CMU 15-445:project #1 - Buffer Pool
这一部分,应该算是CMU 15-445中比较简单的一个lab吧,由于之前我做过mit 6.830系列的lab,所以在做这一部分的lab时,其基本的模式与架构还是能够比较快地理解并上手的,不过关于buffer pool这一部分和mit 6.830的simpledb之间还是有些差别.
关于CMU 15-445,project 0太简单了,没什么好说的,所以直接从project 1开始.
1.实验环境
我是采用了Clion+docker的实验环境.在环境配置方面参考了文章:CMU15445 docker+clion开发环境搭建.
docker的作用不必多少,我的电脑是mac m1,感觉一些需要的工具安装起来不太方便,所以直接考虑采用linux下的环境.
关于IDE的话,我本人还是比较钟爱Clion的,我认为它相比vscode有更加智能且稳定的自动补全,而且Clion对于Cmake项目的支持很全面,甚至还以将不符合Clang-Tidy规范的代码引入到Warn,简直方便极了.此外相比将很多操作用命令行实现,Clion的图形界面十分强大,许多原本需要用命令行实现的操作,在Clion点个按钮就可以.如下图所示:
关于调试也是非常方便的,网上的大佬关于c++程序的调试的建议就是使用gdb,Clion的调试器是可以设置为gdb的,相当于与底层调用了gdb但是我们可以以图形化的形式去进行操作,相比直接使用gdb设置断点和显示变量以及查看内存,都方便了不少.
此外Clion这个IDE颜值也很高,感觉在下面这种环境下coding还是颇为赏心悦目的.
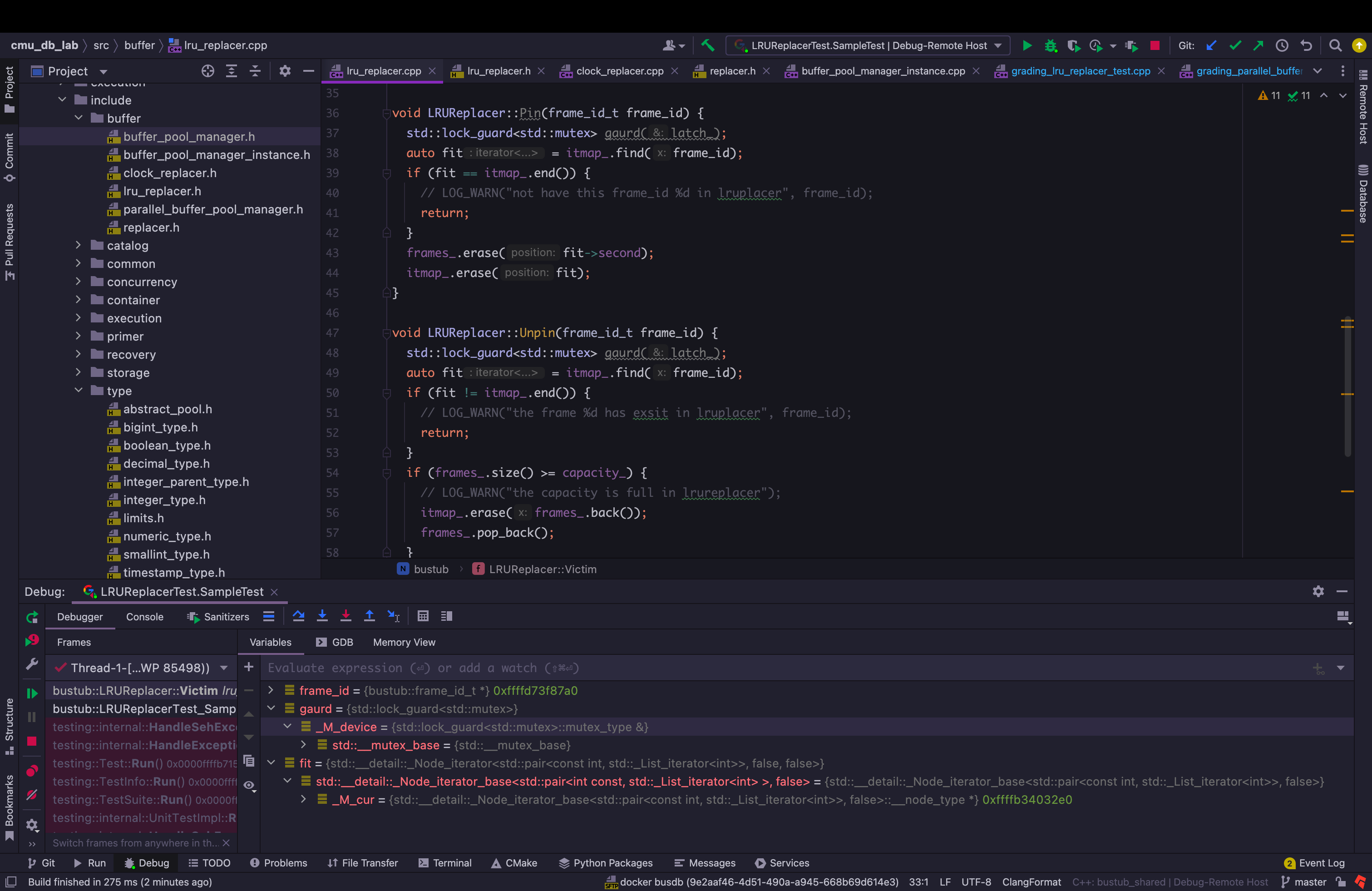
2.实现过程及其细节
1) LRUReplacer
首先在LRUReplacer中,在BufferPoolManagerInstance中会有一个数据对象replacer_,这个类对象用于没有空闲页的时候,会将采用其中replacer从中置换一个页,replacer会维护一个BufferPoolManagerInstance中pages_的子集,并且是没有其中没有经过pin的page.具体而言replacer中,我实现的数据结构如下:
std::mutex latch_;
std::list<frame_id_t> frames_;
std::unordered_map<frame_id_t, frameIt> itmap_;
