mit 6.824 分布式系统:lab2 raft
6.824 lab2
已经完成lab2,经过500次以上连续测试,无一FAIL.
这篇博客除了整理实现的思路之外,还会分析一下测试中的情景,结合这些情景来加深对于raft的理解.
1.实现要点
1) 总体框架:状态机
参照raft的论文可知,其中的关于每一个节点的状态及其触发事件是非常清晰明了的,所以在此就很容易采用状态机的总体框架进行编程.
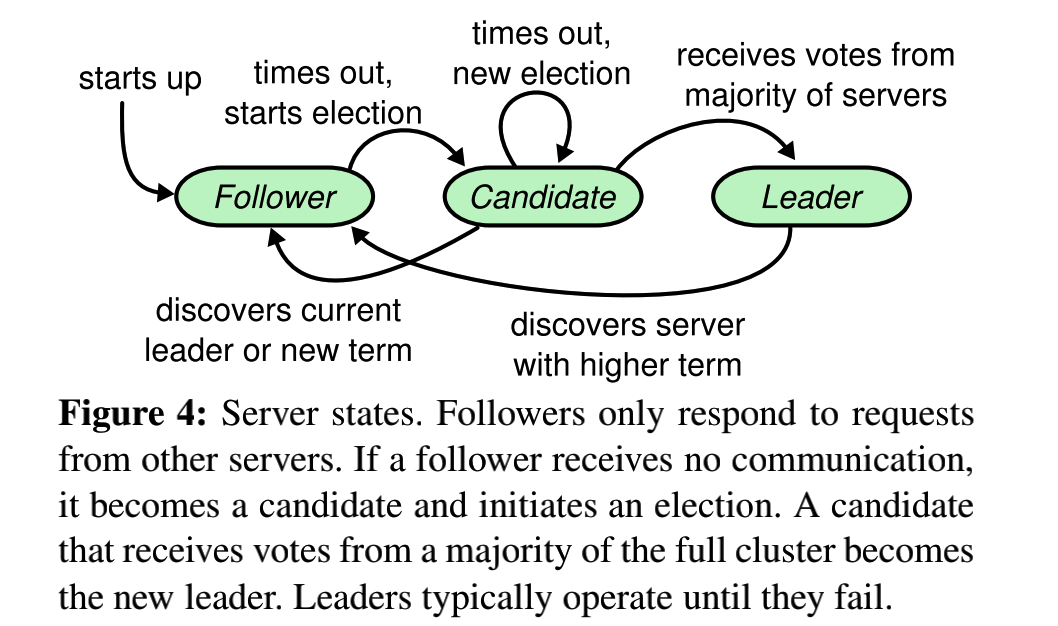
很容易就划分为三个状态:follower,candidate,leader.
const (
followerState = 1
candidateState = 2
leaderState = 3
)
func (rf *Raft) Running() {
for rf.killed() == false {
rf.doMachine()
}
rf.mu.Lock()
rf.persist()
rf.mu.Unlock()
}其中Running可以视为main函数中的主线程.用来不断地做状态的变化.其中doMachine是一个switch分支,内部对应了各种状态的动作.
func (rf *Raft) doMachine() {
rf.mu.Lock()
switch rf.state {
case followerState:
{
rf.voteForId = -1
rf.persist()
DPrintf("The %v state is follower,the log num is %v\n", rf.me, len(rf.Logs))
rf.mu.Unlock()
rf.ticker()
rf.mu.Lock()
rf.state = candidateState
rf.mu.Unlock()
//DPrintf("超时了进入candidateState\n")
}
case candidateState:
{
DPrintf("The %v state is condidate,the term is %v,the log num is %v\n", rf.me, rf.currentTerm, len(rf.Logs))
rf.mu.Unlock()
nextstate := rf.sendRequestVote(rf.me)
rf.mu.Lock()
rf.state = nextstate
rf.mu.Unlock()
rf.Start(nil)
}
case leaderState:
{
DPrintf("The %v state is leader,the term is %v\n", rf.me, rf.currentTerm)
rf.voteForId = -1
loglastid := rf.getLastLogId()
for i := 0; i < rf.peersNum; i++ {
rf.NextIdMap[i] = loglastid //如果在最初,就是1
rf.MatchIdMap[i] = 0
}
rf.mu.Unlock()
rf.BeatLeader()
rf.mu.Lock()
rf.state = followerState
rf.mu.Unlock()
}
default:
rf.mu.Unlock()
}
}其中follower状态的所做的动作就是ticker,ticker是一个用来周期性地检查心态的函数,只要心跳不过期,ticker就会不断地处于循环中,当心跳过期,进而就会跳出循环,而当follower结束时,它的下一状态是唯一的,也就是candidate.而对于candidate来说,其核心的任务也就是选举(sendRequestVote).但是其下一状态并不是确定的,我在实现sendRequestVote的时候,其返回值就是下一个状态.因为相对于leader和follower,candidate的状态并不是确定的,如果获得了大多数选票则是leader,如果接收到了来自leader的心跳,则退化成follower,如果选票不足就继续是candidate.
