《NanoLog: A Nanosecond Scale Logging System》论文简述
1. 导引
这一部分paper中先介绍了日志系统当下对于性能优化的要求,日志系统的开销比较大,这使得开发者需要在更加详实的系统记录和更高性能之间做取舍.
后来paper对比分析了集中方案.这几点对于我这个新手来说,很有意义.下面逐一介绍一下.
浅析同步日志系统
这是实现起来最最容易的一种模式,但是它的性能也是最差的.其中主要的代价源于格式化字符串和I/O,此外,主线程还需要调用内核来进行flush,这也是额外的代价.
常规的异步日志系统
主要只两个线程.主线程用于生成日志massenge并且写到缓冲区中,有一个专门用来做I/O的线程用来将缓冲区中的内容flush到磁盘上,两者之间构成了生产者与消费者模型,时常通过基于C++ std::function的方式传递任务.
其中主要的任务时,对于I/O任务的传递需要主线程额外做功,并且主线程如果生成日志的频率过快,使得I/O线程来不及消费,就会导致阻塞.这是使得开发者陷入一个权衡,究竟应该接受阻塞还是宁可抛弃一部分日志信息.关于第二种选择,有随机丢弃,优先级丢弃等方案,但都感觉强差人意.
Nanolog简介
Nanolog的设计基于两种想法.
第一个想法是,完全格式化的信息不一定需要放在程序运行时期生成,可以以某种不完全的方式暂时打印日志,人们可以等到需要查看时,将这种日志的形式转化成可读的,这种“不完全的方式”应该有更小的空间并相比字符串格式化来说开销更小.第二个想法是,日志消息一部分是静态的一部分是动态的,其中一些静态的信息在编译期间即可确定,即将静态信息进行编码(日志中的一大部分信息往往是冗余的,这些很多都是可以在编译期间就确定的,可以将一些静态信息进行编码并且只输出一次,当进行解码的格式化时再进行重新组合).
因此,可见这种设计思想即可以降低格式化字符串在运行时期的开销,又极大地减小了输出信息的占据的I/O带宽.
2. 核心设计
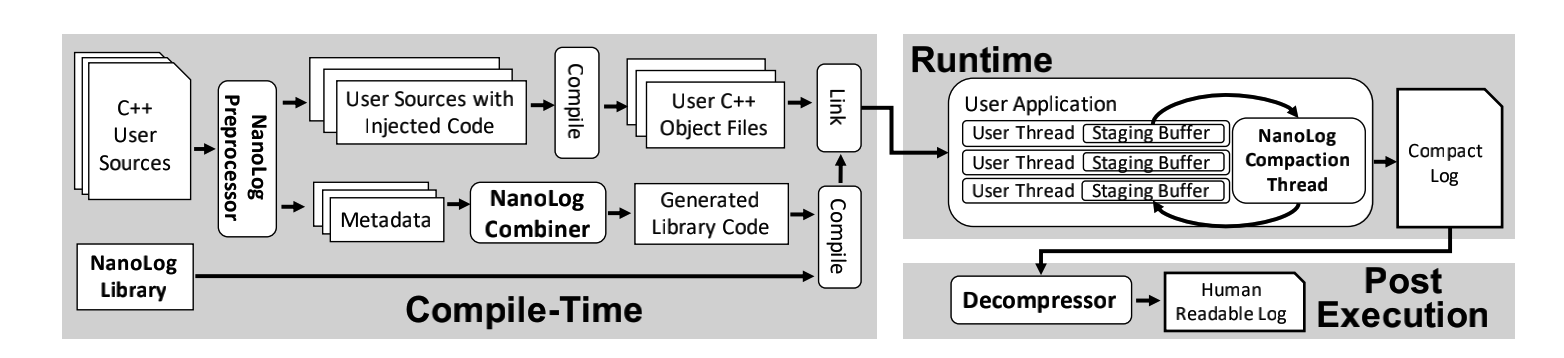
上面是宏观的一个系统结构图.
有三个部分,第一部分是一个预处理器,其作用在于将源代码中的日志语句中的进行重写,生成一个压缩函数和一个输出静态信息的函数.第二部分是运行时库,该库除了提供处理buffer的基础组件之外还有基于压缩函数和字典函数以二进制的形式输出日志信息.第三部分,将压缩的二进制日志文件与字典中记录的静态信息重新组合.
除此之外,其使用接口是相当简单的.即NANO_LOG(),是printf风格的.
下面分析一下其设计的细节.
1) 预处理器
就如同上面的系统图中所示.经过与处理器的处理之后,生成的是一个Metadata文件和被重写日志语句的源代码文件.此外还有一个Combiner用于根据元数据文件产生额外的C++源文件.最总运行时库文件、生成的库文件和用户的对象文件都被链接到一起.