const size_t capacity_;其中最核心的部分在于frames_,对于LRU这种对于操作主要集中于首尾的算法来说,使用list可以达到比较低的开销.其中的内容是frame_id_t一个整型数,该整型数对应了BufferPoolManagerInstance中pages_数组中的一个索引,也就对应课程中所说的一个页框.这也体现了一个replacer总是归属于一个BufferPoolManagerInstance的.更多细节在BufferPoolManagerInstance后面再说.
至于itmap_则是起到了一个优化的作用,避免对frames_进行遍历.
latch_是我比较疑惑的一个地方,我认为其实没有必要实现它,因为我在后面BufferPoolManagerInstance的实现中也会用大锁把它保护起来,并且每个replacer都是只属于一个BufferPoolManagerInstance的,当然加上了肯定也不算错,但是不加绝对拿不了满分,因为LRU的测试用例中有一个ConcurrencyTest,会对LRURplacer进行单独的多线程测试.
关于LRU算法的实现,可以参考LRU代码实现,C++实现.
LRU算法的一个核心点在于:最近最少使用.
那么在我的实现中,我是根据在list中的位置体现这一点的,当一个frame加入时,会加入到list的头部,当需要选择牺牲页进行移除时,则从尾部移除.
其中关于需要实现的方法,有三个:Victim,Unpin,Pin.首先梳理一下这几个API的基本任务:
- Victim:提出一个牺牲页.
- Pin,当一个页的引用计数(pin_count)从0到1时调用,将其从replacer中移除.
- Unpin,当一个页的引用计数(pin_count)清0时,调用,加入到replacer.
其中的具体实现如下:
bool LRUReplacer::Victim(frame_id_t *frame_id) {
std::lock_guard<std::mutex> gaurd(latch_); //上锁,基于RAII机制的锁.
if (frames_.empty()) {
return false;
}
*frame_id = frames_.back();
auto fit = itmap_.find(*frame_id);
frames_.erase(fit->second);
itmap_.erase(fit);
return true;
}这一部分的实现很简单,如果是空的,直接返回false就好,否则就返回尾部元素到frame_id中,然后在itmaps_,frames_中进行移除就可以了,最终返回true.