在doMachine中,其中关于mutex的使用也是值得注意的.这个函数运行在Running中,并不是唯一正在运行的协程,还有Applier等.不止一个协程需要读取或者改变state.所以在switch中需要上锁.并且还要注意解锁的时机,因为像ticker,sendRequestVote等函数内部都含有对锁的占有与释放,所以在调用这些函数之前都需要先解锁,否则会造成死锁.如果将这些函数设计成只在外部上锁,而内部无锁怎么样呢?更是不可以的,因为这些函数内部含有阻塞动作,比如说ticker中的sleep等,更会导致死锁.
除此之外,对于当状态需要变化成follower和leader时都需要刷新voteForId.
2) RPC的处理技巧
我最初在实现RPC处理的时候吃了不少苦头.我在最初的处理中,会对于每个RPC操作都开一个协程进行处理,这样会导致在测试用例中出现协程数过多的错误.
其实现的基本思路,就是将call动作单纯地封装于一个协程中,并且协程借助一个channel与主协程(调用该协程的协程)进行通信,此外在后来的测试用例中,会给RPC动作增加延迟,所以为了防止RPC过长时间地阻塞下去,还要使用select增加一个分支,设定一个超时时间.如下所示.
其中关于过期RPC的处理相当重要,这出现于每个RPC返回后,检查结果的时候.就如下所示:
if rf.state != leaderState || args.Term != rf.currentTerm || result.Term == -1 {
return
}其中的rf.state != leaderState || args.Term != rf.currentTerm就体现了对于过期情况的判断与检查.
3) applier类似于一种滑动窗口
其中对于raft就像tcp一样,是一种具有可靠性保证的协议.
4) Fast Backup
在leader将自己的log发送到follower节点之前,需要确保寻找到一个一致点,也就是leader的nextId数组所维护的数据.最原始的实现是,对于每次失败的appendEntry,leader接收到失败的相应后会将对应的nextId进行减1,由于appendEntry是靠心跳进行驱动的,所以如果每次都只是-1.当数据量大到一定程度之后,则需要等待好几个心跳周期才能找到一致点,这样耗费的时间较长,所以应当采取某种方法进行优化.
在这里采取的优化方法其实现如下:
reply.LogSuccess = false
tmpterm := rf.getEntryById(args.PreLogId).Term
if !have {
reply.NextIndex = loglastid
} else {
for idx := args.PreLogId;idx >= rf.Logs[0].Index;idx -= 1 {
if rf.getEntryById(idx).Term != tmpterm {
reply.NextIndex = idx
break
}
}
}这段代码出现在,follower接受心跳包,关于log一致比对失败的分支中,如果是!have,也就是follower的最高日志小于所收到的心跳包中的nextId的情况,这种情况直接将reply.NextIndex设置成此follower的当前最高索引.如果不是这种情况,而是因为对应项的任期不同所导致,那么就是从此index向后回退,直到找到一个任期于此相等的index为止.
之后在leader收到之后,会将对应的nextId设置成reply中的nextId.
其中根据任期来比对一致性的原理是什么呢?
任期(term)使整个系统中的逻辑时钟,一个term内就会对应一个唯一的leader,如果任期不一样则说明这个log项不一致.
