mit 6.830 数据库系统: lab 1
数据库系统的这个实验,我也是早就有计划要做了,但是之前一直在纠结是做CMU 15445还是这个.虽然相对于java,我还是对C++比较熟悉(但还是菜得很),但是我最后还是打算做这个,因为这个实验我感觉难度曲线更加平滑,要做得部分也更加完备,而且测试相对比较方便.况且,我的目的主要还是搞清楚数据库系统底层的设计与实现,语言并不是最重要的,我相信只要通过这个lab把原理和思想搞透彻,我在后来用C++实现数据库就会简单得多.
其实数据库系统是个很硬核的方向,但是在我们学校上的数据库课程比较水.
花了1.5天的时间做完了lab1,比想象中的要顺利,但是据说后面会非常困难.
1.整体架构
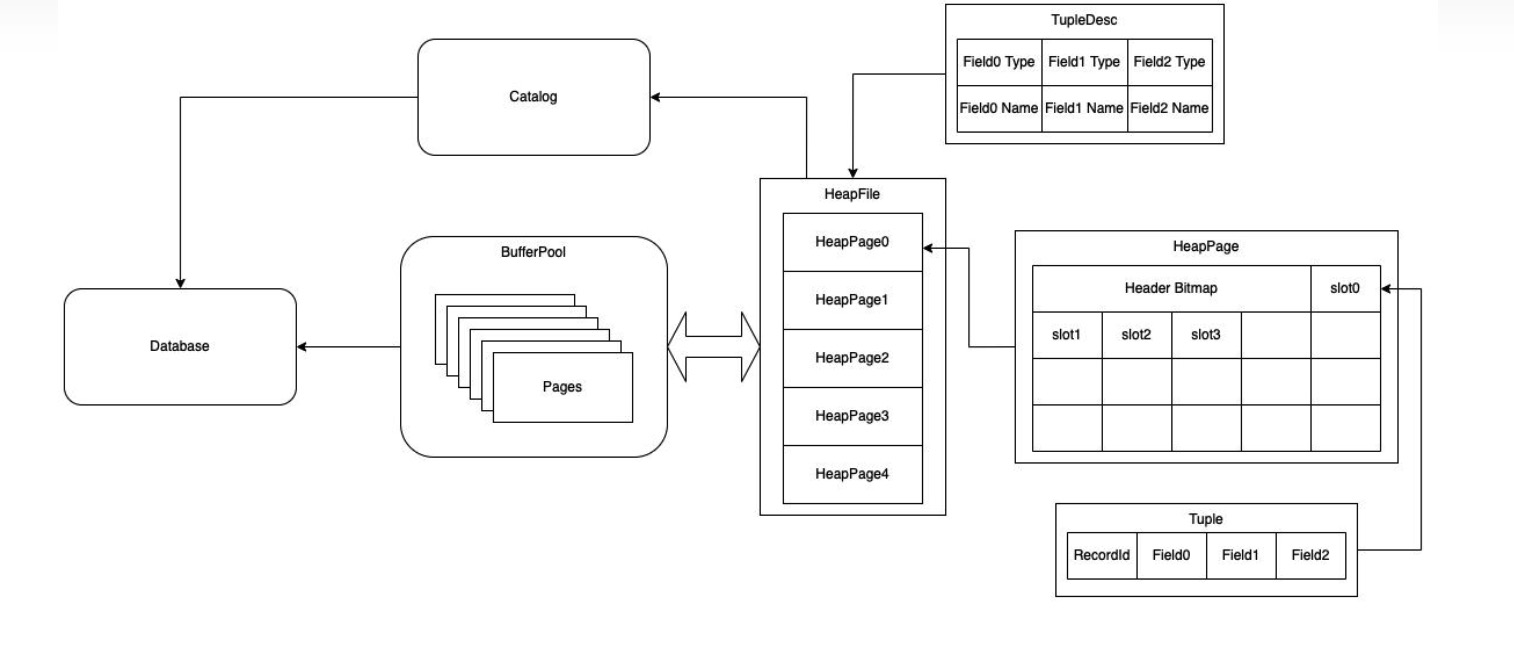
从宏观说起,整个db是一个采用单例模式的Database对象.在lab1中这个类里面包含了两个全局性的对象,分别是Catalog和BufferPool(LogFile暂且不计).所以说,Catalog和BufferPool也是采用了单例模式.至于Database的构造函数是比较简单的,主要是对于Catalog和BufferPool进行初始化.关于这两个对象的访问方式如下.
