cs143:PA2 && PA3,词法分析与语法分析
cs143实验中的词法分析和语法分析是比较简单的一部分,两者分别基于flex和bison完成,这两个工具分别是用来生成词法分析器以及语法分析器的代码文件的.比如说,如果我们写好cool.flex作为词法分析器的定义,其输出就是一个表示词法分析模块的.cc代码文件,这个文件可以和我们接下来实现的其他模块链接在一起,进而可以得到一个完整的词法分析程序.语法分析也是如此.
因此,在这这篇博客中,除了简单地分析一下实验中需要实现的内容(.flex和.y),我更想去整理这个子系统中其他模块的实现、以及bison和flex程序对外的接口、两个模块的交互方式以及开发中所用的工作流等等.
关于我的cs143实验代码地址.
1. 词法分析
语法分析的任务是将源程序划分为一个个的token,并确定其类型,还需要一些错误检查和报错.并且在解析token的时候构造相关的符号表.
1) 基于flex开发lexer的工作流
首先我们需要正确无误地编写.flex文件,然后调用一下命令,即可生成表示词法分析自动机的代码文件.cc
$ flex -d -ocool-lex.cc cool.flex也就对应makefile文件中的:
FFLAGS= -d -ocool-lex.cc
FLEX=flex ${FFLAGS}
cool-lex.cc: cool.flex
${FLEX} cool.flex其中flag分别表示-d即生成的代码文件是可以调试的,-o则指明了生成文件的名称,也就是cool-lex.cc.
之后就和写其他的C++程序一样,将每个.cc文件编译成.o文件,最后再链接在一起就好了.
lexer: ${OBJS}
${CC} ${CFLAGS} ${OBJS} ${LIB} -o lexer上面是PA2中的相关编译命令,其实${LIB}是可以不加,也就是-lfl.查阅《flex
&&
bison》可知,这个小型库定义了默认的main函数以及早期的默认yywrap函数.在很多词法分析器设计中,往往都会自己再定义一个main函数,很少使用fl库中使用的main函数,所以在这个PA2中即使将${LIB}删掉也是可以的.其中fl中定义的默认main函数大致如下:
int main() {
while (yylex() != 0);
return 0;
}其实一个词法分析器通过简单上面两步也就可以得到,其中第二部牵扯到的代码文件,有必要说一说,我们可以从中了解,除了flex生成的自动机代码文件.cc,要想构建一个完整的词法分析程序,还应该实现什么.
其中从makefile了解到其相关的源文件如下:
CSRC= lextest.cc utilities.cc stringtab.cc handle_flags.cc
CGEN= cool-lex.cc这一部分接下来详细介绍.其中还涉及到一个重要的头文件cool-parse.h,该文件可以有bison可以通过bison产生.
2) lexer相关的代码文件的实现
上面列举了生成lexer所需要编译链接的源文件.简要介绍其中的功能的话,其中leftist.cc定义了lexer程序的main函数,并且引用了从cool-lex.cc定义的接口cool_yylex().utilities.cc则定义了有关于字符串(token相关)的输出以及字符串转化相关功能的函数,handle_flags.cc和解析命令行参数有关,stringtab.cc最为重要,其中定义了idtable,inttable,stringtable三种符号表,符号表是一种保存identifier或者常量的数据结构,对于编译器后续阶段有重要的意义.除此之外,还有一个头文件cool-parse.h也很重要,其中定义了token的各种类型.
leftist.cc
这一部分在于定义了main程序:
int main(int argc, char** argv) {
int token;
handle_flags(argc,argv);
while (optind < argc) {
fin = fopen(argv[optind], "r");
if (fin == NULL) {
cerr << "Could not open input file " << argv[optind] << endl;
exit(1);
}
curr_lineno = 1;
cout << "#name \"" << argv[optind] << "\"" << endl;
while ((token = cool_yylex()) != 0) {
dump_cool_token(cout, curr_lineno, token, cool_yylval);
}
fclose(fin);
optind++;
}
exit(0);
}首先解析命令行参数,进而设置好flag相关的变量,然后打开(fopen)需要解析的源程序文件,
初始化curr_lineno变量,之后在while循环中,调用cool_flex,其返回值为token(一个表示该word类型的整型),在cool-parse.h有所定义.随后调用dump_cool_token打印该token的类型等信息.由此可以再次明确,
cool_yylex()的返回值是一个表示token类型的int,这些有关与类型值的定义取决于我们
**该文件(FILE *fin)是如何和cool_yylex函数建立关系的呢?**
在开发者不做任何指定的情况下,是从标准输出中读取的,但真正的编译器往往需要从文件中读取.在flex中,通过定义好FILE *fin即可指定,所需要的解析的源文件,可见于leftistcc.即:
extern FILE *fin;
stringtab.cc
这一部分是符号表相关的实现.在cool语言中,所涉及到的符号表有三种:
extern IdTable idtable;
extern IntTable inttable;
extern StrTable stringtable;符号表内部是一个链表.提供增加,遍历,查找等功能.由于在这里StringTable是一个模版类,因此可以套用不同的类型比如说IdEntry,StringEntry,IntEntry等.这几个Entry主要是在相关的方法上有多态的不同,但是核心都表示的是字符串.