关于Pin的实现相对简单,基本上只包含对于itmap_,frames_的移除操作.下面稍微说明一下UnPin:
void LRUReplacer::Unpin(frame_id_t frame_id) {
std::lock_guard<std::mutex> gaurd(latch_);
auto fit = itmap_.find(frame_id);
if (fit != itmap_.end()) {
return;
}
if (frames_.size() >= capacity_) {
itmap_.erase(frames_.back());
frames_.pop_back();
}
frames_.push_front(frame_id);
itmap_[frame_id] = frames_.begin();
}如果这一页之前就已经存在了,那么就不做任何处理,如果已经超出了容量大小,那么就将末尾项移除,最后将frame_id加入到队列的头部,并加入itmap_的记录.此外还有一个SizeAPI也是需要我们实现的,并且也需要上锁,我之前关于这个犯过一个错误如下(在Unpin中):
size_t LRUReplacer::Size() {
std::lock_guard<std::mutex> gaurd(latch_);
return frames_.size();
}
//下面是Unpin函数中的代码
if (Size() >= capacity_) {
itmap_.erase(frames_.back());
frames_.pop_back();
}这样很显然就死锁了!
最后我们发现itmap_这个数据结构的设置果然节省了不少遍历的操作,原本需要我们进行遍历list查找整个某个项是否存在,或者需要定位到某个frame_id在list中的迭代器进行删除(毕竟list不支持以元素的值为基础的erase,一般是定位到对应的迭代器然后erase)的操作都方便了许多.
2) BufferPoolManagerInstance
这一部分对应了task 2,是这个project中最复杂的部分.
仍然从基本的数据成员着手进行分析:
Page *pages_;
DiskManager *disk_manager_ __attribute__((__unused__));
LogManager *log_manager_ __attribute__((__unused__));
std::unordered_map<page_id_t, frame_id_t> page_table_;
Replacer *replacer_;
std::list<frame_id_t> free_list_;
std::mutex latch_;pages_是一个数组,每个Page代表一个固定大小的内存块,buffer是位于disk之上的一层缓存,可以大大减少我们在访问数据时访问disk的次数,将disk中某一个page的内容读取到一个Page下对应的内存缓冲区中,后来对于该page的读写都会直接访问这一块内存缓冲区而不是访问disk.在bustub中关于Page的定义还是比较简洁的,其数据成员如下所示:
char data_[PAGE_SIZE]{};
page_id_t page_id_ = INVALID_PAGE_ID;
int pin_count_ = 0;
bool is_dirty_ = false;其中对应内存缓冲区(存储页的实际内容),page_id(page_id和磁盘中位置存在某种关系),引用计数,是否是脏页.至于其他的API会结合后面的实现进行说明.此外关于Page和BufferPoolManagerInstance的关系,后者是前者的友元,也就是说后者可以访问和修改前者的private,这在后续的实现中是常用的.
关于disk_manager的话,不必多说,毕竟disk才是Page内容的源泉,当需要从disk中读取Page内容或者将Page的内容进行刷盘时,都需要调用它.
page_table_的作用类似于前面的itmap_,frame_id只能说是一个BufferPoolManagerInstance的内部细节,在外部都是通过page_id_t来进行访问的(后面我们需要实现的API都有page_id作为参数),提供page_id到frame_id可以省去很多不必要的遍历查找.
replacer_的话,也不必多说了,感觉前面说的挺清楚了.
free_list_是pages_的一个子集,也就是page_数组中还没有与一个具体的page进行绑定的部分.
当我们需要将一个新分配的Page加入到bufferpool中时,我们首先考虑有没有空闲的Page(也就是free_list_中有没有可用的),如果free_list_为空,那么就需要调用replacer_寻求一个可置换页.对于这些操作,我将其写到了函数FindFreePage中:
bool BufferPoolManagerInstance::FindFreePage(frame_id_t *frame_id) {
if (free_list_.empty()) { // 调用replacer_->Victim,如果是脏页则需要刷盘.
if (auto vicok = replacer_->Victim(frame_id); !vicok) {
return false;
}
page_id_t rpg_id = pages_[*frame_id].GetPageId();
if (pages_[*frame_id].IsDirty()) {
disk_manager_->WritePage(rpg_id, pages_[*frame_id].GetData());
pages_[*frame_id].is_dirty_ = false;
}
page_table_.erase(rpg_id);
} else { // 从free_list_移除一项,并将该项返回到frame_id中.