private static final AtomicReference<Database> _instance = new AtomicReference<>(new Database()); //在静态区初始化全局对象.
public static BufferPool getBufferPool() {
return _instance.get()._bufferpool;
}
public static Catalog getCatalog() {
return _instance.get()._catalog;
}1) Catalog
对于Catalog是一个跟踪全局table及其模式的数据结构,也提供了外界操作访问table的主要接口,比如说add,get等.每一个表都会有一个全局性唯一标识符号tableId.这个也是外界或者其他地方访问table的方式,也就是通过tableId带入到Catalog所提供的接口中.一个表的schema靠一个对应的TupleDesc对象来修饰,此外关于一个table的信息还有名字,其所归属的文件,主键等等.其中基础也是比较复杂的就是一个表对应的文件对象DbFile.
DbFile在这个lab中是一个interface,lab1中由HeapFile具体实现.每一个HeapFile对象又会有一个TupleDesc对象去修饰,所以在这里说,一个HeapFile对象和一个table是一一对应的.一个HeapFile有会分页,分页操作的主要目的在于便于提供给BufferPool进行操作,每个HeapFile的Page的内容则主要是表中的一个个Tuple(还有Bitmap),因此HeapFile又通过HeapPage对外提供了操作和访问Tuple的接口,在lab1中读取一个个Tuple的接口是由一个迭代器实现的,在迭代器的实现中,还要考虑分页的影响,考虑再分页的情况下,如何给外界提供一个“连续访问”的假象.
在细说HeapPage,其实在HeapPage的迭代器只是间接地做了对Tuple的访问,它利用了HeapPage对于Tuple的迭代器,HeapPage则是对Tuple对直接的.HeapFile对于HeapPage来说并算是has-a的关系,而是提供了一个使用readPage接口(以PageId从HeapFile检索)new出一个HeapPage对象.之所以不采用has-a将HeapPage作为数据成员的原因在于,那样将会把所有页,也就是整个文件内容都加载到了内存了,但实际上很多时候不会全部用到,因而浪费了大量内存空间,因此这是一种按需读取的思想.
再往底层看,在看Tuple的实现,每一个Tuple又是一个个Field的集合,因而说对于fields的访问则需要借助对应的Tuple对象,其需要靠TupleDesc进行修饰也不必说了.而关于TupleDesc这个类,每一个HeapFile,HeapPage,Tuple都会有一个对应的TupleDesc去修饰.
所以至此,对于Catalog这条线,可以简单地总结为:
Catalog持有多个Table,每个Table底层对应一个HeapFile,每一个Heapfile虽然对应多个HeapPage但不是has的关系,而是按需返回HeapPage.每一个生成的HeapPage则将其含有的Tuple对象作为数据成员,因此提供了对于Tuple直接的迭代器.
2) BufferPool
下面梳理BufferPool这条线.还是先说起HeapFile所提供的迭代器,其内部虽然借助了HeapPage对于Tuple的迭代器,但是HeapFileIterator的迭代器并不是直接通过readPage返回的,而是先借助BufferPool的getPage,如果已经有缓存,则直接返回,否则再借助HeapFile的readPage进行返回.其调用关系如下:
HeapFileIterator->BufferPool.getPage->HeapFile.readPage再看HeapPage,它与BufferPool有紧密的联系,其大小需要靠BufferPool的页大小决定,进而决定了一个HeapPage的bitmap大小和Tuple数量.
3) 各种Id的作用
上面的很多类中都出现了Id这个数据结构,比如PageId,RecordId等,我为这些Id的作用感到比较疑惑.其中牵扯到Id的类有:HeapFile,HeapPage,Tuple,Table.
