DDIA:Chapter 6 Patitioning
一般情况下,partitions(分区)被定义为将数据分成多份,每份属于一个特定的partition,分区也可称为shard(分片).
1.分区与复制
分区经常和复制技术搭配起来使用,分区本身是将数据集分割成一个个子集.结合复制的话,则呈现为有多个不同的group,每个group各维护一定数量的partition的副本.
图中则展现了主从模式下,复制和分区结合的模式.
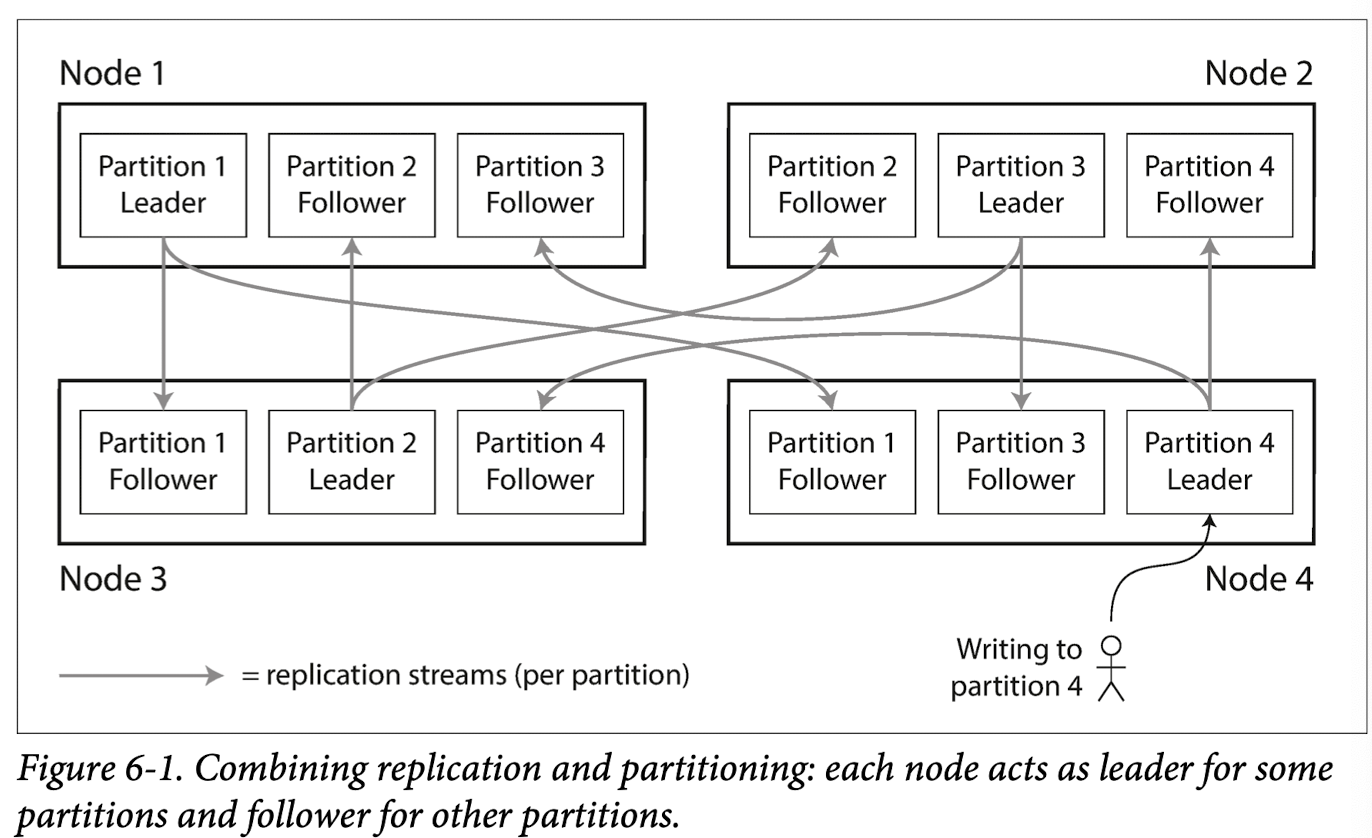
在这里的Node也可以称为是一个group.
2.KV数据的分区
分区技术的一个目的在于将查询,读写等负载均摊到多个Node中,并且提高并行程度.
如果有10个Node,如果能够平均摊开,那么其处理请求的效率将会是单Node的10倍.