*frame_id = free_list_.front();
free_list_.pop_front();
}
return true;
}关于task
2需要实现的API,首先说明一下NewPgImp.此API的作用在于在disk上创建一个新的page,并且将该page加入到该buffer
pool中.既然涉及到需要新加入一个page,那么就需要考虑一下几种情况:
- 如果page_中全部pin住了怎么办? 什么也不做,直接返回nullptr.
- 否则,就调用上面提到的FindFreePage,返回一个可用的frame_id.
后续的操作就如下所示了:
*page_id = AllocatePage(); // 分配一个page,返回其page_id
ResetPage(rframe_id); //清空前面FindFreePage获取的frame_id对应的Page的内容(将Page的元数据及内存缓冲区初始化)
pages_[rframe_id].page_id_ = *page_id; // 设置page_id
pages_[rframe_id].pin_count_ = 1; //设置引用计数
replacer_->Pin(rframe_id); //Pin住
page_table_.insert(std::make_pair(*page_id, rframe_id)); //加入到page_table
return pages_ + rframe_id; //返回地址至于FetchPgImp的实现与之颇为相似,最主要的差别就是,FetchPgImp需要检查该page_id是否存在,如果存在就直接将地址返回,否则就用FindFreePage找一个空闲frame或者置换frame,然后设置该frame对应Page的属性(需要设置pin_count为1),此外还需要从diskmanager中载入内容,如下所示.
disk_manager_->ReadPage(page_id, pages_[r_fid].GetData());关于FlushPgImp和FlushAllPgsImp的实现则比较简单,分这几部:
- 判断page是否存在,没有就返回.
- 根据该page是否dirty,如果是dirty就刷盘,并将dirty设置为false.
UnpinPgImp的实现和replacer中的Unpin一定要区分开,前者的Unpin用于将bufferpool中的某个page的引用计数-1(如果减到0,则需要进行replacer_->Unpin),这表示某个线程已经结束了对该page的占用,并且还会将线程是否将该page进行修改表示在is_dirty这个变量里,因此需要注意的是对于page中关于dirty变量的设置,不可以直接赋值,而是应该“或”,因为如果只是简单地赋值的话,比如说thread_1调用了Unpin,其中is_dirty为true,后面有一个thread_2也调用了Unpin,但是is_dirty为false,那么最终该page的dirty就是false,相当于之前进行的修改都无效了.因而在后面的很多刷盘操作中都被忽略了.
其中的具体实现如下:
bool BufferPoolManagerInstance::UnpinPgImp(page_id_t page_id, bool is_dirty) {
std::lock_guard<std::mutex> guard(latch_);
auto page_it = page_table_.find(page_id);
if (page_it == page_table_.end()) {
return false;
}
frame_id_t frame_id = page_it->second;
if (pages_[frame_id].pin_count_ == 0) {
return false;
}
pages_[frame_id].pin_count_--;
pages_[frame_id].is_dirty_ |= is_dirty;
if (pages_[frame_id].pin_count_ == 0) {
replacer_->Unpin(frame_id);
}
return true;
}DeletePgImp则用于将某一个page从bufferpool及其replacer中完全移除(如果被pin住,就什么也不做,直接返回),如果是脏页,则需要刷盘,然后进行相关的移除操作,移除page_table_对应的项,对于pages_将对应的frame项执行ResetPage,然后将该frame加入到free_list_中,还需要调用replacer_->Pin(这里的Pin的作用在于将该frame项从replacer中移除).
关于ResetPage的实现如下:
void BufferPoolManagerInstance::ResetPage(const frame_id_t &frame_id) {
pages_[frame_id].page_id_ = INVALID_PAGE_ID;
pages_[frame_id].pin_count_ = 0;
pages_[frame_id].is_dirty_ = false;
pages_[frame_id].ResetMemory();
}3) ParallelBufferPoolManager
这一部分的实现算是最简单的一部分了.
为什么需要ParallelBufferPoolManager?
