modern C++学习笔记
0.Modern C++ 浅谈
1.类型推导与auto
在C++11之后引进了auto和decltype.
auto的作用不再多说,在此说一下decltype,auto只能对变量进行类型推导,而不能对一个表达式进行类型推导.
其用法如下:
decltype(expression) var;其中推导的判断逻辑如下:
如果括号内部仅仅就是一个变量,那么结果就和这个变量一样.
如果内部是一个函数调用,那么就与函数返回值相同,但是该函数不会调用.
如果是一个被括号括起来的变量,那么结果就是引用.
上面的都不满足就是和表达式的结果相同.
此外在《Effective Modern C++》中,建议开发者多使用auto的,auto是需要必须有右值进行初始化的,因此即使是一个简单的变量,也可以起到预防未初始化的效果.对于迭代器就更比说了,迭代器的代码一般都挺长,写起来麻烦.并且一些容器的返回值,是比较复杂生疏的,如果不使用auto就意味着我们必须要记住它的类型及其写法,这是很烦人的.比如说这样:
std::unordered_map<std::string,int> m;
for(const std::pair<std::string,int>& p :m) {
}
//写成这样:
for (auto &kv: m) { //带有引用表示可写
}auto的出现,让我们在很多时候都没必要熟悉函数的返回值(很多时候!=所有时候)
2.右值引用与移动
先不看了.
3.智能指针
首先我们细数raw pointer的弊端:
- 不能通过指针区分,其用作一个数组还是对象,这会引来delete还是delete[]的烦恼.
- 当我们使用时,我们难以直观地观察出是否已经销毁.
- 程序复杂起来之后,一个函数体可能有多个返回处,这容易导致我们在某个运行分支中忘记销毁进而导致内存泄露.
- 悬垂指针问题.
关于智能指针主要是unique_ptr和shared_ptr.
1) 智能指针与所有权
unique_ptr是独占所有权的.它所占的大小与raw
pointer相当,执行效率也挺快,都接近raw
pointer.它的独占所有权是如何体现的呢?
因为它不会有copy,只有move,一旦涉及到一些穿参数或者返回等操作的拷贝,那么其实执行的是move,并且不可以将raw指针转化成unique_ptr.再定一个unique_ptr时可以自定义析构函数(默认的是delete).关于自定义析构函数这一部分还没有深究.
此外unique_ptr还提供了两种形式,一种是指向单个对象的模式,另一种是数组的模式:std::unique_ptr<T>和std::unique_ptr<T[]>的模式.因此这不会像raw
pointer那样的困扰,
不过相比std::array, std::vector等容器,不太常用.
不过对于将unique_ptr转化成shared_ptr开放给所有权还是比较方便的,反之不大行.
//可以将std::unique_ptrz转换为std::shared_ptr
std::unique_ptr<int> u(new int);//之前的unique_ptr就无效了.
std::shared_ptr<int> p = std::move(u);
//不可以std::shared_ptr转换为std::unique_ptr
std::shared_ptr<int> u(new int);
std::unique_ptr<int> p = std::move(u);由于shared_ptr中需要一个指针用来做引用计数,所以尺寸至少是裸指针的两倍,此外还有一个该资源的控制块,其中控制块有关于shared_ptr的模块有这些:引用计数,弱计数,自定义deletor,自定义allocator等等.其中关于控制块的规则如下:
- make_shared会创建控制块,并且伴随一个新的资源对象的new.
- 当从auto_ptr和unique_ptr创建处shared_ptr出时,会创建新的控制块.
- 当使用裸指针作为构造参数时,会产生一个新的控制块,同一个裸指针不可以构造多个shared_ptr,因可能不使用裸指针构造shared_ptr.
- 当shared_ptr被shared_ptr作为实参构造,不会创建控制块.
涉及到引用计数的操作代价会挺高,因为这是原子操作.如果就是单纯的move构造,那么不涉及到引用计数,开销会很小.
关于析构器的定义暂时不看.
如果一个类需要被shared_ptr管理,也就是说我们在这个类的成员函数中需要将this指针包装成shared_ptr传递给其他对象(这种情况下返回shared_from_this()是正确规范的).
假设我们将this作为shared_ptr的参数进行初始化,会怎么样的呢?
这样就涉及到裸指针初始化shared_ptr的危害:
当我们使用一个裸指针初始化一个shared_ptr时,会创建一个新的控制块,如果之前没有该资源对应的控制块,还没有什么问题,如果有的话,新的控制块和之前的控制块是隔离的,因此其引用计数也是隔离的,比如说原本引用计数是3,后来用裸指针初始化一个shared_ptr,应该是4,但是却造成了新的shared_ptr是1的情况,即不能和之前的引用计数统一起来,因此容易造成重复销毁资源的现象.
