mit 6.824:分布式系统 lab3 kvraft
总体来说,lab3这一部分就是为lab4打基础的,所以难度并不是太难,可讲的东西并不多.
这一部分,让我们实现raft之上的应用层,通过这次实验我对raft论文中开头所提的复制状态机理论有更深刻的认识.
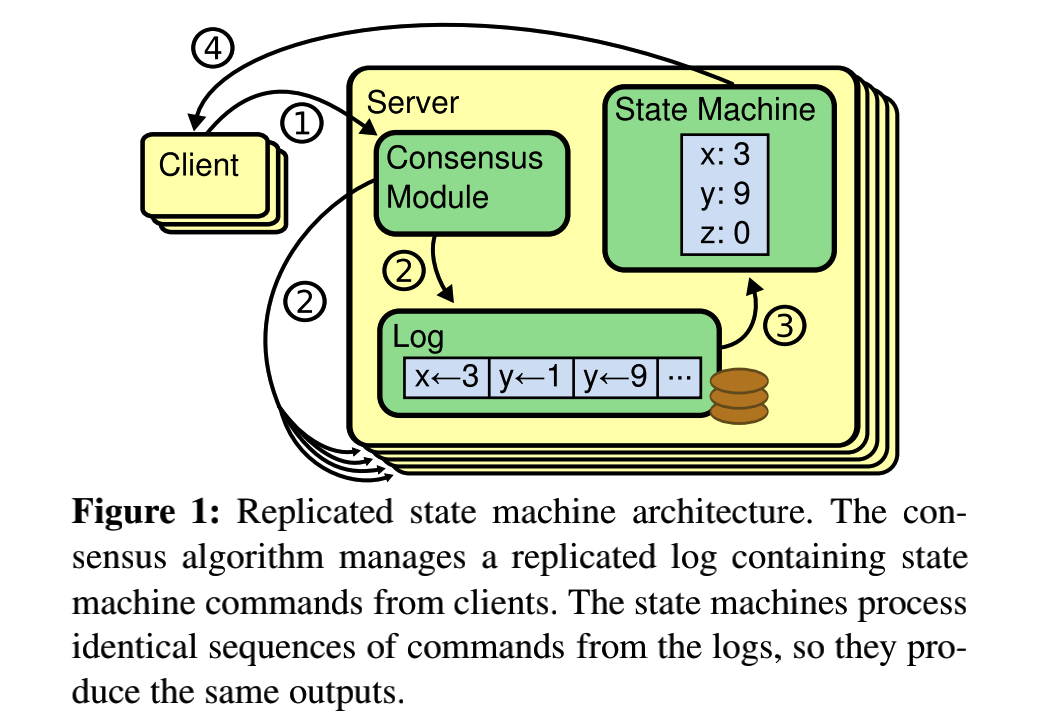
将应用层抽象成一个状态机,而这个对于这个状态机的操作抽象日志序列,大前提是,操作序列一致则状态机状态一致,因此维护状态机的一致性也就成了维护log的一致性.其中对于快照,快照是一个对于raft之上的应用层而言的东西,快照应该保存的是应用层状态机的状态.
1.实现要点
1)核心的类及其数据结构
首先是Clerk,其中currentLeader的作用在于,每次发其请求时,都优先从currLeader开始遍历,这样的话,可以有效地节省时间开销.每当成功从某个RPC返回,都会将currLeader设置该节点.
type Clerk struct {
servers []*labrpc.ClientEnd
// You will have to modify this struct.
currLeader int
commandId int
clientId int64
}关于clientId,这个在每个client初始化的时候,被设置成一个64位随机数,可以保证每个client的唯一性,而commandId维护的是该Clerk发起的请求的序列,每发起一个请求就+1,由于Clerk发起的请求是同步阻塞的,结合这个可以用来做去重判断.
type KVServer struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
dead int32 // set by Kill()
kvMap map[string]string
commitMap map[int64]int //用来记录每一个client的commited情况
applyBuffer map[int64]chan AppliedResult
maxraftstate int // snapshot if log grows this big
// Your definitions here.
