cs143:PA5,代码生成
我认为这一部分是cs143中最难的一部分,前面的几个实验,都可以通过参考手册上的形式化表示(语法、语义等)来写代码,然而PA5则没有类似的参考,因此我们需要具备能将高级语言(cool)翻译成SPIM汇编的能力,要了解一门之前不怎么熟悉的汇编语言.此外这里涉及到的有关于环境表的操作也更加复杂.
这几部分的核心操作是将经过语义分析后,已经得到了一个信息完整、无误(语义分析检查了错误,如果出了错也就不会继续处理了)的AST,然后将这个AST转化成汇编代码的过程.除了翻译成汇编指令,此外还有一些比较重要的东西,就是关于生成汇编代码文件中关于段(类似于代码段、数据段等)的理解与生成.
我的代码实现如下: github
1. 主干流程与核心数据结构
其中和cgen有关的主函数为:
void program_class::cgen(ostream &os) {
// spim wants comments to start with '#'
os << "# start of generated code\n";
initialize_constants();
envTable = new EnvTable();
codegen_classtable = new CgenClassTable(classes,os);
os << "\n# end of generated code\n";
}首先需要初始化一些常量,然后初始化环境表,然后创建一个CgenClassTable.
1) CgenClassTable中需要的数据结构
至于我的CgenClassTable中的数据成员如下:
class CgenClassTable : public SymbolTable<Symbol,CgenNode> {
public:
typedef std::vector<attr_class*> attrList;
typedef std::vector<method_class*> methodList;
typedef std::map<Symbol, int> attroffsetList;
typedef std::map<Symbol, int> methoffsetList;
typedef std::vector<std::pair<Symbol, Symbol>> dispatchtab;
typedef std::vector<CgenNodeP> chain;
private:
List<CgenNode> *nds; // 维护的整个程序中的所有class
std::map<int, Symbol> class_tag_map_;
std::map<Symbol, CgenNodeP> name_to_cgen_map_;
std::map<Symbol, attrList> class_attr_map_; // 不包含parent中的attr
std::map<Symbol, methodList> class_method_map_; // 每个class本层method
std::map<Symbol, attroffsetList> attr_offset_map_;
std::map<Symbol, methoffsetList> meth_offset_map_;
std::map<Symbol, dispatchtab> dispatch_tab_map_;
std::map<Symbol, chain> parent_chain_map_;
ostream& str;
int stringclasstag;
int intclasstag;
int boolclasstag;
int labelid_;
CgenNodeP curr_cgenclass_;其中nds表示的是整个AST中所涉及的所有class.class_tag_map_将会用于保存class
tag到某个class的映射关系,以这个map的顺序遍历(即int从0,1,2....到n)可以很方便地打印出name
table,obj
table等等.name_to_cgen_map_用于外界可以通过class的name来获取其对应的CgennodeP.关于class_attr_map_,class_method_map_用于通过某个class的name来获取其对应的attributes和methods(只包含继承体系中的本层).attr_offset_map_,meth_offset_map_分别保存了每个class中,每个attribute/meth名在其protObj/dispTab中的偏移量,因为在后续的汇编代码中,我们需要再获取了某个class对应的protObj/dispTab的地址后,知道要访问的attr/meth在其中的偏移量,进而得到其精确的地址.dispatch_tab_map_对应了每个class的distratch表.chain则用于获取一个class的继承链,在后面的处理中,我们会多次需要获取某个class的继承链,一次保存好之后,直接获取即可.
2) CgenClassTable的构造函数
在其构造的过程中,进行以下操作:
CgenClassTable::CgenClassTable(Classes classes, ostream& s) : nds(NULL) , str(s),
labelid_(0),
curr_cgenclass_(nullptr) {
stringclasstag = 0 /* Change to your String class tag here */;
intclasstag = 0 /* Change to your Int class tag here */;
boolclasstag = 0 /* Change to your Bool class tag here */;
codegen_classtable = this;
enterscope(); // 进入一个全局的作用域
if (cgen_debug) cout << "Building CgenClassTable" << endl;
install_basic_classes();
install_classes(classes);
install_name_to_cgen();
build_inheritance_tree();
install_classtags();
install_attrs_and_methods();
code();
exitscope();
}其中过程总结如下:
- 首先先进入到一个全局的作用域.