其中Table的id被Catalog用于访问,根据tableId从全局的表中检索出特定的某个表,Catalog中一个get某个Table的接口,都是以TableId作为参数进行传递的.
HeapFile也是根据heapId_来进行检索,是区分每个不同文件的索引,通常使用绝对路径的hash值来确定其Id.
HeapPage的Id由两部分组成,分别是tableId和pgNo,由于table和文件一一对应的关系,所以根据tableId可以唯一地标识这个page所在的文件和表(根据Catalog.getDatabaseFile即可得出对应的文件),而pgNo进一步地确定了这个page在文件中所处的页号.所以一个HeapPageId既可以全剧唯一地标识某个页,又可以精确地标识出其位置.其中根据PageId得出的hashCode可以作为BufferPool中一个map的key,这样能够使访问BufferPool中的页更加迅速.在HeapFile的迭代器中,对于页的访问则是通过该Id完成的.
public HeapPageId(int tableId, int pgNo) {
tableId_ = tableId;
pgNo_ = pgNo;
}Tuple的Id则是一个RecordId对象,这个对象相当于在PageId外面又加了一层tupleNo,因此可以全局性地标识这个Tuple.
2.实验过程
Exercise 1
这一部分非常简单,很容易就看出来,其实TupleDesc用来修饰Tuple,所以应该是它的一个数据成员,首先把TupleDesc写好是比较自然的实现思路.其中的数据成员,我加入了:
private ArrayList<TDItem> ItermList_; //类似于C++中的动态数组
private int fieldNum_;//表示数量由于TupleDesc不过时TDItem的集合,因此也就使用ArrayList存放.其构造函数的实现,只要将两个数组中的内容生成对应的TDItem加入到ArrayList中就可以了.至于剩余的部分,感觉没有什么好说的,大部分都是非常简单的get操作.
public TupleDesc(Type[] typeAr, String[] fieldAr) { //构造函数
// some code goes here
int len = fieldAr.length;
ItermList_ = new ArrayList<TDItem>(len);
for (int i = 0; i < len; i ++) {
TDItem newItem = new TDItem(typeAr[i],fieldAr[i]);
ItermList_.add(newItem);//加入新的Item
}
fieldNum_ = len;
//PrintItemForTest();
}然后关于Tuple的实现部分,其数据成员如下.
private RecordId recordId_;
private TupleDesc desc_;
private ArrayList<Field> fields_;相比之下,增加了fields,因为每一个元组必须要有实际的值的,其实field则是TupleDesc中每一部分实际的值.此外一个元组又被称为一个Record,RecordId用来全局性地对这个元组进行标识.其构造函数如下:
public Tuple(TupleDesc td) {
// some code goes here
int len = td.numFields();
desc_ = new TupleDesc(td); //借助拷贝构造函数实现深拷贝
fields_ = new ArrayList<Field>(len);
for (int i = 0; i < len ; i ++) {
fields_.add(null); //初始化动态数组
}
}当执行完构造函数,其实这个元组还并不完整,其中的值是空的.RecordId也还没有设置好.而RecordId则是通过外界来进行Set的.对于Tuple中的其他实现,也是简单的Set或者Get操作,比较简单不再细说.