}其中applyCh是用来接收来自raft的apply.其中kvMap就是用来存储数据的,也就是本次lab的核心操作对象,所有的请求和应用都最终作用于kvMap上,也是整个状态机的核心,需要进行持久化保存,加入快照.此外applyBuffer只有直接处理请求的leader才会使用,当leader接收到请求,调用raft的Start往下进行一致性处理的时候,就会等待在这个channel上,当成功apply某一个条目之后,该channel才会停止阻塞(不考虑超时).其key通过该请求的clientId的前32位和commandId的后32位组成.
2)请求的超时与重传
我们需要考虑的是一个不可靠的情景下,如何提供可靠的服务,在这里请求是从client到运行raft服务器节点的,更具体地说,是到leader的.在这里提供与TCP类似的一种机制,通过设定一个固定的时限作为timeout,这个值的设置避免了因为一些不可靠的情况导致某个请求无限制地阻塞,导致无法进行新的尝试,并且一直阻塞后面的操作.如果出现超时也就认为是这个消息请求失败了,进而需要进行重传.接下来看一下,在client发送端和server接收端的处理.
select {
case appliedresult = <- tmpch:
isout = false
case <- time.After(time.Duration(timeout) * time.Millisecond):
isout = true
}上面是server端的超时判断情况,对于每个请求都会有一个唯一的序列号,对于server(leader)处理的每个序列号都会有一个channel,这个channel用来等待raft完成一致后,将此log提交上来.
所以这种机制下,在超时或者raft提交上来之前都会一致阻塞,由于RPC处理具有阻塞性,因此client端也就会阻塞在RPC调用的地方.
如果返回超时,或者其他错误,则会使client陷入重传,直到返回OK为止.client段的实现如下,采用一个for循环,不断地尝试,一旦尝试成功则退出此循环.
for {
result := PutAppendReply{}
ok := ck.servers[ck.currLeader].Call("KVServer.PutAppend", &args, &result)
if ok && result.Err == OK {
return //这个时候说明执行结束
}
serverNumber := len(ck.servers) //说明此时currentleader无效需要尝试其他的节点
for i := 0; i < serverNumber; i += 1 {
if i == ck.currLeader {
continue
}
reply := GetReply{}
ok := ck.servers[i].Call("KVServer.PutAppend", &args, &reply)
if ok && reply.Err == OK {
ck.currLeader = i
return
}
}
}3)去重机制
当某个请求超时的时候,就将其视为错误的RPC,但实际上其中有一部分只是超时,并不是真正的出错,在这种情况下,还应该增加一定的去重机制.
我最一开始的设想是设一个map,map的key是每个apply对应的请求序列号,但是这样当请求数量上来之后,会占用过多的空间,此外这一部分是需要进行持久化处理和快照的,所以造成的快照过大,导致有一个测试(检测快照大小)会不通过,所以这种方式并不好.
较好的方式是,每个server都维护一个map,这个map的key指的是某个client序列号,其中的值是每个client对应的请求序列(已经提交成功的).每次接收到一个来自raft层的提交时,对于其中put,append等操作都会检查其请求序列号,和该map中对应的值进行比对,如果是已经重复提交过的,则就是小于等于对应值的.每成功接受一个apply,就会更新对应的值.
关于如何唯一标识一个用户的请求,其方式如下:
func getSerial(clientId int64,cmdId int) int64 {
low := clientId >> 32
high := int64(cmdId) << 32
return high + low
}也就是借助一个ClientId和CommandId实现,因为ClientId也是一个随机数,在一个服务器节点初始化时由rand函数生成.
4) 相关的RPC参数与响应
type PutAppendArgs struct {
Key string
Value string
Op string
ClientId int64
CommandId int
}
type PutAppendReply struct {
Err Err
}
type GetArgs struct {
Key string
// You'll have to add definitions here.
ClientId int64
CommandId int
}
type GetReply struct {
Err Err
Value string
}其中有两对RPC的处理,即PutAppend和Get的,其中前者的参数中包含Op要么是Put,要么是Append,ClientId和CommandId结合使用可以唯一地在kv数据库中定一个一个唯一的操作,Get部分同理.