- 首先是对于一些basic class以及其他classes的安装.
- 调用
install_name_to_cgen(),将CgenClassTable中的name_to_cgen_map_设置好即可,只需将nds遍历一遍. build_inheritance_tree(),构造继承树,这里主要涉及到对于CgenNode中的parent以及children的设置.install_classtags(),设置每个class对应的tag.这一部分我最初只是按照遍历nds数组的顺序设置的对应的tag,但这样在后来实现typcase时会踩坑(后面再说),参考了别人的实现才知道,这里比较好的方式是通过dfs序去设置tag.install_attrs_and_methods(),遍历每个class,设置class_meth_map_和class_attr_map_.- 调用code(),生成目标代码.
- 退出全局作用域.
3) 代码生成的大致流程
这部分也就是code函数中的操作.其实现如下:
void CgenClassTable::code() {
if (cgen_debug) cout << "coding global data" << endl;
code_global_data();
if (cgen_debug) cout << "choosing gc" << endl;
code_select_gc();
if (cgen_debug) cout << "coding constants" << endl;
code_constants();
if (cgen_debug) cout << "coding class name tab" << endl;
code_class_nametabs();
if (cgen_debug) cout << "coding class object table" << endl;
code_class_objtabs();
if (cgen_debug) cout << "coding object dispatabs" << endl;
code_object_disptabs();
if (cgen_debug) cout << "coding object prot" << endl;
code_protobjs();
if (cgen_debug) cout << "coding global text" << endl;
code_global_text();
if (cgen_debug) cout << "coding object init method" << endl;
code_object_inits();
if (cgen_debug) cout << "coding methods" << endl;
code_methods();
}这一部分的流程通过阅读标准代码生成器的输出汇编代码即可了解个大概,在code_method之前的都是一些信息表代码的生成.
2. 一些信息表的理解与生成
1) name table 和 object table
name table是一个字符串常量表,其中分别对应了每个class
name的字符串常量.object
table包含了每个class的protObj和init_method.具体如下:
class_nameTab:
.word str_const7
.word str_const8
.word str_const12
.word str_const13
.word str_const9
.word str_const10
.word str_const11
.word str_const14
class_objTab:
.word Object_protObj
.word Object_init
.word IO_protObj
.word IO_init
.word Base_protObj
.word Base_init
.word Derived_protObj
.word Derived_init
.word Int_protObj
.word Int_init
.word Bool_protObj
.word Bool_init
.word String_protObj
.word String_init
.word Main_protObj
.word Main_init在生成这一部分的代码时,有一个比较坑的地方在于,这两个表的排列顺序应该严格遵循class
tag(比如说Object的tag是0,在objTab中的顺序就是第0项).在后面实现new__class的时候,对于SELF_TYPE的情况,如果想要获取其init函数以及protObj地址,需要通过从$s0加偏移量获取其tag,然后感觉tag去从class_objTab中检索出对应的protObj和init项,如果这两个表的顺序并不是严格遵循tag顺序的,那么就无法检索到正确的项.
因此在写这一部分的代码生成时,需要根据tag的顺序去进行遍历:
void CgenClassTable::code_class_objtabs() {
str << CLASSOBJTAB << LABEL;
int len = class_tag_map_.size();
StringEntry* str_entry;
for (int i = 0; i < len; i++) {
Symbol name = class_tag_map_[i];
str << WORD;
emit_protobj_ref(name, str);
str << endl;
str << WORD;
emit_init_ref(name, str);
str << endl;
}
}2) dispatch table
关于dispatch table的实现,我最初对于每个class的dispatch的排列顺序并没有太多的讲究,还要考虑override的情况,但是如果不注意的话,dispach多态的特点不会有正确的实现.我认为这个地方是整个PA5中对容易让人绕晕的地方.