此外,关于std::weak_ptr的使用,其中有力地应对了std::shared_ptr的循环引用问题,比如说如下的例子:
struct A;
struct B;
struct A {
std::shared_ptr<B> pointer;
~A() {
std::cout << "A 被销毁" << std::endl;
}
};
struct B {
std::shared_ptr<A> pointer;
~B() {
std::cout << "B 被销毁" << std::endl;
}
};
int main() {
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->pointer = b;
b->pointer = a;
}在这个实例中,两个对象的引用计数都是2,但是当离开作用域时,只能将引用计数-1,最终引用计数不为0,也就有内存泄漏的风险,对于std::weak_ptr则不会增加引用计数,因此最终避免了这种循环引用问题.由于有一个弱引用指向A,所以离开作用域时,A的引用计数为0,因此A也就析构了,进而B的引用计数也就变成了0,因此析构.
简而言之,循环引用就是,两者互相引用,如果一方想要引用计数清零(被析构),就得等另一方被析构,但是另一方又得等对方引用计数清零,类似于死锁.
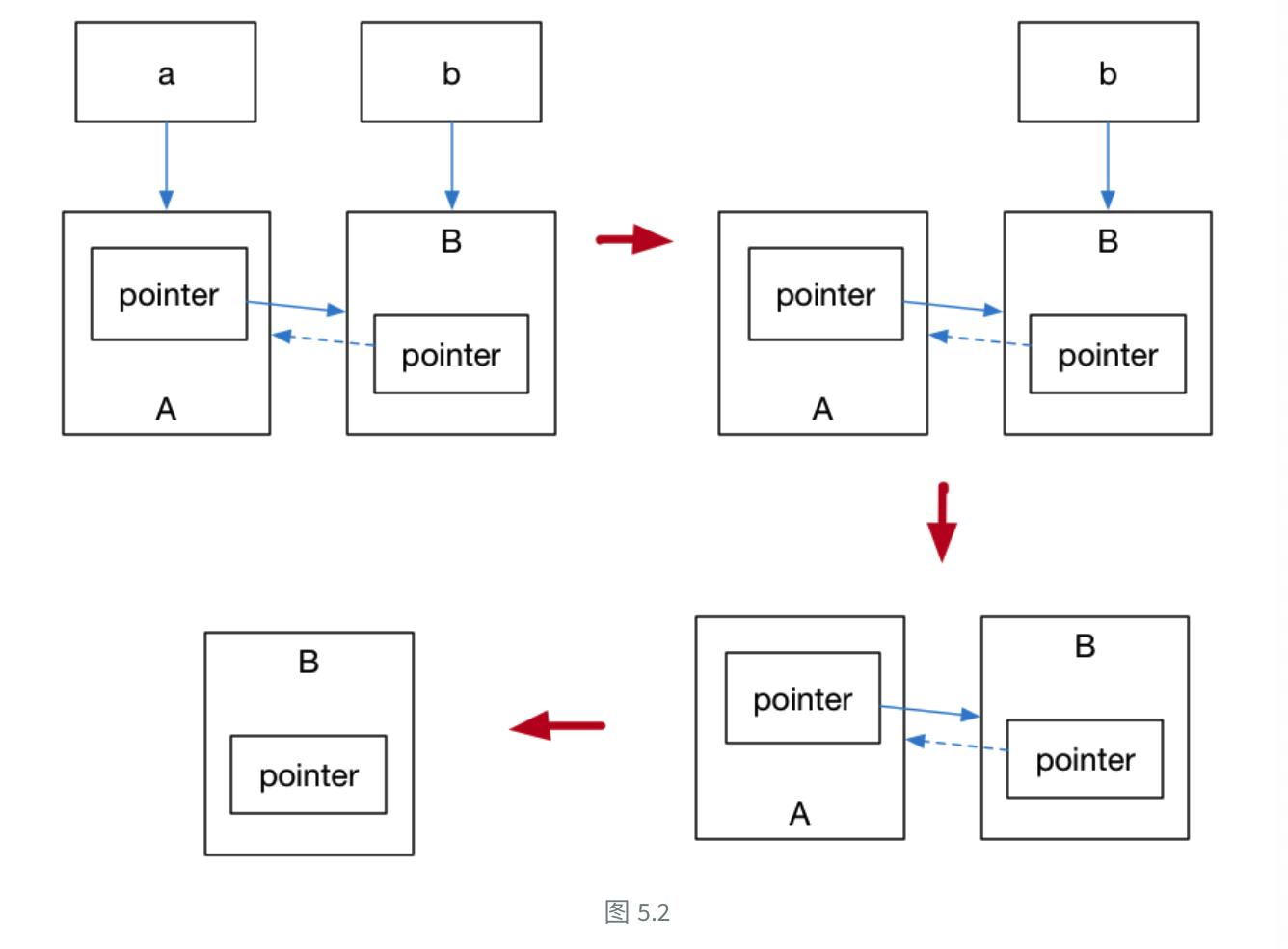
weak的作用非常有限,因为没有*和->方法,用于检查是否有相应的shared_ptr存在,其中expired,会在资源未被释放的时候返回false,还可以从weak_ptr中获取对应的std::shared_ptr(借助lock方法).