template <class Elem>
class StringTable
{
protected: // protect一般只是结合继承进行使用
List<Elem> *tbl; // a string table is a list
int index; // the current index
public:
StringTable(): tbl((List<Elem> *) NULL), index(0) { } // an empty table
// The following methods each add a string to the string table.
// Only one copy of each string is maintained.
// Returns a pointer to the string table entry with the string.
// add the prefix of s of length maxchars
Elem *add_string(char *s, int maxchars);
// add the (null terminated) string s
Elem *add_string(char *s);
// add the string representation of an integer
Elem *add_int(int i);
// An iterator.
int first(); // first index
int more(int i); // are there more indices?
int next(int i); // next index
Elem *lookup(int index); // lookup an element using its index
Elem *lookup_string(char *s); // lookup an element using its string
void print(); // print the entire table; for debugging
};其中这几个Entry都继承自Entry,这个类核心就是一个string,其中相关实现如下:
class Entry { // 维护了一个字符串,以及和这个字符串有关的信息
protected:
char *str; // the string
int len; // the length of the string (without trailing \0)
int index; // a unique index for each string
public:
Entry(char *s, int l, int i);
int equal_string(char *s, int len) const;
bool equal_index(int ind) const { return ind == index; }
ostream& print(ostream& s) const;
char *get_string() const;
int get_len() const;
};除了字符串相关的部分,还有一个变量index,表示的是在其符号表中所处的index.其实在这里我想,如果我自己也要实现一个符号表,是不是只要“string+index”就可以了?所以到此也可以说,即使是Int常量,其底层也是通过字符串的方式记录在符号表中的.
也可以通过这个明确,我们需要在词法分析阶段收集Int常量,String常量,以及Identifier变量.将其加入到对应的符号表中.至于收集这些东西的作用是什么,将会在后续分析.
此外关于Entry的指针,被定义为Symbol.
typedef Entry *Symbol;cool-parse.h
这其中既涉及到了parser所需要用到的一些内容,也有lexer的.其中lexer所需要用到的主要是各种token类型的定义.如下所示:
enum yytokentype {
CLASS = 258,
ELSE = 259,
FI = 260,
IF = 261,
......
NOT = 281,
LE = 282,
ERROR = 283,
LET_STMT = 285
};如此之外,还有与之相等的宏定义.这些都是与后面的flex文件以及cool_yylex相呼应的.
至此,我们可以简单的做一个总结,实现一个词法分析器所需要的工作:
- 定义main例程.其中需要绑定FILE *fin,解析命令行参数并设置相关的flag变量,在一个while循环里调用从flex生成的yylex函数,并将返回的结果(token)进行处理,比如说dump输出.
- 定义词法分析所需要用到的token,一般是整型类型.
- 实现符号表及其相关接口,比如说look,add,iterator的等等.以及符号表相关的Entry.
- flex文件本身的编写.
3) flex文件的编写以及flex相关机制
这一部分是PA2所要求让我们实现的地方,其中具体的实现代码可见:https://github.com/YfsBox/cs143/blob/master/assignments/PA2/cool.flex.
实现这一部分除了了解flex语法,还要了解正则表达式,词法分析程序所需要涉及到的数据结构(比如所符号表),还有flex框架下一些给我们的提供的接口和变量.
首先介绍一些常用语法:
- 状态条件的定义与使用.比如说,我们可以通过%x
COMMENT,定义一个状态条件COMMENT,默认的状态条件是INITIAL,也就是0.当我们当前处理的token需要状态条件转移的时候,(比如说COMMENT条件)我们需要调用BEGIN(COMMENT).状态条件将会影响正则表达式的匹配,只有能够匹配某个正则表达式规则的前提是,当前状态符合该正则表达式的状态条件.将该正则表达式前面加上
<COMMENT>(仍然是以COMMENT为例)表示其匹配条件.此外,也可以采用这种形式,也就是将状态条件提前到最前面:
<COMMENT>{
{COMMENT_BEGIN} {
nest_comment_cnt++;
}
{COMMENT_END} {
nest_comment_cnt--;
if (nest_comment_cnt == 0) {
BEGIN(INITIAL);
}
}
......