5) index的改造
由于lab2D需要实现日志紧缩.日志紧锁要求每个节点的日志,一旦达到一定的大小,就要将超出的部分(已经应用的抛弃).所以在这个时候就不能够用Log数组的长度去求取日志的最后一个索引,也不能直接根据数组index求取log项的索引,因此需要再增加一层抽象,这样可以适应于加入日志紧锁之后的要求.
其实现如下:
func (rf *Raft) getEntryById(index int) Log {
logslen := len(rf.Logs)
if index <= rf.Logs[0].Index {
return rf.Logs[0]
} else {
for i := 1; i < logslen; i += 1 {
if rf.Logs[i].Index == index {
return rf.Logs[i]
}
}
}
return Log{}
}
func (rf *Raft) getEntrys(preindex int) []Log { //获取[preindex+1:...)
if preindex+1 <= rf.Logs[0].Index {
//return rf.Logs //这种情况就不应该存在,应该
return nil
} else {
idx := 0
loglen := len(rf.Logs)
for idx = 0; idx < loglen; idx += 1 {
if rf.Logs[idx].Index == preindex+1 {
break
}
}
return rf.Logs[idx:]
}
}其中getEntrys中的第一个分支中的情况就是:follower中最新的情况已经是leader已经抛弃,生成snapshot的部分.这种情况则需要leader向该follower发送快照,然后根据快照进行更新.
2.实现过程
1)选举
2) 心跳
我最初在做lab2A的时候比较短视,将心跳和appendEntry是分离着写的,但是后来合并在了一起.因为本质上,appendEntry是靠心跳驱动的,也就是说,心跳承包了比对一致点和追加日志项的功能.
而start只是通知leader,有一个新的log到来,并且将其加入到本地.至于start中是否要进行广播log,这个做不做都可以,如果做广播的话,还是会快一点.但耗费的rpc相对而言也会多一些.
其实现如下:
func (rf *Raft) BeatLeader() {
timeout := 50
for rf.killed() == false {
rf.Start(nil)
rf.mu.Lock()
if rf.state != leaderState {
rf.mu.Unlock()
break
}
rf.mu.Unlock()
time.Sleep(time.Duration(timeout) * time.Millisecond)
}
//DPrintf("The %v back to follower......\n", rf.me)
}以上循环,结合前面的状态机可知,这是在leader状态的主循环.在此,虽然Start中是nil,在我的设计中,如果是nil,将不会追加任何新的log到leader中.只是相当于普通的心跳.下面是关于Start的实现.其中调用BroadCastLog,用来广播log.
func (rf *Raft) Start(command interface{}) (int, int, bool) { //一定要确保start不要是并行的,应该是线性的
index := -1
term := -1
rf.mu.Lock()
isLeader := (rf.state == leaderState)
rf.mu.Unlock()
if isLeader { //将command加入
rf.LogMu.Lock()
rf.mu.Lock()
term = rf.currentTerm
//index = len(rf.Logs) //要进行追加的index
index = rf.getLastLogId() + 1
rf.mu.Unlock()
//fmt.Printf("The leader log: %v,get the cmd %v\n", rf.Logs, command)
rf.BroadCastLog(index, term, command)
rf.LogMu.Unlock()
}
// Your code here (2B).
return index, term, isLeader
}关于Log的广播的实现.其中cmd表示新增log的内容,而index则表示最后一个log的index.之前提到过有nil充当普通心跳的情况,这种情况下不进行append,并且还对于之前求的lastid进行-1,这样才保证lastid是最后一个log.之后再除了自己之外,进行AppendEachLog.