首先,分析一下在PA5中多态实现的方式,参考C++中的多态,其核心的机制在于动态绑定,也就是说最终所调用的method的地址无法在编译期间确定.在dispatch的处理中,这一部分的难点在于我们编写的编译器代码和运行时的状态存在不同,比如说下面的me.identify.
let me : Base <- new Derived in me.identify();我们首先执行me相关的生成代码,经过new
Derived的初始化后,me作为let中声明的临时变量被压入栈,这个时候从编译器AST中的语义值的角度上看,me是Base类型的,但是从汇编的角度上来看,通过new
Derived之后(详情见后面对于new__class生成代码的讲解),其返回值对应的是Derived类型,获取其dispacth
table时也是Derived的dispacth
table,然而我们在编译器代码中无法访问到该寄存器的具体情况,因此在我们编写编译器代码时,我们仍然是将其当做一个Base处理.之后我们需要获取该identify的地址,因此需要求出其偏移量,求出偏移量之后,进而得出最终该method的地址.其中相关的实现如下:
emit_load(T1, DISPTABLE_OFFSET, ACC, s); // 将dispacth表加载到T1中,这时的dispatch为Derived的
int offset;
Symbol expr_type = expr->get_type(); // 从AST树节点的保存的类型信息中,我们得到的是Base类型的
if (expr_type == SELF_TYPE) {
expr_type = codegen_classtable->get_curr_class()->get_name();
}
codegen_classtable->get_meth_offset(expr_type, name, &offset); // 由于expr_type是Base,查找offset时用的也是Base的dispacth表
emit_load(T1, offset, T1, s); // 求出offset后,根据dispacth table的地址获取该method的地址
emit_jalr(T1, s); // 调用该method因此我们简单的一总结,在PA5实现多态时,编译器层面的代码只能将调用对象当做一个基类处理,而并不是具体类.然而在运行时汇编的层面上,该调用对象则是一个具体类.我们需要保证“基类中的offset” + “具体类的dispacth”加起来正好是这个具体类的method的地址.结合这一部分生成的dispacth表:
Derived_dispTab:
.word Object.abort
.word Object.type_name
.word Object.copy
.word IO.out_string
.word IO.out_int
.word IO.in_string
.word IO.in_int
.word Derived.identify
Base_dispTab:
.word Object.abort
.word Object.type_name
.word Object.copy
.word IO.out_string
.word IO.out_int
.word IO.in_string
.word IO.in_int
.word Base.identify我们在编译器代码中,通过查找offset从Base_dispacth找到的是offset是7,在汇编层面,T1中加载的是Derived_dispTab,其中的7,恰好就是Derived.identify.因此实现了override.
因此在生成dispacth相关的代码中,由下面的这种方式的处理:
auto chain = curr_cgennode->get_parents_list();
for (auto parent : chain) {
// 获取其中一层的method
auto methods = class_method_map_[parent->get_name()];
for (auto method : methods) { // 获取其中的method
Symbol meth_name = method->get_name();
if (meth_offset_map_[curr_name].find(meth_name) == meth_offset_map_[curr_name].end()) {
dispatch_tab_map_[curr_name].push_back({parent->get_name(), meth_name});
meth_offset_map_[curr_name][meth_name] = dispatch_tab_map_[curr_name].size() - 1;
} else {
auto meth_offset = meth_offset_map_[curr_name][meth_name];
dispatch_tab_map_[curr_name][meth_offset] = {parent->get_name(), meth_name};
}
}
}首先我们需要获取该class(cgen
node)的继承链,然后遍历继承链中的每个method,如果不是重名的,直接往dispatch_tab_map_后面追加就好了,并设置好相应的offset
map.如果出现重名的method的情况,这种情况对应了派生类对某个父类的method进行override的情况,因此就需要将之前的method替换成这个派生类的版本.这最终呈现的效果是,在同一个继承链的dispacth中,同名的method处于同一个offset上.