2. 实现过程
1) Clerk
func (ck *Clerk) PutAppend(key string, value string, op string) {
ck.commandId += 1
args := PutAppendArgs{
Key: key,
Value: value,
Op: op,
SerialNumber: nrand(),
CommandId: ck.commandId,
ClientId: ck.clientId,
}
for {
result := PutAppendReply{}
//DPrintf("[%v]The ck.currenleader %v call rpc %v\n",ck.clientId,ck.currLeader,args)
ok := ck.servers[ck.currLeader].Call("KVServer.PutAppend", &args, &result)
if ok && result.Err == OK {
//DPrintf("The loop break when call %v\n", ck.currLeader)
//DPrintf("[%v] Put or Append success args %v\n",ck.clientId,args)
return //这个时候说明执行结束
}
serverNumber := len(ck.servers) //说明此时currentleader无效需要尝试其他的节点
for i := 0; i < serverNumber; i += 1 {
if i == ck.currLeader {
continue
}
reply := GetReply{}
//DPrintf("[%v]The server %v call rpc %v\n",ck.clientId,i,args)
ok := ck.servers[i].Call("KVServer.PutAppend", &args, &reply)
if ok && reply.Err == OK {
ck.currLeader = i
//DPrintf("[%v] Put or Append success args %v\n",ck.clientId,args)
return
}
}
}
}其中关于Clerk部分的实现还是比较简单的,除了关于RPC参数的设置,其中请求的部分处于一个训话中,直到返回到OK才会跳出循环,返回该请求函数,因为我们可以说,这是一个同步阻塞的函数,在一个用户的请求时,只要当前请求还没有得到ok的回应,这个用户进程就以一直处于for中,某一个时间点上,一个Clerk只在处理或者等待一个RPC请求.有一个加速的技巧在于,每成功获取一个OK的响应,就会记住其对应的leader,在进行下一次循环时,优先从leader中运行.
2) Server
RPC处理
在这里两者差不多,在这以Get为例子.
operation := Op{
Optype: GetOp,
Key: args.Key,
Value: None,
ClientId: args.ClientId,
CommandId: args.CommandId,
}
_,_,isleader := kv.rf.Start(operation) //调用raft争取达成共识
if !isleader {
reply.Err = ErrWrongLeader
return
}
tmpch := make(chan AppliedResult,1)
kv.mu.Lock()
kv.initCommitMap(args.ClientId)
serial := getSerial(args.ClientId,args.CommandId)
_,ok := kv.applyBuffer[serial]
if !ok {
kv.applyBuffer[serial] = tmpch
} else {
tmpch = kv.applyBuffer[serial]
}
kv.mu.Unlock()
isout := false
appliedresult := AppliedResult{}
select {
case appliedresult = <- tmpch:
isout = false
case <- time.After(time.Duration(timeout) * time.Millisecond):
isout = true
}
if isout {
reply.Err = ErrWrongLeader
return
}
reply.Value = appliedresult.Value
if appliedresult.Err == ErrNoKey {
reply.Err = ErrNoKey
} else {
reply.Err = OK
}在这里Log中的内容为Op结构体,这个结构体描述了来自用户的请求.除了类型,key和value,还有用于去重的ClientId和CommandId.之后再设置一个channel,这个channel用来等待来自raft层apply日志的结果.leader会维护一个map,里面有一个根据每个请求的SerialNum来进行标识的channel,当一个applyMsg从raft层接收时,就通过其中log中ClientId和CommandId的内容得出序列号从map中得到这个channel,然后传递结果,如果没有超时,那么RPC响应函数就停止阻塞运行下去.如果一个非leader收到了这个applyMsg,通常没有对应的channel就不进行传递.