func (rf *Raft) BroadCastLog(index int, term int, cmd interface{}) {
rf.mu.Lock()
if rf.state != leaderState {
rf.mu.Unlock()
return
}
lastid := index
if cmd != nil {
rf.Logs = append(rf.Logs, Log{Index: index, Term: term, Cmd: cmd})
rf.persist()
} else {
lastid -= 1
}
DPrintf("The leader %v log num is: %v,get the cmd %v\n", rf.me, lastid, cmd)
loglastid := rf.getLastLogId()
rf.MatchIdMap[rf.me] = loglastid
rf.mu.Unlock()
for i := 0; i < rf.peersNum; i++ {
if i != rf.me { //对于不等于的就发送这个
go rf.AppendEachLog(lastid, i)
}
}
}其中AppendEachLog是比较核心的部分.首先要做的就是构造args,其中重在求取PreLogId,PreLogTerm,Entry.前者直接根据NextId中的内容得到其中的日志项即可得出.然后对于Entry则是从该点之后的一个slice.在这里我们可以看出,NextId用来寻找leader与某个follower的一致点,并且这个数组以一种试探的方式,在一次次心跳的驱动下,最终找到真正的一致点.找到之后,完成log的追加.相比于matchId,match则真实跟踪了每个follower持有日志的情况,根据matchId的数组,leader可以确定更新commitId.
如果求出的Entry是nil,也就是rf.getEntrys(prelogid)为nil的情况,这种情况属于需要发送快照的情况.所以不继续往下进行RPC调用,而是调用SendSnapshot.
之后调用RPC之后,对于结果进行判断,在第一个分支中就是因为任期而出问题的情况,即!result.Success && result.Term > rf.currentTerm,其中Success在我的实现中表示的是因为leader任期小于follower的情况,这个时候则需要更新自己的状态和任期.
下面的两个分支,分别对应了日志比对成功和不成功的情况,成功的话,同时更新NextId,Match数组,并且进行updateCommit.否则就采用Fast Backup更新NextId.为下一次比对做准备.
func (rf *Raft) AppendEachLog(lastid int, index int) {
rf.mu.Lock()
if rf.state != leaderState {
rf.mu.Unlock()
return
}
prelogid := rf.NextIdMap[index]
args := RequestBeatArgs{
Term: rf.currentTerm,
Index: rf.me,
PreLogId: prelogid,
PreLogTerm: rf.getEntryById(prelogid).Term,
Entry: rf.getEntrys(prelogid),
LeaderCommit: rf.commitId,
}
rf.mu.Unlock()
if args.Entry == nil {
rf.SendSnapshot(index)
return
}