这一部分,不知我讲没讲明白......
3) protoobj
这一部分手册中比较详细的说明,我们只要搞清楚有哪些字段,这些字段都有什么意义就好了.
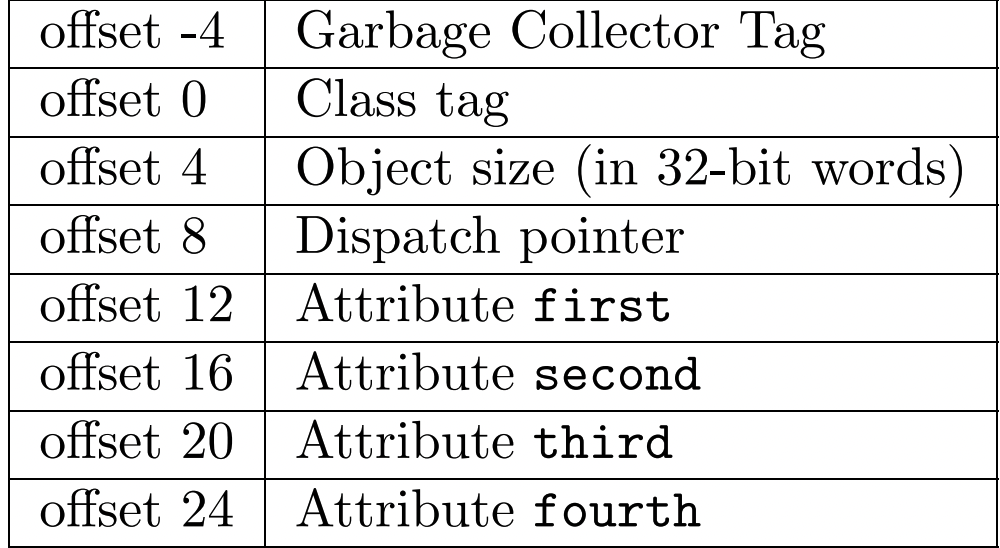
实际的代码如下:
.word -1
String_protObj:
.word 6
.word 5
.word String_dispTab
.word int_const0
.word 0offset-4用于给垃圾回收做标识,Class tag通过查找之前构造的class_tag_class即可,Object size通过3 + 参数数量可以得出,其中的3包括class tag, object size, dispacth pointer.然后是dispTab的地址,下面是各个attribute,需要设置为默认初始值.其中相关的设置代码如下:
if (attr_type == Str) { // 这个地方的处理尚待修改
StringEntry *strentry = stringtable.lookup_string("");
strentry->code_ref(str);
} else if (attr_type == Bool) {
falsebool.code_ref(str);
} else if (attr_type == Int) {
IntEntry *intentry = inttable.lookup_string("0");
intentry->code_ref(str);
} else {
str << 0;
}对于Int,Bool,Str设置成各自的默认值,如果是其他类型的话,设置成0就好.
3. 环境表的管理与实现
这里的环境表相比语义分析的要复杂一些,之前语义分析的只是记录变量名及其类型,而这里记录的则是临时变量的对于FP寄存器的偏移量,从而使得在生成汇编代码时,能够确定其偏移量.之前语义分析的环境表中,可以对attribute,formal,local变量不加区分的加入到环境表中,但是这一点对于代码生成的环境表来说并不适用,因为不同类型的变量需要有不同的访问方式:
- 像attribute通过SELF($s0)寄存器加偏移量即可访问,我们没有将其加入到环境表中,而是通过访问之前的attribute_offset_map完成.
- formal的对于FP的偏移量应该是正数,并且最小是3,因为在调用函数时,其入栈的顺序为formal(参数),old FP,self,return address.
- local变量的对于FP的偏移量应该是负数.这里local包含typcase,let等表达式对于变量的声明,这些都是位于当前函数的栈帧之后要压入的.