简而言之,设计ParallelBufferPoolManager可以减少对于锁的竞争,进而对于很多操作都可以节约时间开销.比如说,我们假设有两种情况:(1) 一个page容量为1000的BufferPoolManagerInstance. (2) 一个ParallelBufferPoolManager其中包含20个page容量为50的BufferPoolManagerInstance.
由于一个BufferPoolManagerInstance就有一把锁,所以第一种情况有1个锁,第二种情况有20个锁.在多线程的情景下,竞争20个锁的情况下,其压力肯定要比竞争1个要小的多.
具体展开ParallelBufferPoolManager的设计思路,它维护了一个固定数量的BufferPoolManagerInstance集合,ParallelBufferPoolManager会根据需要访问的page_id映射到某一个BufferPoolManagerInstance中,在这里映射方式采用取模的方式.如下:
BufferPoolManager *ParallelBufferPoolManager::GetBufferPoolManager(page_id_t page_id) {
auto ins_id = page_id % num_instances_;
return instances_[ins_id];
}之后FetchPgImp,UnpinPgImp,DeletePgImp等API都是先通过GetBufferPoolManager返回对应的对象,然后再调用对应的api的.
唯有NewPgImp稍微复杂一点,实现方式和前面的有些不同.
Page *ParallelBufferPoolManager::NewPgImp(page_id_t *page_id) {
std::lock_guard<std::mutex> guard(latch_);
auto start = next_instance_;
Page *page = nullptr;
while (true) {
page = instances_[next_instance_]->NewPage(page_id);
next_instance_ = (next_instance_ + 1) % num_instances_;
if (page != nullptr) {
break;
}
if (next_instance_ == start) {
break;
}
}
return page;
}采用一种类似于轮询的方式,保证每次都能从不同的起点开始轮询,轮询过程中如果有结果就返回,如果没有结果就返回nullptr.
3.一些trick
最近刚刚粗读了一点关于modern c++的内容,正好这个项目也是通过c++
17实现的.
1) 锁
在此我使用了std::lock_guard,配合一般的std::mutex可以实现RAII机制的上锁与解锁.使用起来还是非常方便的.
我关于锁的控制粒度是比较粗的,一般都是函数粒度的.比如说像上面的NewPgImp中的运用.
2) 尽量延迟变量出现的时间
这个条例出现在《Effective
C++》中的第26条.其中我的NewPgImp(BufferManagerInstance)中就体现了这一点,因为该函数需要在占用一个frame的空间,所以在此之前需要检查是否有可用的空闲frame或者可置换的frame,如果没有就什么也不多,直接返回nullptr,如果在此之前将allocate调用,则就造成浪费.
3) list和map的搭配使用
在这个project中,其中relacer_有这样的数据结构搭配,如下代码所示.相比单独使用list,这样虽然增加了编程的复杂度,因为需要额外增加对于map部分的增,删,改,但是却大大增加了遍历或者查找的便利性.
std::list<frame_id_t> frames_;
std::unordered_map<frame_id_t, frameIt> itmap_;其中在BufferManagerInstance中也存在类似的使用情况:
Page *pages_;
std::unordered_map<page_id_t, frame_id_t> page_table_;如果没有page_table_,对于一个给定的page_id将必须通过遍历pages_数组来实现.
4.踩过的坑
1) 成员函数中的静态变量
关于ParallelBufferPoolManager中的NewPgImp中的next_instance_变量,我最初是以一个成员函数中的static变量实现的,但是由于static变量会在整个程序的类中是共享的,所以不能表示每个类都独有一个next_instance_变量.
所以最终我采用了设置next_instance为类中的成员数据.
2) 一些关于Clang-tidy的坑
如果存在某些Clang-tidy的规范不符合的话,提交到gradescope上之后会显示超时,所以超时其实不一定是死锁或者死循环的原因,最好好好检查一下代码风格的规范问题.
3) 打印日志对程序运行的影响
当进行测试或者提交上时,尤其是提交时,注释掉日志打印,因为这会给程序的运行带来很大的影响,会拖慢程序,一些原本可以通过的测试点,如果加上日志打印可能就运行不正确了.