ch := make(chan ReponseBeatReply)
var result ReponseBeatReply
go rf.LimitCallBeatReponse(index, &args, ch)
result = <-ch
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != leaderState || args.Term != rf.currentTerm || result.Term == -1 {
return
}
if !result.Success && result.Term > rf.currentTerm { //如果无效,就要更新自己了
rf.currentTerm = result.Term //更新term
rf.persist()
rf.state = followerState
DPrintf("the leader %v back to follower,because %v term %v\n", rf.me,index,result.Term)
return
}
if result.LogSuccess { //如果成功
DPrintf("The leader %v get a logsuccess from %v\n", rf.me, index)
if lastid >= rf.NextIdMap[index] {
rf.NextIdMap[index] = lastid
}
if lastid >= rf.MatchIdMap[index] {
rf.MatchIdMap[index] = lastid
}
rf.UpdateCommit()
} else if len(args.Entry) != 0 { //如果失败,但是不能是超时的话
DPrintf("The leader %v get a lognot success from %v\n", rf.me, index)
rf.NextIdMap[index] = result.NextIndex
}
}至于此RPC的响应的实现,我的代码又丑又冗长,所以这里不想都贴上去了,感觉也没有太多好说的.在末尾需要判断是否更新其commitId.如下所示:
if args.LeaderCommit >= rf.commitId { //这种情况下说明leader已经提交了,那么follow自己也应该提交了
if args.LeaderCommit < loglastid {
rf.commitId = args.LeaderCommit
} else {
rf.commitId = loglastid
}
}3) applier
4) 日志紧缩与快照
3.测试分析
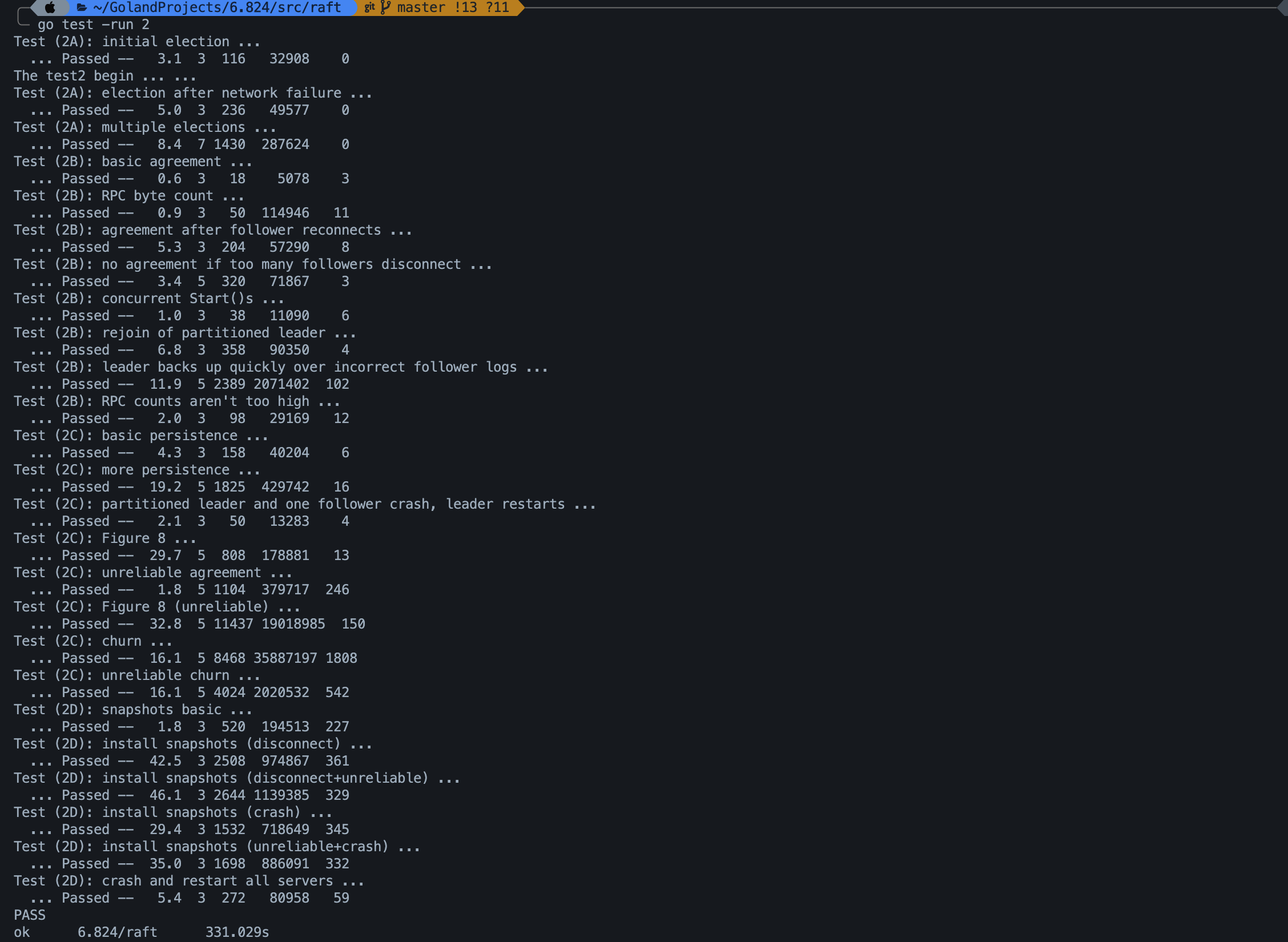
关于测试样例,再6.824整个实验中给我的感觉就是,我的code太依赖于test,这是我的一个不足之处,所以我希望在以后的coding中能够用于强大的独立测试的能力,能够编写高质量的测试程序.所以在这里我希望能够阅读测试程序,从中提炼一些比较有意思的情景.
上面是我的测试结果,其实我的测试用时要比guide里的快几十秒,感觉还不错,或许与我其中的某些时间间隔设置得比较小有关,但也导致了我耗费RPC数量较多.
1) 2A
2A中其中的测试用例都是有关于选举的.其中TestReElection2A体现了:非宕机节点只要超过总数的一半,就可以立刻选举出合法的leader,更详细地说,在这个测试用例中有一个情景就是3个节点中断开了2个,因此也就无法选出一个新的leader了,因为选举成功的条件就在于大于等于总节点数/2 + 1.所以这也就是整个系统可靠性的大前提.