2) 关于make的使用
这里鼓励使用make_shared和make_unique代替new.
其使用方式如下:
auto upw1(std::make_unique<Widget>());
std::unique_ptr<Widget> upw2(new Widget);此外关于这种采用基于new来初始化智能指针的情况,有个弊端在于,如果new出现了异常,那么就不会赋值给shared_ptr,该指针得不到有效管理,进而带来内存泄漏的危险.
此外性能也有一定程度的提升,使用new进行初始化首先new出一个对象然后new出来控制块,进行两次动态内存分配,而make_shared则将对象和控制块同时分配.这种性能提升主要是针对make_shared的情况.也就是说make_shared分配的shared_ptr内存不是分离的,而是一体的.
但是make_shared和make_unique不能指定析构器.对于一些自定义的operator new和operator delete都不能用std::make_shared.也就是一些自定义内存管理类.
4.其他Grammatical sugar
1) golang一般的C++ if
这是在C++ 17之后引入的特性.写起来就跟go语言一样.
// 将临时变量放到 if 语句内
if (const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3);
itr != vec.end()) {
*itr = 4;
}同理swicth也是这样的.
此外类似的语法糖还有区间for循环的迭代,这通常用于循环迭代一些容器.
int main() {
std::vector<int> vec = {1, 2, 3, 4};
if (auto itr = std::find(vec.begin(), vec.end(), 3); itr != vec.end()) *itr = 4;
for (auto element : vec)
std::cout << element << std::endl; // read only
for (auto &element : vec) {
element += 1; // writeable
}
for (auto element : vec)
std::cout << element << std::endl; // read only
}2) nullptr的优越性
只是在C++ 11之后引入的新特性,这个常量的功能旨在替代NULL.
首先我们需要明白的是NULL是什么,NULL是一个宏定义(0).可以将其视为一个整形.如果将NULL传递给int等类型的参数或者返回值什么的,也是可以通过的.因此对于下面这种情况是容易出问题的:
void function1(Object *gf);
void function1(int num);
//调用方式
function(NULL);//会调用第二个!这是一种超出预期的结果!所以总的来说,NULL终究只是一个宏,是一个整型(有时候是int有时候是long),一旦涉及到类型转换就会遇到风险.为了避免类似的问题,我们应该尽可能地使用nullptr.
它可以被隐式转换成任何类型的指针.此外,关于智能指针也有对于nullptr的支持,虽然智能指针不是指针而是对象.像下面的这种用法是可以的.
shared_ptr<Girlfriend> gfPtr = nullptr;
unique_ptr<Boyfriend> bfPtr = nullptr; 总的来说,相比NULL,避免了因为NULL是整型而导致的因为隐式转换的意外的重载匹配.
5.Lambda与functional
Lambda类似于匿名函数的作用,我们什么时候会比较需要一个函数呢?
比如说我们需要使用某个函数,但是有没有太大的必要去声明并定义它.
我们可以将std::function作为函数容器来看待,因此函数可以像其他对象那样进行复制,调用,复制等操作,因此抽象了复杂的函数指针等操作.一般情况下,对于functional的定义除了采用lambda之外,还可以采用bind进行定义.std::bind结合std::placeholder可以灵活地处理一些参数不固定的问题.
int foo(int a, int b, int c) {
;
}
int main() {
// 将参数1,2绑定到函数 foo 上,
// 但使用 std::placeholders::_1 来对第一个参数进行占位
auto bindFoo = std::bind(foo, std::placeholders::_1, 1,2);
// 这时调用 bindFoo 时,只需要提供第一个参数即可
bindFoo(1);
}