Exercise 2
这一部分实现Catalog,牢记这个类的使命在于全局性的维护所有的Table.根据其提供的接口addTable的参数,就可以得知Table相关的数据成员.而关于其TupleDesc则通过DbFile得出.得知了有关于Table需要的相关数据后,可以作出一下的实现:
public static class TableDesc implements Serializable {
//private TupleDesc desc_;
private String name_;
private String pkeyFieldId_;
private DbFile dbFile_;
public TableDesc(DbFile dbfile,String name,String pkeyFieldId) {
name_ = name;
pkeyFieldId_ = pkeyFieldId;
dbFile_ = dbfile;
}
public String getName() {
return name_;
}
public String getpkFieldId() { //获取主键
return pkeyFieldId_;
}
public DbFile getDbFile() {
return dbFile_;
}
}
private ArrayList<Integer> tables_; //tableId的集合
private ArrayList<TableDesc> tableDescs_; //每个table的描述符
private ArrayList<TupleDesc> tupleDescs_; //每个table对应的tuple的描述符
private int tableNum_; //总数其实在我的实现中还是有些冗余的,可以将tuple也合并到tableDesc_中.在下面的实现中,构造函数只要将这些都设置为空的就可以了.其中内容的添加并不是一开始就初始化进去的,而是在后来调用addTable加入的.关于addTable的实现如下:
public void addTable(DbFile file, String name, String pkeyField) {
// some code goes here
TableDesc tabledesc = new TableDesc(file,name,pkeyField);//new一个新的table
TupleDesc tupledesc = file.getTupleDesc();
Integer tableid = file.getId();
tables_.add(tableid);
tableDescs_.add(tabledesc);
tupleDescs_.add(tupledesc);
tableNum_ ++;
}除此之外,我认为还有一个地方需要注意.、
param name the name of the table -- may be an empty string. May not be null. If a name conflict exists, use the last table to be added as the table for a given name.
所以在getTableId这个根据name进行检索的接口中,采用倒序遍历的方式,等到符合要求时,返回结果.
public int getTableId(String name) throws NoSuchElementException {
for (int i = tableNum_ - 1; i >= 0; i --) {
String tmpName = tableDescs_.get(i).name_;
if ((tmpName == null && name == null) || tmpName.equals(name)) {
return tables_.get(i);
}
}
throw new NoSuchElementException(String.format("Not %s in tables from getTableId",name));
}而其中关于Table的迭代器是Integer类型的,代表的tableId,因此如果借助Catalog遍历全局的表时,可以采用这个迭代器,并且再结合tableId为参数的一些get函数返回对应的表的有关的信息.
Exercise 3
有关于BufferPool的实现还是比较简单的,其中需要增添的如数据成员及其构造函数如下:
private HashMap<Integer,Page> pages_;
private int maxPageNum_;
public BufferPool(int numPages) {
pages_ = new HashMap<Integer,Page>();
maxPageNum_ = numPages;
}此外lab1中还需要实现getPage,其实现如下.
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
// some code goes here
//return null;
//首先寻找有没有符合要求的
int hashcode = pid.hashCode();
if (pages_.containsKey(hashcode)) {
return pages_.get(hashcode);
}
//到了这里说明没有
int size = pages_.size();
if (size >= maxPageNum_) {
throw new DbException(String.format("The pages.size is %d,add new page error from getPage",size));
}
DbFile dbfile = Database.getCatalog().getDatabaseFile(pid.getTableId());
Page page = dbfile.readPage(pid);
pages_.put(hashcode,page);
return page;
}首先从pid得出对应的hashcode,然后检查BufferPool的Map中有没有对应的key,如果有,就直接将map中的值返回.否则,会不得从DbFile读取Page,然后设置PageMap的对应value.
Exercise 4
关于HeapPageId和RecordId的实现,不再多说,其作用在上面也已经说了.
在HeapPage中,已经给我们定义好了数据成员:
final HeapPageId pid; //用于表示这个页
final TupleDesc td; // 这个页对应的Tuple描述符
final byte[] header; //Bitmap用于判断这个页中每一个Slot的占用情况
final Tuple[] tuples; //实际存储的Tuple内容
final int numSlots; //Slot的数量
byte[] oldData;
private final Byte oldDataLock= (byte) 0;关于getNumTuples的实现,是以bit为单位进行计算,首先计算出一个页总共的bit,然后再除以每一个Tuple所占的bit,此外由于bitmap每一个Tuple又有一个对应的bit,所以每一个Tuple在整个Page中所占的Bit就是(td.getSize() * 8 + 1).最后的结果也就是向下整除的结果了.
private int getNumTuples() {
return (BufferPool.getPageSize()*8) / (td.getSize() * 8 + 1);
}getHeaderSize的实现,要求返回的是字节数.
private int getHeaderSize() {
return (int) Math.ceil(numSlots * 1.0 / 8.0);
} 下面是getNumEmptySlots``isSlotUsed的实现.
public int getNumEmptySlots() { //根据位图来判断呢?还是根据tuple呢?