其中专门有一个结构体,用来描述applyMsg被apply的情况,如下:
type AppliedResult struct {
Applied bool
Value string
Err string
}raft日志提交
func (kv *KVServer) RecApplyMsg() {
for newApplyMsg := range kv.applyCh {
DPrintf("[%v]the lastindex %v,get applymsg %v from appkych\n",newApplyMsg.SnapshotIndex,kv.me, newApplyMsg)
if newApplyMsg.CommandValid {
var operation Op = newApplyMsg.Command.(Op)
kv.DoCommandOp(operation,newApplyMsg.CommandIndex)
} else if newApplyMsg.SnapshotValid { //如果处理的是快照,需要将快照之中的内容也执行
kv.RecoverFromSnapshot(newApplyMsg.Snapshot) //解码得到日志
}
}
}这部分单独开了一个协程,设置一个用来接收来自raft的cmd或者快照,对于普通command的处理,其具体过程如下:
func (kv *KVServer) DoCommandOp(operation Op,appliedindex int) {
result := AppliedResult{}
kv.mu.Lock()
kv.initCommitMap(operation.ClientId)
applied := kv.commitMap[operation.ClientId] >= operation.CommandId
if operation.Optype == PutOp || operation.Optype == AppendOp {
if !applied {
//if !applied {
DPrintf("[%v]DoCmdop %v,appliedidx %v\n",kv.me,operation,appliedindex)
_, have := kv.kvMap[operation.Key]
if operation.Optype == PutOp || !have {
kv.kvMap[operation.Key] = operation.Value
} else {
kv.kvMap[operation.Key] += operation.Value
}//seeril能够唯一地标识某一个用户的某一个操作
kv.commitMap[operation.ClientId] = operation.CommandId
}
} else {
value,have := kv.kvMap[operation.Key]
if have {
result.Value = value
} else {
result.Value = None
result.Err = ErrNoKey
}
}
kv.UpdateApplied(appliedindex)
//DPrintf("[%v] The kvMap %v When DoCommandOp\n",kv.me,kv.kvMap)
serial := getSerial(operation.ClientId,operation.CommandId)
ch,ok := kv.applyBuffer[serial]
//kv.UpdateApplied(appliedindex)
kv.mu.Unlock()
if ok {
ch <- result //直接操作kv.applyBuffer是容易造成竞争条件的,因而也会导致一些预料不到的死锁,所以将其拷贝到ch上
close(ch)
kv.mu.Lock()
delete(kv.applyBuffer,serial)
kv.mu.Unlock()
}
}首先根据CommitMap判断当前接受的Command是否属于之前已经做过的,为什么在这里只对Put,Append进行去重的判断操作呢?因为去重本质上是为了保证像Put,Append这种会对状态机的状态进行改变的操作不会因为重复执行多次,而导致状态机的状态异常,而Get操作本身就不会对状态机的状态作出任何改变,更具体地说,如果真的有一个Get出现重复执行,比如说有n次执行Get了,其中只有一个是返回Ok的,一旦有返回Ok的,就会将其送往channel并且移除对应的项,之后陆续到来的重复Get找不到对应的项了,也就不会再传递结果到channel的阻塞处,况且一旦返回Ok,就不会再有新的RPC处理的回调了.
快照提交
关于快照这部分,实现还是比较简单的.这一部分需要靠一个单独的协程来实现.
func (kv *KVServer) CheckRaftState() {
//DPrintf("The raftstate is %v\n",raftstate)
for kv.killed() == false && kv.maxraftstate != -1 {
time.Sleep(20 * time.Millisecond)
kv.mu.Lock()
raftstatesize := kv.rf.GetRaftStateSize()
if raftstatesize >= kv.maxraftstate/10 * 9 && kv.maxraftstate != -1 { //在此调用难道不会变吗,这个参数究竟得多少才是比较合适的呢?如果是三分之一的话是不是太小了呢?
kv.DoSnapShot() //每次生成快照时都会附带有kv的状态
}
kv.mu.Unlock()
}
}在这里,使用的是周期性地检查是否需要进行打快照.
此外,关于快照需要保存的数据,其中有:
- KvMap,不需要解释,这是状态机最最根本,最最核心的操作对象.
- commitMap,去重表.如果不进行正确保存,导致某一次操作或者某一项操作重试后被appliy,就会给状态机带来错误.