}- 每个规则,都需要设置返回值,其返回值与yylex函数的返回值对应,其返回值一般为该token的类型.
- 当词法分析器匹配一个token的时候,token对应的字符串保存在yytext中,其中的长度为yyleng变量.
#define yylval cool_yylval // 用来描述第一行和最后一行的信息以及column的信息,这个是需要我们进行维护的
#define yylex cool_yylex- 关于yylval将用于被后续的语法分析器(bison)读取,这个变量可以代表当前所匹配的token的语义值,在词法分析的学习中,我们可以知道一个词法单元有两个字段,一个是token的类型,另一个是该token具体的值,很多类型的token往往不需要设置值,比如说while,class,+等,但是对于typeid,const等类型的token,我们除了需要确定其token类型属于STR_CONST还是INT_CONST,还需要确定其值,因此在PA2中,对于INT_CONST,STR_CONST等类型的token还对其yylval中的symbol进行了设置,在PA2中,有:
#define yylval cool_yylval
extern YYSTYPE cool_yylval;
typedef union YYSTYPE // 定义了一个联合体
#line 46 "cool.y.cc.cc"
{
Boolean boolean;
Symbol symbol;
Program program;
......
Expression expression;
Expressions expressions;
char *error_msg;
}其中YYSTYPE是一个联合体.
2. 语法分析
词法分析器接受来自语法分析器的结果,根据所定义的语法规则匹配出一个个语法单元,这些语法单元将会作为AST树中的节点,其最终结果是一个AST.
1) 基于bison开发parser的工作流
首先使用bison根据.y文件生成cool-parse.cc.
cool-parse.cc cool-parse.h: cool.y
bison ${BFLAGS} cool.y
mv -f cool.tab.c cool-parse.cc其中对应的命令也就是:
$ bison -d -v -y -b cool --debug -p cool_yy cool.y其中-d表示的是,其输出还会产生一个头文件,也就是cool-parser.h(其实真正生成的cool-parser.h).-y表示的是仿照POSIX
yacc的方式进行解析,-b则指明了所生成文件的前缀.-p指定了一些外部符号的前缀,比如说cool_yyparse.
关于cool-parser.h在之前的flex文件中也被include,这个文件中涉及到了token类型的宏定义以及枚举类型,因此我们往往不需要逐个地手写这些东西,在bison文件中定义好token,就可以生成包含这些token宏定义的头文件.
然后生成parser:
parser: ${OBJS}
${CC} ${CFLAGS} ${OBJS} ${LIB} -o parser其模式与lexer中的类型,只不过涉及到的源文件要多一些,如下所示:
CSRC= parser-phase.cc utilities.cc stringtab.cc dumptype.cc \
tree.cc cool-tree.cc tokens-lex.cc handle_flags.cc
CGEN= cool-parse.cc2) parser相关的代码实现
上面列举出来了parser所涉及到的源文件,简要说明其中所涉及的内容.其中parser-phase.cc定义了parser的main函数,utilities.cc,stringtab.cc,handle_flags.cc和前面提到的一样,dumptype.cc用于打印ast中的各种类型的语法单元(比如说Expression,formal等等).tree.cc,cool-tree.cc定义了与AST相关的数据结构与操作.tokens-lex.cc则是之前通过flex所生成的文件.
parser-phase.cc
定义了parser的main函数,main函数首先处理命令行参数并且设置对应的flag变量,然后调用cool_yyparse执行词法分析(该函数来源于cool.y所生成的代码),其中omerrs是一个用来统计错误数量的变量,如果不等于0说明有语法上的错误.之后将ast打印出来.
int main(int argc, char *argv[]) {
handle_flags(argc, argv);
cool_yyparse();
if (omerrs != 0) {
cerr << "Compilation halted due to lex and parse errors\n";
exit(1);
}
ast_root->dump_with_types(cout,0);
return 0;
}关于main函数如何接受来自lexer的结果的,首先其输入流被设置为stdin,也就是说parser从标准输入接受输入,如下:
FILE *token_file = stdin; // we read from this file当在这个实验需要使用parser时,会通过管道从lexer的输出结果传递到parser中.因为在cs143中所实现的编译器最终是通过一个胶水脚本将各模块的程序通过管道粘连在一起的.比如:
#!/bin/bash
./lexer $1 | ./parser | ./semant | ./cgen此外,在该文件中还有ast_root和parse_results.这两个数据结构会在进行语法分析的时候进行构建.