// some code goes here
int cnt = 0;
for (int i = 0;i < numSlots ; i ++) {
if (!isSlotUsed(i)) {
cnt ++;
}
}
return cnt;
}
public boolean isSlotUsed(int i) { //需要读取bitmap
// some code goes here
int index = i / 8;
int offset = i % 8;
int bit = header[index] >> offset & 0x01;
return bit == 1;
}最后迭代器的实现也比较简单的,将Tuple数组中的元素都塞到一个ArrayList中,并且返回其迭代器即可.
public Iterator<Tuple> iterator() { //迭代器的实现怎么做??
// some code goes here
ArrayList<Tuple> tuplelist = new ArrayList<>();
for (int i = 0 ; i < numSlots; i ++) {
if (isSlotUsed(i)) {
tuplelist.add(tuples[i]);
}
}
return tuplelist.iterator();
}Exercise 5
其中数据成员和构造函数如下:
private File file_;
private TupleDesc tupleDesc_;
private int heapId_;
public HeapFile(File f, TupleDesc td) {
// some code goes here
file_ = f;
heapId_ = f.getAbsoluteFile().hashCode(); //用来进行唯一的标识
tupleDesc_ = td;
}然后下面是readPage的实现,这个函数主要用于当BufferPool没有将某一页缓存时调用.
public Page readPage(PageId pid) { //从file里面提取出来相应的page
// some code goes here
int tableId = pid.getTableId(),pgNo = pid.getPageNumber(),pgsize = BufferPool.getPageSize();
int fileLen = (int) file_.length();
if ((pgNo + 1) * pgsize > fileLen) {
return null;
}
try {
RandomAccessFile raf = new RandomAccessFile(file_,"r");
int offset = BufferPool.getPageSize() * pgNo;
raf.seek(offset);
byte[] data = new byte[pgsize];
raf.read(data,0,pgsize);
HeapPageId hpId = new HeapPageId(tableId,pgNo);
HeapPage heapPage = new HeapPage(hpId,data);
raf.close();
return heapPage;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}首先判断其中的pgno是否在合适的范围内,如果越界则返回null.否则利用RandomAccessFile读取出对应的页,首先根据页号,计算出其所属的offset,并且利用seek函数将文件中的游标移动到该偏移处,然后调用raf.read进行读取,将内容读取到byte[]中后,在根据pid生成HeapPageId,进而new出来一个新的HeapPage,并返回.这个函数体现了页是按需加载到内存中的.
还有关于页数的计算也是需要注意的.对于多余出来的部分而不足getPageSize的部分,是不算一页的无效部分.
public int numPages() { //根据这个文件的大小计算出来即可
// some code goes here
int num = (int) Math.floor(file_.length() * 1.0 / BufferPool.getPageSize());
return num;
}对于迭代器的实现,是这个类的重点,首先我们需要明确一下迭代器的核心功能是什么.迭代器是一种对外提供的对某个数据结构进行遍历的接口,我们可以顺着迭代器按照某种顺序将该数据结构(容器)中的元素逐个遍历出来,对外看来这似乎是连续的,但是迭代器所做的抽象正是对外呈现一种可以连续访问的假象,但其实内部未必是连续的.