重写日志语句
对于每个有NANO_LOG的语句,都会对其statements进行解析并且将其源代码中的日志语句替换成一种更快的编码.
这里提到的
statements究竟指的是什么呢?先留一个坑.
其中关于这种好处,paper中也提到了三点:
- 通过只记录动态信息减少I/O.
- 以压缩的形式来记录信息(主要是静态信息被压缩编码).
- 对于runtime来说,对代码替换要比原始的格式化字符串等动作要快得多.
对于常规的printf语句来说,printf语句的执行需要格式化字符串的处理,并且要将二进制形式的内容解释成某一种特定的类型.这都带来一些额外的开销.
稍微盘一下其处理方式的话,大概是避免了一般日志系统在运行期间将动态数据进行格式化字符串的过程,动态信息是被User Thread原模原样地加入到buffer中,后台压缩线程从buffer中取出这些信息进行压缩(我通过阅读log二进制文件发现,一般只有整型等类型的被压缩了),而动态信息之外的静态信息是被编码的.为了后来能够还原工作,对于静态信息需要记录格式化字符串的内容,其中的涉及到的参数类型,数量及其顺序.
省去了格式化(动态数据)字符串的动作.
生成函数
对于每个NANO_LOG都会生成对应的两个函数.一个是record,另一个是compact.这些函数对应了之前结构图中的Generated Library Code,专门汇集到了一个C++
代码文件中.简而言之,其中的作用,前者用了记录NANOLOG中的动态参数,后者用来压缩数据减少I/O开销.其中有示例伪代码如下:

前者是提供给一个buffer线程进行调用的,后者是提供给一个I/O线程的.(对应了后面runtime中的两种主要的工作线程).record的主要作用在于将NANO_LOG中的动态信息(只有NANOLOG的id这一条属于静态信息),加入到一个buffer中,compact的主要作用在于从buffer提取这些动态信息,并且进行压缩(通过我对日志的观察发现,一般只有整型的信息被压缩了).
此外关于record,其中唯一的静态信息一般是NANO_LOG语句的唯一标识符.其中一些动态数据类型,比如说name和tableId的数据类型,一般是在编译时期经过预处理器通过解析格式字符串完成的.因此在record的参数中也就确定了这些动态信息的参数类型.关于compact函数的话,可以根据将语句压缩成更加短小的语句实现对于I/O带宽的节省.其中在具体的compact方法中每个动态信息都基于之前所确定的数据类型的.
结合这两个函数可以发现,在runtime期间,基本上没有对于静态数据的处理.计算线程和I/O线程对于日志的直接接口就是record和compact,都是没有涉及到静态数据的(处理MANOLOG的标识符).
分析完这两个函数后,预处理器将NANO_LOG替换成record函数,并且同时在字典信息中保存了compact.
专门有一个字典条目,该字典条目记录了像文件名,行号,日志消息级别等静态信息.
关于Metadata文件,其中包含了compact函数以及相关的dictionary.其中dictionary包含了每个log语句中的静态信息,比如说文件名,行号,隔离级别,以及格式化字符串.
组合器
其输入是预处理器生成的Metadata,输出是一个C++
代码文件,并且还会和runtim
library并到一起参与后续的链接过程.关于这部分的作用,主要在于Metadata仅仅是一个个的数据条目,并不可以被后续的程序直接使用,所以经过组合器之后,会生成包含静态数据和Compact函数的C++
库文件,保证可以被链接到后续的程序中,被后续的程序所调用.
前面我们提到,Metadata中的相关的信息,包括compact函数及其dictionary.其中生成的源代码文件中有:每个NANOLOG对应的标识ID,由compact函数组成的函数数组.还有启动时运行的代码.
2) 运行时库
简而言之,划分了两种线程,第一个线程也就是User Thread,主线程通过调用record来将一些动态信息(还包括该NANOLOG对应的标识符号)写入到其buffer中,是buffer的生产者,另一个线程是一个I/O线程,从buffer中读取数据并且采用压缩的方式讲这些内容进行压缩,相比一般的I/O线程,其I/O效率比较高.计算与I/O相分离.
User Thread及其Staging Buffer
Staging Buffer的作为这个“生产者-消费者”模型中的桥梁,其中关键的challenge是如何实现无锁同步和缓存一致性.
为了实现无锁同步,采用了每个logging线程都有一个环形buffer,并且是单生产者和单消费者的模式.并且这种模式增强了并行程度.在环形队列中,通常消费者只移动head,生产者只移动tail,因此两个避免了潜在的竞争条件.
除此之外,还有缓存一致性的问题.其中主要的问题在于,如果一个线程需要获取buffer的当前空间大小,则需要同时访问head和tail两个指针,这容易导致竞争条件问题和一致性问题.对此做的处理是,比如说对于logging线程来说,并不是实时地对指针进行访问,而是缓存一个变量,直到可用空间被用完时,才会更新,对于I/O线程也是采用了类似的方式.