而TestManyElections2A测试用例则是比较简单,采用一轮轮for循环,批量地进行宕机,如果其中宕机的有当前的leader,那么就需要马上重新选举出一个新的leader,否则就正常运行,leader不变.但无论如何宕机,也只是7个里面宕机3个,不会超过半数.
可见,“过不过半”是一个重要的问题.
2) 2B
相对于2A中的测试数据,2B的测试数据则复杂了不少.
在TestFailAgree2B中,将其中某个中途断开的follower也断开,并且验证重连后整体还可以恢复到一致性,这个得益于appendEntrys比较一致点然后追加的机制.
TestFailNoAgree2B中的,首先会断开3个,然后再追加数据,这种情况下,纵使在leader中会加入新的log条目,而仅存的一个follower也可以接收心跳,并且追加log项,但是由于成功追加的总数不足总结点数/2 + 1,所以leader的commitId也就不会更新,因此follower也不会进行更新,最终导致这一项根本就不会达到一致性.根本原因是,无法有足够数量的follower接收到此log项.当3个丢失的重新连接后,再尝试提交一个新的log,这是新的log会生效,而上一次所start的log项则会失效.
TestRejoin2B,首先先正常提交一个log,然后将当前的leader断开,然后连续start
3个log项,由于此时leader已经隔离,所以无法就这3个log达成一致,只是在leader本地增加了log项.然后再尝试提交一个log(103),由于其他节点收不到来自leader的心跳包,所以又有了一个新的leader.这算不算脑裂呢?其实不应该算,因为此时虽有两个leader,但是只有一个leader有效地工作,其中一个老leader无法和任何一个follower交流.所以说刚刚提交的一项应当达成一致(除去老leader).然后将新的leader断开,并将leader重连.这个过程就像是一个无缝地替换过程.
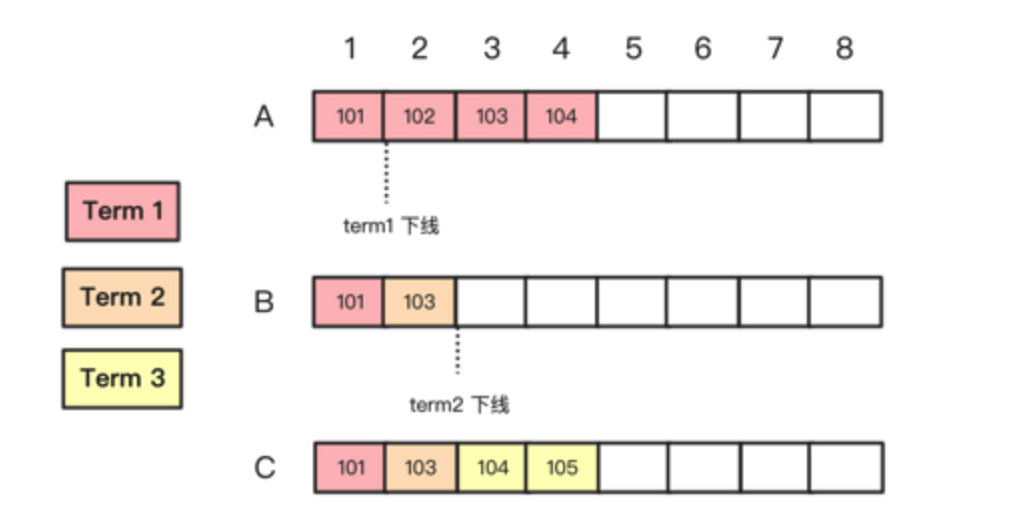
这个交替的过程略微有点复杂,重新登基的leader1在发送心跳包的时候,发现周围的节点的任期都比自己高,所以自己就要被打回follower了,这个时候,当leader下台,并且退化成follower后,这也验证了一个任期落后的leader即使重新与其他部分联通,也会因为自己落后的term导致失去leader身份,陷入整体无主的局面,这个时候就会有一个新的leader从中选举出来,然而这个新的leader究竟应该是谁呢?一定不是leader1,为什么呢?因为leader1的日志太旧,一旦该leader再断连后无法跟进新的任期,其之后的log也在任期上落后于其他的节点.所以之后的更新状况也就如图所示了.这个地方也就验证了论文中的叙述:
If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote.