如果不能公平地将查询摊开,造成某些Node的patition过多或者接受的请求太多,这种现象称为skew,其中过高载荷的Node称为hot spot.
为了避免这种现象,应该采取合适的分区方式.比如说随机分配简单高效.但是它的缺点也很明显:不能确定要访问的item位于哪一个分区,所以只能都进行尝试(可并行).
下面介绍几种kv存储中,常见的分区方式.
1) 按照key的范围划分

将key按照某种顺序排列后,将其划分为一个个段,每一段的数据被视为一个patition.只要client知道每一段的边界和每一个partition所属的Node,就可以直接发送到数据所属的Node.其中每一段的大小的选取应当为了总体的平衡所考虑.比如说,如果只是死板地将每一个partition规定为两个字母,那么必定有某些partition数据量过少或过多.这与单词数据的特点有关.
在每个partition的内部,可以将其内部的数据保持某一顺序.
其缺点在于容易导致hot spots.如果是时间戳,每个分区对应的是一定的时间范围,由于测试时,写入操作比较多,那么就造成今天所在的分区比较集中.而此时其他分区处于空闲.
2) 根据key的hash值来进行分区
hash值使用起来简单,很容易获得均匀的划分结果,因此再结合key-range的方法,能够较好地避免hot spots和skew现象.

但是这种方法的短板也很明显,就是没有高效执行范围查询的能力.因为在hash值上顺序的连续并不能保持key值顺序的连续.
3) 倾斜负载与热点消除
对于一些极其特殊的情况,即使采用hash
key也难以消除hot spots,比如说导致某个数据或者key大量写入的情况.
这种情况一般只能交给应用程序来处理.一种方法是监控某一个热度极高的key,当确定时,将其进行分割,将其key附加上一位或者多位随机数,每个表示这份key的一部分.将这些划分出来的部分分散到多个partition,但是也带了很大的不便,每次读都需要做额外的操作,需要读每一个被分割后的部分,收集好后进行合并,此外还需要增加额外的数据结构进行追踪key的状态.
4) 分区与次级索引
前面的讨论都只是基于一个主键的情景.下面介绍一下有多个key的场景.
其中有两种主要的方法,即基于文档分区和基于关键词分区.
3. 分区再平衡
分布式系统是动态的,其中容易有各种变化:机器数量增加,数据集大小增加,机器故障等.