这里的缓存一致性处理说实话,我没有完全明白.
NanoLog Compaction Thread
对于这个I/O线程来说,我们最需要考虑的是,尽可能提高做I/O的效率,这使得不会出现消费者落后于生产者而导致生产者阻塞的现象.其实现方式就是压缩日志消息后再输出,由于输出的信息短了,因此I/O开销也就短了许多.也就是将格式化处理和时间排序安排到执行后的程序中进行处理.
I/O线程仅仅是以环形地方式扫描buffer,并且将压缩后的内容刷到disk上.(这种静态的处理机制可以避免竞争,但我不是太理解为什么)
常规I/O线程开销大的原因
格式化处理,并且维护日志的时间顺序甚至要对来自logging线程的日志进行排序.
其中的压缩方式,也就是体现在compact函数中的方法,也是非常高效的(一种自己开发的压缩算法).重点介绍一下对于整型变量值的压缩,其中发现在日志系统中出现的整型还是有很多高位用不到的,因此考虑将高位压缩掉,但是后续则需要知道被压缩了多少位.一般情况下,用4个字节表示一个整型数字,并且还有其中的一个字节用来表示是正数还是负数(这用来区分二义性问题).
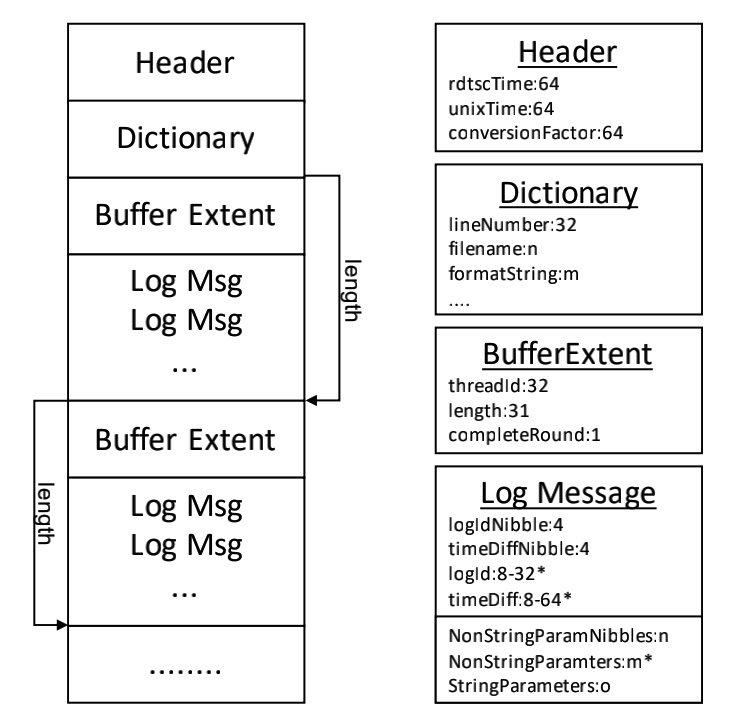
总体对于压缩的评价来说,一般情况下,如果不带任何动态的信息,其中所包含的压缩只是涉及到日志标识和相对于最后一个日志压缩的调用时间.可以缩小到3个字节.
3) 解码器
解码器的输入是通过Nanolog生成的log文件,其中解码器在解析每一个条目时,会根据其中的log id检索出之前保存的dictionary,尤其是从中得出来格式化字符串等静态数据,从而将日志中的动态数据进行合并,最终生成格式化的可读的字符串.
由于在User Thread有多个,每个都有一个自己的buffer,因此后台线程再从User Threads获取日志内容时会有日志的顺序难以保证的困难.也就是说,后台线程获取到User Threads的顺序和日志对应的事件所产生的顺序未必是一致的.
4) C++ 17机制的利用
C++
17中有一种编译时计算的机制,可以不额外地实现一个preprocessor.对此,我们再次明确,需要我们做的事:
- 生成
record和compact的优化代码文件. - 为每个调用了
NANO_LOG的语句,分配一个唯一的标识符号. - 对于源代码中的静态数据生成字典信息.
这些地方的实现,都是对于C++ 17的语法要求非常高的.
3. 局限性和总结
首先起局限性在于只能实现priintf风格的方式,实现不了类似于C++ Stream或者toString()的方式.虽然可以被其他语言调用执行,但是其缺点在于不能对动态生成和求值的任何日志进行优化.基于预处理器的方法也带了一些部署的不便.此外,paper中主要针对了本地文件系统的处理,对于一些远程存储系统,容易收到网络工作或者远程存储机制的限制.