在我的实现中,我不在环境表中保存attributes,只保存formal和local两种类型的变量,虽然不使用环境表来保存attributes,但是我会在通过环境表lookup变量时,也对attr_offset_map_进行查找,并且由于attributes往往位于更外层的作用域中,因此将其检查优先级处于环境表之后,如下所示:
if (envTable->lookup(name, &offset)) {
emit_load(ACC, offset, FP, s);
emit_gc_update(FP, offset, s);
return;
}
if (codegen_classtable->get_attr_offset(curr_cgen->get_name(), name, &offset)) { // 属于attr类型的
emit_load(ACC, offset, SELF, s);
emit_gc_update(SELF, offset, s);
}关于其具体实现如下:
class EnvTable {
public:
typedef std::list<std::pair<Symbol, int>> symbol2offsetList;
private:
std::list<symbol2offsetList> envlist_;
int formal_fp_offset_; // 用来记录当前formal对于fp的偏移
int local_fp_offset_; // 用来记录当前local变量对于fp的偏移
int last_local_fp_offset_;
void init_formal_fpoffset() {
formal_fp_offset_ = DEFAULT_OBJFIELDS;
}
void init_local_fpoffset() {
local_fp_offset_ = -1;
last_local_fp_offset_ = -1;
}
public:
EnvTable() = default;
~EnvTable() = default;
void enterframe();
void exitframe();
void enterscope();
void exitscope();
void add_formal_id(Symbol name);
void add_local_id(Symbol name);
bool lookup(Symbol name, int *offset); // 通过参数返回
};环境表需要设置一些变量用来追踪当前栈帧的状况,尤其是当需要push一个变量时,其应当处于的偏移量.这个偏移量需要随着push以及exitscope而更新.在这里当开辟一层新的函数frame时,毫无疑问其formal_fp_offset_是从+3开始的,每次push参数就使其+1,不过在对参数遍历时要注意add的顺序.关于local变量的初始偏移,我是从-1开始的,这个取决于你所生成的method汇编代码中,关于栈帧的初始化操作之后SP所处位置相对于FP的偏移量.我的情况是这样的:
addiu $sp $sp -12
sw $fp 12($sp)
sw $s0 8($sp)
sw $ra 4($sp)
addiu $fp $sp 4当函数执行完这一系列初始化操作时,此时SP正好处于FP - 4的位置上,我们所要加入的下一个local变量就会处于此时的SP上,也就是所谓的-1的位置.之后再有push的新的local变量则是-2,-3地递减.我在参考别人的代码时,发现有人是从-3开始的,我感觉我的也没错.
关于一层新的函数frame的创建与一层作用域的创建,我最初有些混淆.其实两个的行为略有差别,当进入一层新的函数frame之后,有关于local和formal的偏移量都需要进行初始化,当需要进入一层新的作用域时,其实并不需要.当离开一层函数frame时也需要对两者的偏移量进行初始化,但是如果仅仅退出的是一个普通的作用域的话,只需要将其上面local弹出就可以了,也就是只需要调整local_fp_offset.其相关的实现如下:
void EnvTable::enterframe() {
init_formal_fpoffset();
init_local_fpoffset();
enterscope();
}
void EnvTable::exitframe() {
exitscope();
init_formal_fpoffset();
init_local_fpoffset();
}
void EnvTable::enterscope() {
last_local_fp_offset_ = local_fp_offset_; // 保存进入新作用域之前的local fp偏移量
envlist_.push_back({});
}
void EnvTable::exitscope() {
envlist_.pop_back();
local_fp_offset_ = last_local_fp_offset_; // 借助一个last变量恢复到当前作用域之前的local fp偏移量
}我觉得我这个地方的处理还是蛮巧妙的,我敢保证你从网上查到的有关于cs143的代码还真没有人这样写的(不过大体思路都差不多哈哈).具体在进行调用时,如果是涉及到对某个method的操作,就是用enterframe,exitframe,否则就是enterscope,exitscope.
4. 翻译成汇编代码
1) init method的生成
init method的作用相当于C++ class中的无参数构造函数.