这里的迭代器则是要求能够遍历出一个HeapFile中的所有Tuple.每个HeapPage中确实提供了可以对外遍历其中的Tuple的迭代器,因此HeapFile迭代器正是基于每一个page的迭代器在进行一层抽象.其实现如下:
public class HeapFileIterator implements DbFileIterator{
private HeapFile hpFile_;
private TransactionId tid_;
private Iterator<Tuple> tupleIterator_;
private int currPageNo_;
public HeapFileIterator(HeapFile file,TransactionId tid) {
hpFile_ = file;
tid_ = tid;
tupleIterator_ = null;
currPageNo_ = 0;
}
private Iterator<Tuple> getTupleIterator(int pgno) throws TransactionAbortedException,DbException {
HeapPageId pgId = new HeapPageId(hpFile_.getId(),pgno);
Page page = Database.getBufferPool().getPage(tid_,pgId, Permissions.READ_ONLY); //这个地方应该和bufferpool直接交互
HeapPage heapPage = (HeapPage) page;
if (page == null) {
System.out.println("The heapPage is null");
}
return heapPage.iterator();
}
@Override
public void open() throws DbException, TransactionAbortedException {
currPageNo_ = 0;
tupleIterator_ = getTupleIterator(currPageNo_);
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException{
//return false;
if(tupleIterator_ == null) {
return false;
}
if (tupleIterator_.hasNext()) {
return true;
}
if (currPageNo_ + 1 < hpFile_.numPages()) {
return getTupleIterator(currPageNo_ + 1).hasNext();
}
return false;
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
//return null;
if(tupleIterator_ == null) {
throw new NoSuchElementException("The tupleIterator is null from HeapFileIterator");
}
if (tupleIterator_.hasNext()) {
return tupleIterator_.next();
}
//考虑进入下一页
if(currPageNo_ + 1 < hpFile_.numPages()) {
currPageNo_ ++;
tupleIterator_ = getTupleIterator(currPageNo_);
return tupleIterator_.next();
}
//已经没有下一页了
throw new NoSuchElementException("Not have next Page from tupleIterator next");
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
close();
open();
}
@Override
public void close() {
currPageNo_ = 0;
tupleIterator_ = null;
}
}Exercise 6
练习6要求实现SeqScan,也是一个迭代器,对比之前的HeapFileIterator,这个迭代器对应的目标是Table,正如前面所说,Table是HeapFile的上一层抽象,因此SeqScan也是基于HeapFileIterator实现的,也是对外给用户使用的最直接的接口.
其中的数据成员有:
private DbFile dbFile_;
private DbFileIterator Iterator_;
private TransactionId tid_;
private int tableId_;
private String tableAlias_;
private TupleDesc tupleDesc_;构造函数的实现如下:
public SeqScan(TransactionId tid, int tableid, String tableAlias) {
// some code goes here
tid_ = tid;
tableId_ = tableid;
tableAlias_ = tableAlias;
dbFile_ = Database.getCatalog().getDatabaseFile(tableId_);
Iterator_ = dbFile_.iterator(tid_);
TupleDesc tmpdesc = Database.getCatalog().getTupleDesc(tableId_);
Iterator<TupleDesc.TDItem> fieldIterator = tmpdesc.iterator();
Type[] types = new Type[tmpdesc.numFields()];
String[] names = new String[tmpdesc.numFields()];
int index = 0;
while(fieldIterator.hasNext()) {
TupleDesc.TDItem item = fieldIterator.next();
types[index] = item.fieldType;
names[index] = String.format("%s.%s",tableAlias_,item.fieldName);
index ++;
}
tupleDesc_ = new TupleDesc(types,names);
}需要注意的是,在这里需要根据tableAlias对TupleDesc进行设置,将tableAlias最为Field的前缀.剩余的部分,关于一些get,set操作的实现都是比较简单的,此外对于一些迭代器相关的操作也都是简单地对HeapFileIterator操作的一层封装,就不再多说了.
3.小结
lab1不算太难,只要梳理清楚了各个类一层层的抽象关系即可.此外这里文件分页和BufferPool的配合我认为是非常巧妙的,文件分页既可以实现按需读取,减少全部加在所带来的内存浪费,又可以适应内存池装载的要求.此外,我对于迭代器这种设计模式的认识也更加深刻,我认为迭代器可以对外提供一种连续遍历访问假象,屏蔽了内部的细节,就比如说c++ STL中的deque,其内存分配其实是一段一段的,并不能说是连续的,但是使用它的迭代器就仿佛在一段连续的空间中顺序访问.此外还熟悉了一下好久没有使用过的java,java有一点让我不舒服,就是关于对象最为数据成员的情况.https://juejin.cn/post/7041890272573128740.