对应的代码也就是:
loglast := rf.getLastLog()
if loglast.Term < args.LastLogTerm { //对于leader1来说,之后的所有log任期都是1,所以在这一点上得不到投票.
oklog = true
} else if loglast.Term == args.LastLogTerm {
oklog = loglast.Index <= args.LastLogIndex
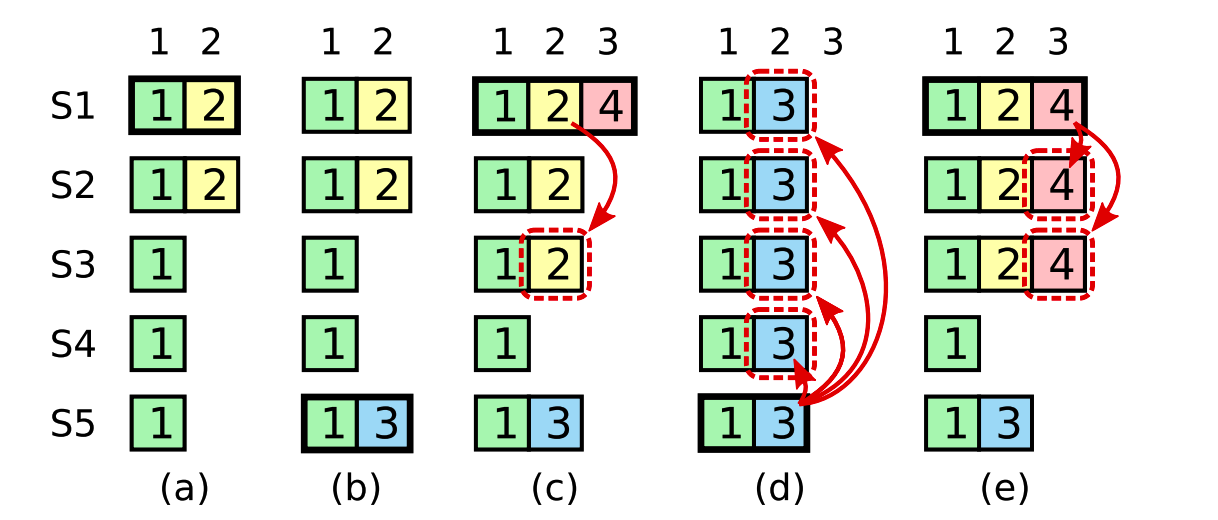
}TestBackup2B.仍然是5个节点,其过程用下面的图来概括吧.
其中将logs抽象成图中的方块,每个方块是一个三元组(日志索引,是否提交,阶段).其中m代表提交,um代表不提交.
每一阶段的事件对应如下:
- 全体提交一个log.
- 假设s1是leader1,这个时候s3,4,5断开.这个时候连续提交50个,都没有commit.
- 将阶段2的两个断开,然后将这三个重连,提交了50个并且达成一致.
- 之后将这3个其中之一断开(非
leader),然后再提交50个,但是没有commit.

5.这时,会阶段4没有连接的3个重连,这时还会发生什么呢?这个时候会发生新的选举,竞争发生在s1,s2,s5之间,其中两个断开,所以最多只能得到3票,也只有得到3票的节点才会成为新的leader,而对于s1,s2来说,由于日志老旧,一定无法得到s5的票,也就无法得到3票,因此最终只有s5成为leader.
6.第六阶段,此时所有的节点都已经连接上了,此时s5的地位仍然不会被撼动,s3,s4也会跟随s5的领导达成一致.
3) 2C
虽然在2C中,关于持久化的处理并不是太难,但是其测试用例相对而言比较复杂,所以即使过了lab2B,也未必能通过2C.尤其是其中有关于Figure 8的测试.还有2B之前都是在可靠的情况下,进行测试的,而对于2C又加入了不可靠的测试,这会导致一些RPC出现极大的延时,进而还会触发乱序的现象.
TestFigure82C.关于这个测试的分析,首先还是先来回忆一下raft论文中的图8.