的锁,一般实现为,如果一个年老事务在请求某一个锁时发现一个年轻的事务已经将该锁占有,那么年老事务将会终止并抢占此年轻事务.
这种算法的缺点在于容易出现不必要的回滚.
Reference
Transaction management:可串行性(serializability) https://zhuanlan.zhihu.com/p/57579023
《数据库系统概念》