Program ast_root; /* the result of the parse */
Classes parse_results; /* for use in semantic analysis */tree.cc 与 cool-tree.cc
这一部分涉及到AST的核心实现.其中关于ast的节点定义有比较复杂的继承体系,大致如下:
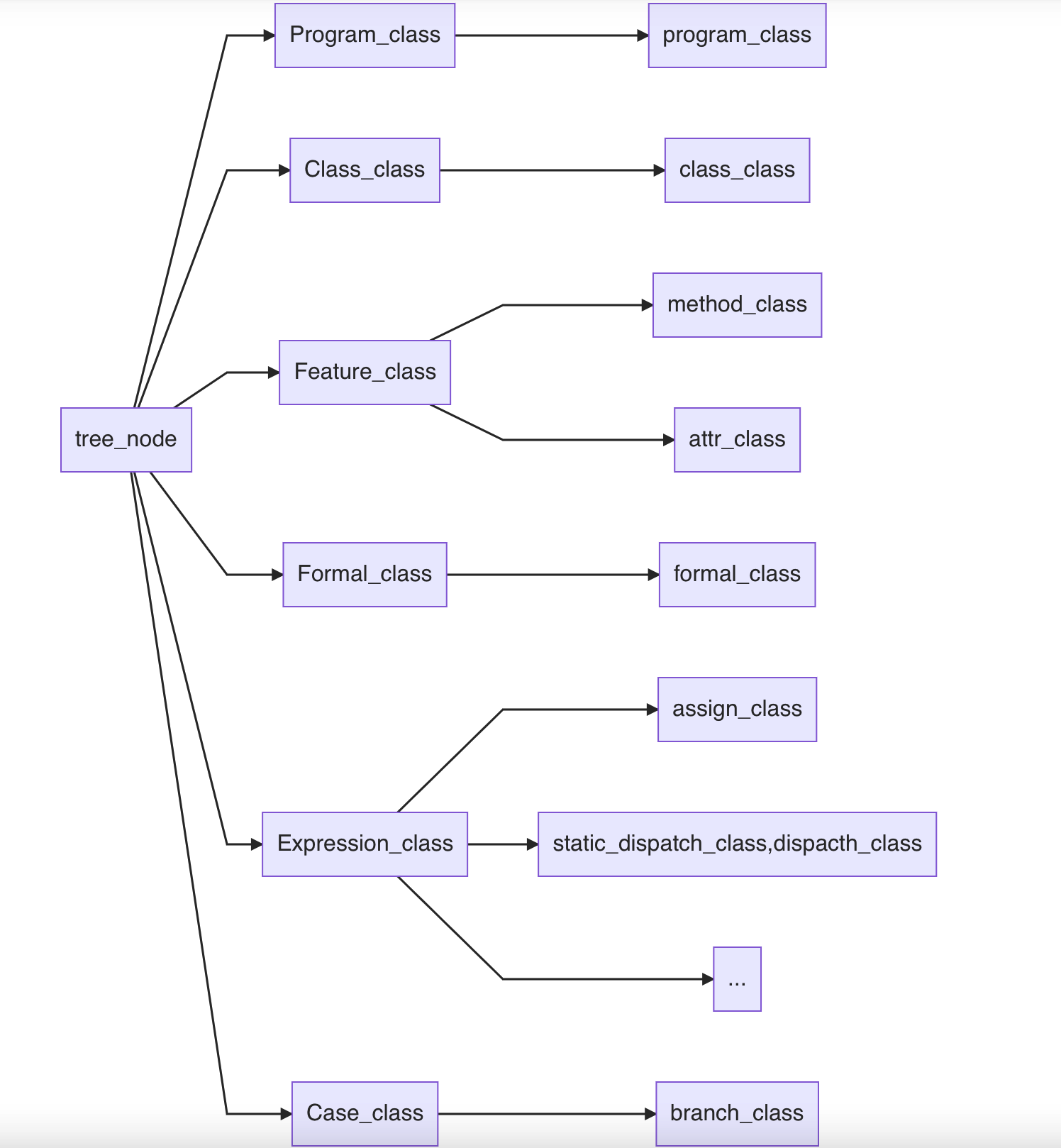
途中的省略号表示的是还有no_expr_class,object_class,new__class,string_const_class等类也直接继承自Expression_class.关于ast的结构,其树根是一个Program_class,其下维护着一个个Class_class(以list的形式)作为树的几大分枝.在每一个Class_class下面又维护着几个Feature(包括attr_class和method_class),至于method_class下面又有Formals(参数),expr(函数体)等变量.其定义如下:
class method_class : public Feature_class {
protected:
Symbol name;
Formals formals;
Symbol return_type;
Expression expr;
public:
method_class(Symbol a1, Formals a2, Symbol a3, Expression a4) {
name = a1;
formals = a2;
return_type = a3;
expr = a4;
}
Feature copy_Feature();
void dump(ostream& stream, int n);
#ifdef Feature_SHARED_EXTRAS
Feature_SHARED_EXTRAS
#endif
#ifdef method_EXTRAS
method_EXTRAS
#endif
};此外,对于ast树中的节点,通常以list的方式维护其子节点,因此对于tree_node也有list_node相关的定义.