这个过程涉及到数据的迁移,也就是再平衡.其中需要满足的要求有:
- 重新更新配置后,负载应该仍然保持均匀.
- 系统在更新期间应该对外保持服务.
- 尽可能地少移动数据,并快速平衡,减少网络和IO负载.
下面介绍一下常见的再平衡策略.
1) 反面教材: hash mod N.
取模的缺点在于,当N的数量发生变化,会有很多节点从一个节点迁移到另一个节点,其重新平衡的开销昂贵.
不符合“尽可能少移动数据”的原则.
2) 固定数量的分区
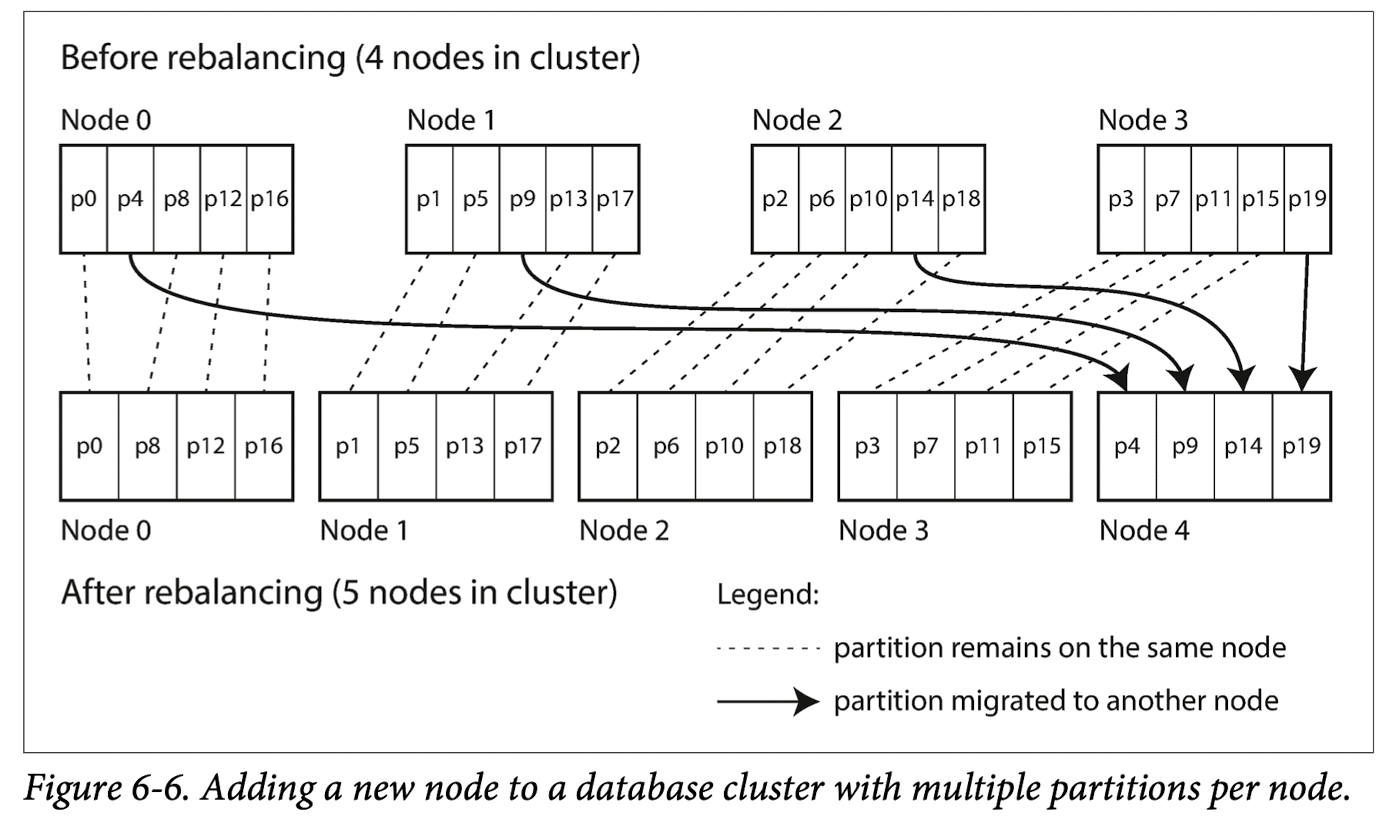
这种情况指的是,总体分区数量不变的情况,只有partition在不同Node之间的传递.
比如说,当有一个新的Node加入的时候,它将从其他之前存在的节点中窃取某些partition,直到达到再平衡.如果是一个Node撤离,这个过程则是相反的.
由于这种模式下的数据传递不是一蹴而就的,所以再旧的数据尚未迁移到新的数据上时,旧的数据还是可以对外提供读写服务的.
但是这种模式的局限性在于:分片数量固定.一把比较适合于不变的数据库中,此外,固定的分区数也限制了节点数量,节点的数量不能比分区的数量多,因此其可拓展性具有一定的问题.
此外数据集的总大小难以确定,选择合理的分区数会比较困难.
再mit 6.824 lab4中就采用了这种模式.
3) 动态分区
这种方法会用来应对分区大小增长的情况,如果分区的大小增长到一定的情况,就要分裂成两个分区,如果减小到一定的程度,就合并到其他分区中.
而为了平衡节点之间的负载,因为分区的分裂与合并有可能导致节点中不平衡的问题,这就需要当出现分区分裂时,将其中一部分转移到另一部分的方式.
这种方式的优点在于能够较好地适应数据的增长,数据量小,分区数则小,数据量大,分区数量则大.
但是当数据库从空的开始,最初只有一个分区的情况,会不会因为只处在一个节点中而出现hot spot的情况?这种情况怎么处理呢?HBase,MongoDB采用了一种预分割的机制(这种机制没看懂).
4) 按节点比例分区
在上面的两种方法中,动态分区对于每个分区的大小维护在一个比较稳定的范围内,但是分区的数量与数据集大小成正比.
而固定分区的方法,每个分区的大小与数据集的大小成正比(毕竟保持总分区数量不变).
按节点比例分区是一种分区数与节点数成正比的方法.当增加节点数时,将分区减小,分区数量也随之增多.