其相关的实现如下:
void CgenClassTable::code_object_inits() {
CgenNodeP curr_cgen;
for (List<CgenNode> *l = nds; l; l = l->tl()) {
curr_cgen = l->hd();
curr_cgenclass_ = curr_cgen;
emit_init_ref(curr_cgen->get_name(), str);
str << LABEL;
emit_start_frame(str);
envTable->enterframe();
CgenNodeP parent = curr_cgen->get_parentnd();
if (parent && parent->get_name() != No_class) {
str << JAL;
emit_init_ref(parent->get_name(), str);
str << endl;
}
// 处理中间的attr,这一部分比较复杂, 只是处理本层的attr
const attrList& curr_attrs = class_attr_map_[curr_cgen->get_name()];
for (auto attr : curr_attrs) {
Expression init_expr = attr->get_init();
Symbol attr_type = attr->get_type();
if (!init_expr->is_empty()) {
init_expr->code(str);
int attr_off = attr_offset_map_[curr_cgen->get_name()][attr->get_name()];
emit_store(ACC, attr_off, SELF, str);
emit_gc_update(SELF, attr_off, str);
}
}
emit_move(ACC, SELF, str);
emit_end_frame(str);
envTable->exitframe();
emit_return(str);
}
}其生成方式需要对每个class进行遍历,
然后通过emit_init_ref打印出标签.由于则是一个函数,因此需要在环境表中开辟新的函数栈帧即:envTable->enterframe,并且生成函数的初始化代码(emit_start_frame).然后根据是否存在parent判断是否需要调用父类的init
method函数.之后再对本层的attribute进行处理,由于调用父类的init(父类如果还有父类就会继续调用init)递归地初始化了父类之前的参数,所以只要处理本层的attribute就可以了.在本层的处理中,需要判断init是否为空的,否则就不做处理(使用当时生成protoobj时的默认值就可以),如果init不为空,就调用其code生成代码.由于code生成的代码运行完后,ACC中保存的是init_expr表达式所产生对象的地址,将其地址(ACC)保存到该attribute的地址即可.(这里的赋值操作都是类似于浅拷贝的地址赋值).处理完参数后,再将SELF($s0)保存到ACC中,作为init函数的返回值.之后调用emit_end_frame即一个函数要结束时的弹栈,同时环境表也退出该函数栈帧.最终返回.
其中emit_end_frame和emit_start_frame如下:
static void emit_start_frame(ostream &s) {
emit_addiu(SP, SP, -12, s);
emit_store(FP, 3, SP, s);
emit_store(SELF, 2, SP, s);
emit_store(RA, 1, SP, s);
emit_addiu(FP, SP, 4, s);
emit_move(SELF, ACC, s);
}
static void emit_end_frame(ostream &s) {
// emit_move(ACC, SELF, s);
emit_load(FP, 3, SP, s);
emit_load(SELF, 2, SP, s);
emit_load(RA, 1, SP, s);
emit_addiu(SP, SP, 12, s);
}2) method与dispacth
我认为将这两部分结合起来理解才能全面地理解method调用的全部过程.
关于method的代码生成,相关代码实现如下:
for (auto method : methods) {
formal_list.clear();
envTable->enterframe();
curr_formals = method->formals;
for (int i = curr_formals->first(); curr_formals->more(i); i = curr_formals->next(i)) {
formal_list.push_front(curr_formals->nth(i));
}
for (auto formal : formal_list) {
envTable->add_formal_id(formal->get_name());
}
emit_method_ref(curr_cgenclass_->get_name(), method->get_name(), str);
str << LABEL;
emit_start_frame(str);
method->expr->code(str);
emit_end_frame(str);
emit_addiu(SP, SP, formal_list.size() * WORD_SIZE, str);
emit_return(str);
envTable->exitframe();
}对于某个class的method,首先调用环境表的enterframe,然后遍历formal并且以逆序的方式加入到list中,之后再将list中的formal加入到环境表中,比如说如果有formals为{a,b,c,d},那么list就是{d,c,b,a},在进行add的时候记录在环境表中的偏移量就是{d:+3,
c:+4, b:+5, a:+6}.恰好符合手册中给出的模式.