- lastApplied主要用来判断接受快照时,是否需要将状态机更新为快照,如果快照中的lastApplied比较低,就拒绝该快照.因此可以防止状态机回退的问题.
func (kv *KVServer) DoSnapShot() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.kvMap)
e.Encode(kv.commitMap)
e.Encode(kv.lastApplied)
kv.rf.Snapshot(kv.lastApplied,w.Bytes())
}3.问题总结
1) 幂等操作与线性一致性
经过这次lab,在理论方面,首先对幂等操作和线性一致性有了一个初步的认识.其中幂等操作指的是重复的多次成功操作,其对于系统的影响就如同只进行一次成功操作一样.其中Get操作是对于kv的幂等操作,Put也可以算是.
就ddia书中所说,线性一致性是一种新鲜度保证,任何一个读取返回新值后,所有后续读取(在相同或其他客户端上)也必须返回新值.
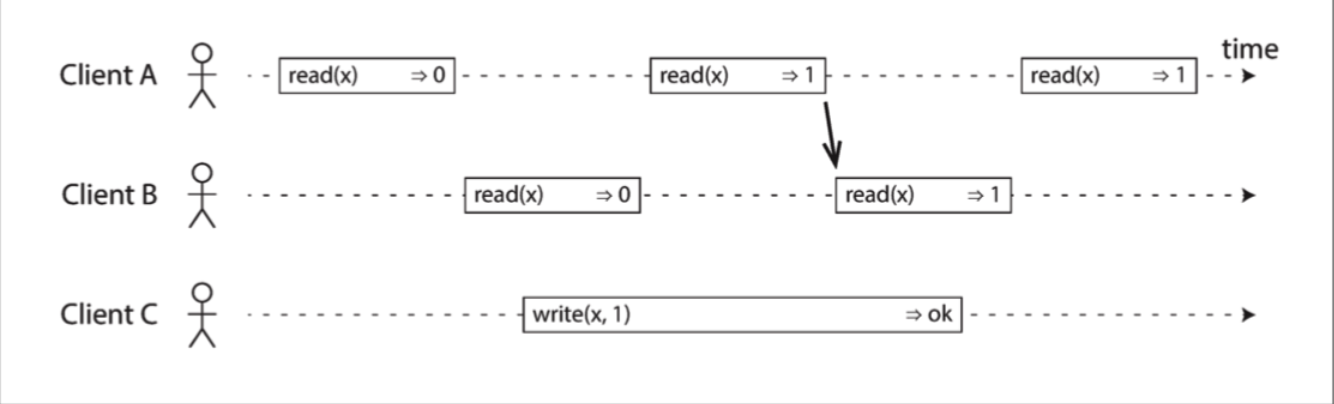
如图中所示,读写操作都是一种延迟操作,这个延迟操作中又可以分为3个阶段,第一阶段为send,也就是RPC发送到目标的过程,第二阶段则是执行具体的任务,比如读写.第三阶段则是返回给RPC的调用者.其中对于像Write这样的操作,第二阶段一定存在某个点作为分水岭,在此“分水岭”前后真正执行read操作的请求其结果也就会呈现新旧两种不同的情况.
2) Kvraft对于线性一致性问题的解决
最后复盘一下这种问题场景:client发起了某个请求,进而被leader server接收后,经raft完成了一致,并且将要将日志apply到上层的kv,并且也成功接收了,但是就在该leader server需要响应Ok的RPC回应时,RPC丢失.这个时候只能让client重试,但是我们可能会疑问,这个日志已经被apply了一次了!如果重复apply还可以吗?
毕竟raft服务于上层的kv,只要kv的状态机(kv数据库)没有被同一个请求命令重复操作就可以了,这因此也就需要在应用层作出额外的机制,这也就是上面所重点介绍的去重机制.
就如同论文中所说:
The solution is for clients to assign unique serial numbers to every command. Then, the state machine tracks the latest serial number processed for each client, along with the associated response. If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
我认为这体现了软件工程中的一种现象,尽管分层抽象可以简化问题,尤其一些服务层可以为应用层提供方便可靠的服务,但是新引入了新的层,就会引入新的问题,比如说上面所提到重复操作问题.我因此也有种疑惑,如果以后再遇到类似的问题的话,怎样才能找清楚解决问题的方向呢?究竟是应该从新引入层的角度上着手,还是像更底层的服务层着手呢?在这个raftKv中,则是新引入层的问题就在本层上进行额外的保障性机制.