3) bison相关文件的编写
在bison文件中,我们需要根据语法规则定义语法匹配的表达式,以及表达式匹配时对应的动作,这些动作主要在于构造某种类型ast的节点,此外构造节点往往需要一些参数(比如说method需要formal),对于这些参数往往需要递归地求解.
首先我们需要明确一下bison文件的主要编写语法:
- %token用来声明终结符,所以至此我们也可以说,lexer是一个划分并将一个个终结符归类的操作.在.y文件中定义好一个个token,将会在bison产生的header文件中以宏定义和枚举的方式呈现,因此该header可以被flex文件引用.
- 还有一类特殊的token,如下:
%token <symbol> STR_CONST 275 INT_CONST 276
%token <boolean> BOOL_CONST 277
%token <symbol> TYPEID 278 OBJECTID 279这对应了我们之前所讲到需要设置yylval的token类型.
%union,一般情况下yylval的类型是int,但是我们往往需要多种类型的yylval,因此需要定义一个联合体.
%type,用于定义语法规则中的非终结符及其返回值类型(union中的某一种).
因此,我们可以说,我们需要定义%token来确定需要用到哪些token(终结符),哪些token需要指定某种yylval,在非终结符中有哪些类型的yylval,通过%type来声明某种非终结符的yylval类型.比如说:
%type <program> program
%type <classes> class_list
%type <class_> class
%type <features> dummy_feature_list
%type <feature> dummy_feature
%type <formals> dummy_formal_list
%type <formal> dummy_formal
%type <expression> expr
%type <expressions> exprs
%type <expressions> block
%type <expression> let_expr
%type <cases> case_expr_list
%type <case_> case_expr在定义具体的匹配规则时,比如说feature相关的规则:
dummy_feature: OBJECTID ':' TYPEID ';' {
$$ = attr($1, $3, no_expr());
}
| OBJECTID ':' TYPEID ASSIGN expr ';' {
$$ = attr($1, $3, $5);
}
| OBJECTID '(' ')' ':' TYPEID '{' expr '}' ';' {
$$ = method($1, nil_Formals(), $5, $7);
}
| OBJECTID '(' dummy_formal_list ')' ':' TYPEID '{' expr '}' ';' {
$$ = method($1, $3, $6, $8);
}
;
dummy_formal_list: dummy_formal {
$$ = single_Formals($1);
}
| dummy_formal_list ',' dummy_formal {
$$ = append_Formals($1, single_Formals($3));
}
;
/* formal */
dummy_formal: OBJECTID ':' TYPEID {
$$ = formal($1, $3);
}
;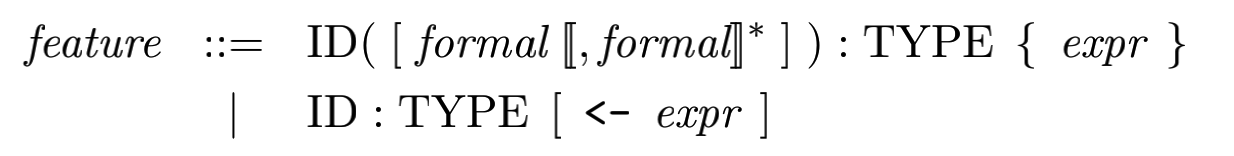
其中$$表示的该非终结符的yylval.$1, $2等表示的是取某个参数的yylval.此外,递归是定义bison规则用到的主要方法.关于bison规则的编写,我认为不算是什么难事,因为cool-manmal中对于语法规则的形式化表示是非常清晰全面的,所以说按部就班地照着manmal中的语法规则并且了解相关数据结构的api写就成了.