4.请求路由
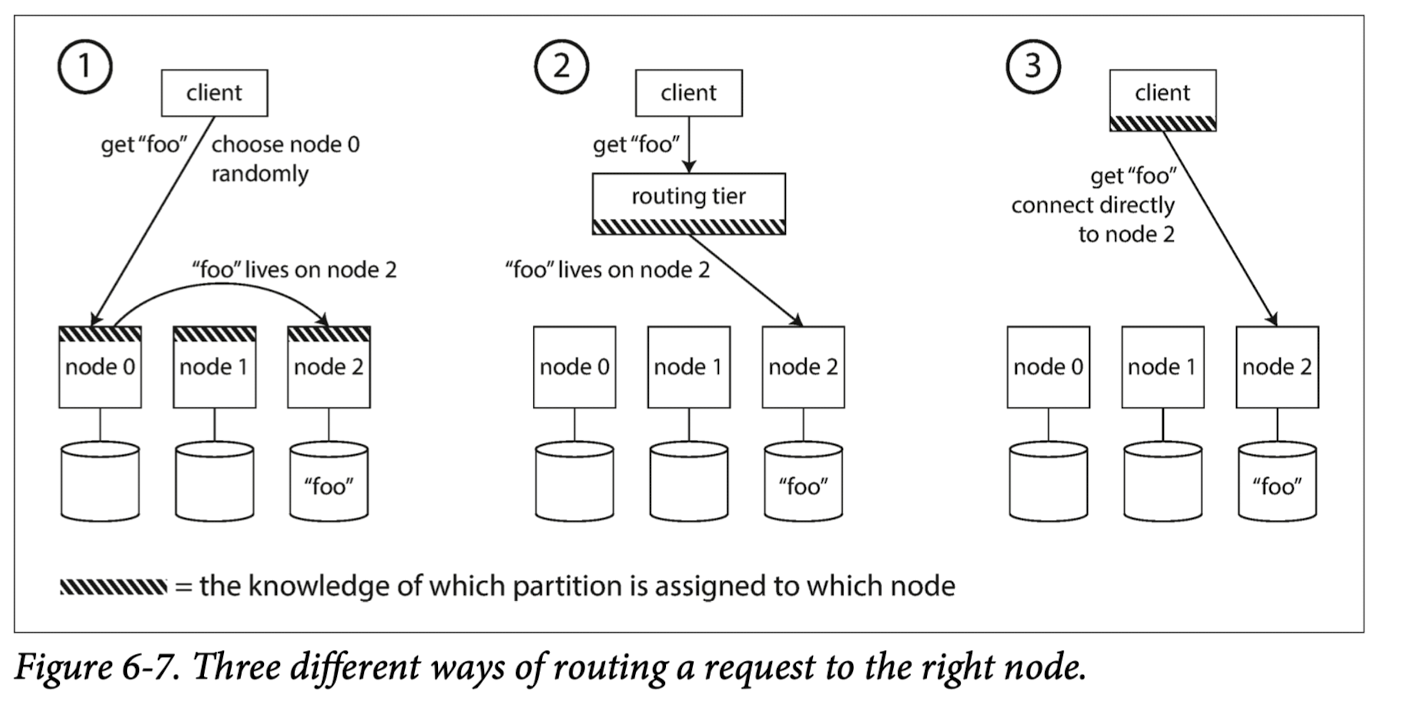
这里还有一个问题,用户在发其请求时,如何知道该请求发往哪一个节点?
这个问题有以下的解决方案:
- 允许客户联系任何节点.直接尝试逐个访问,如果有则成功响应并处理请求,否则该节点将请求传递给恰当的节点.简而言之,就是节点做路由.
- 增加一个路由层,由路由层来决定处理的节点并做转发.
- 将分区和节点分配的情况暴露给client.
5.小结
1) 分区的需要
当数据量达到一定程度时,在单机上维持整个数据集(副本)将会不可行,所以考虑将大的数据集拆分成一个个分区,每一个机器只维护其中一部分分区(副本).
这种机制的理想目标在于,将分区分配给不同的Node时,能够尽可能地均匀负载,避免出现热点.
2)分区的方法
key-range 分区能够利用数据的排序来进行高效的范围查询,但是如果应用程序倾向于集中于某一部分的访问,那么热点也就在所难免.
其中,动态平衡分区可以在某个分区太大时,分割成不同的分区,动态地达成平衡.
此外还有散列分区,由于破坏了排序不利于范围查找,但是其对于负载的平衡性处理较好.