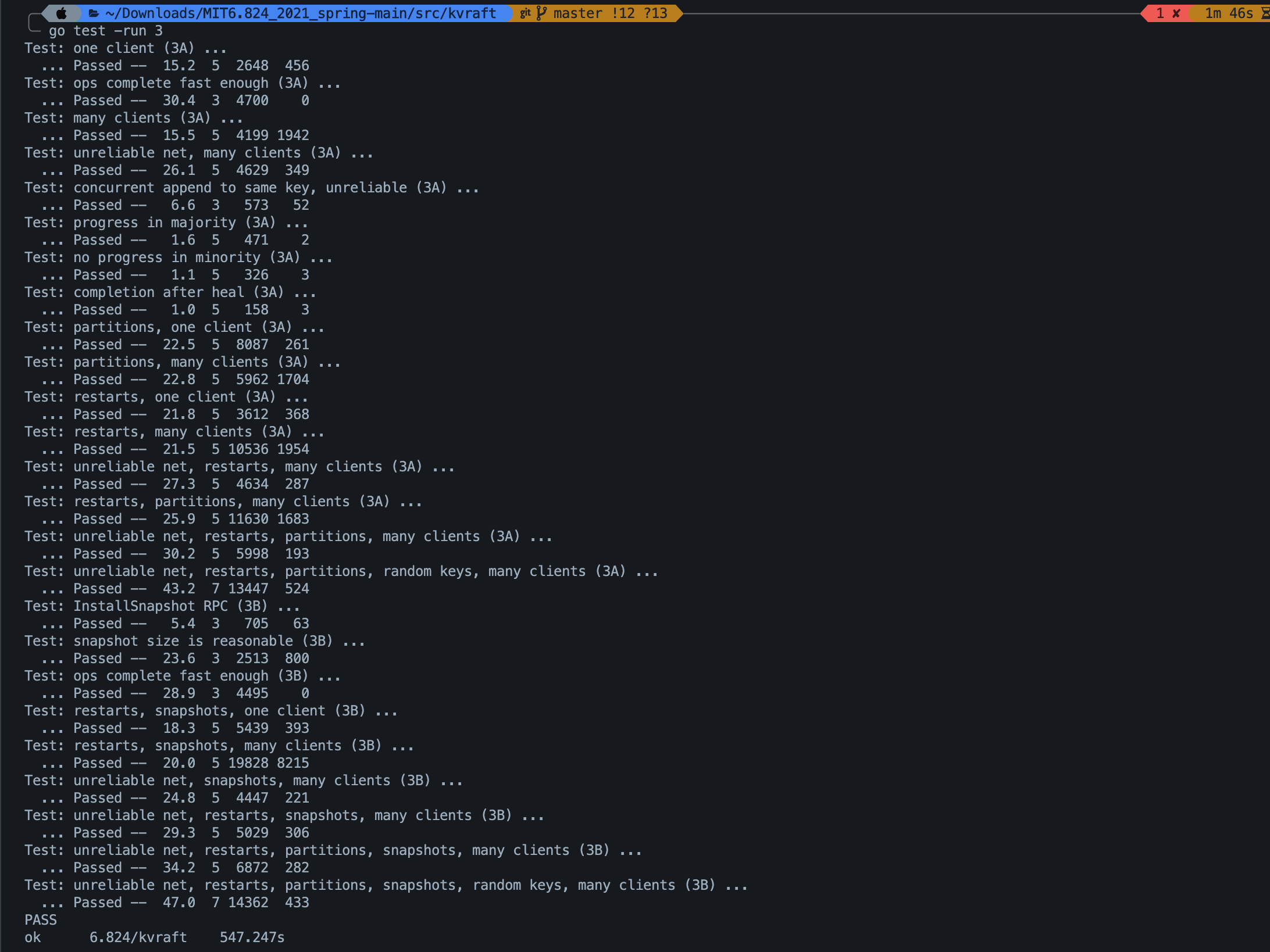
最后这是整个lab3的测试结果,我实在想不明白了,为什么我的耗时这么长.......