打印出该method的标签代码.然后通过emit_start_frame生成初始化该函数栈帧的汇编代码,再对函数体生成代码method->expr->code(str).结束后,生成函数栈帧弹出的相关的代码,并且之前弹出push过的参数即emit_addiu(SP, SP, formal_list.size() * WORD_SIZE, str);.随后返回,此时环境表也需要退出当前的frame.
需要注意的是,method的生成代码只是包含该函数本身的汇编代码,并没有涉及到对formal的push代码,只是将formal加入到环境表中,因为在函数体的生成代码中,往往需要访问到formal,并确定formal对FP的偏移量.
关于dispacth.相关代码如下:
void dispatch_class::code(ostream &s) {
// 首先将参数对应的表达式一个个压栈
Expression curr_expr;
for (int i = actual->first(); actual->more(i); i = actual->next(i)) {
curr_expr = actual->nth(i);
curr_expr->code(s);
emit_push(ACC, s);
}
expr->code(s); // 求出来self所对应的指针
int lebalid = codegen_classtable->get_labelid_and_add();
emit_abort(lebalid, get_line_number(), s);
emit_label_def(lebalid, s);
emit_load(T1, DISPTABLE_OFFSET, ACC, s); // 将dispacth表加载到T1中
int offset;
Symbol expr_type = expr->get_type();
if (expr_type == SELF_TYPE) {
expr_type = codegen_classtable->get_curr_class()->get_name();
}
codegen_classtable->get_meth_offset(expr_type, name, &offset);
emit_load(T1, offset, T1, s); // 获取该dispatch在表中的地址
emit_jalr(T1, s);
}首先需要对每个formal生成其表达式,并且将其push到栈中(与method中相呼应).之后对expr生成代码,此时ACC中就保存了expr所对应的对象的地址,中间还涉及到对于no_object的判断,也就是ACC为0的情况,这种情况下需要调用emit_abort处理.
static void emit_abort(int lebal, int lineno, ostream &s) {
emit_bne(ACC, ZERO, lebal, s);
s << LA << ACC << " str_const0" << endl;
emit_load_imm(T1, lineno, s);
emit_jal("_dispatch_abort", s);
}如果不进行abort的处理,就先载入dispacth到T1中,然后查找offset,最后得出要执行的函数的地址.这个过程中有可能涉及到动态绑定,在前面讲过.至于static_dispacth则与之类似.
3) let,object
这一部分都涉及到了有关于环境表中local变量的操作.
let会引入新的临时变量声明(可能也有init)和新的作用域.其相关代码实现如下:
void let_class::code(ostream &s) {
// 首先处理的时init,要区分是否为empty的情况
init->code(s);
if (init->is_empty()) {
if (type_decl == Int) {
emit_load_int(ACC, inttable.lookup_string("0"), s);
} else if (type_decl == Str) {
emit_load_string(ACC, stringtable.lookup_string(""), s);
} else if (type_decl == Bool) {
emit_load_bool(ACC, falsebool, s);
}
}
// 然后进入新的frame,并加入变量,但是这个偏移量是需要调整的
emit_push(ACC, s); // 将init对应的变量,也就是let定义的变量加入到其中
envTable->enterscope();
envTable->add_local_id(identifier); // 加入到其中
body->code(s);
envTable->exitscope();
emit_addiu(SP, SP, 4, s);
}首先对init进行代码生成,对于如果init是空的情况,则需要设置成默认的初始值.由于是一个新的local变量的引入,因此需要将其push到栈上,然后环境表中创建新的作用域,并且加入该变量(add_local_id).再对body进行代码生成,之后在环境表中弹出该作用域,并且将之前压入的local变量弹出(emit_addiu(SP, SP, 4, s)).这里需要注意的是,不要将init处于新的作用域之中,也就说先处理完init,然后再创建作用域并加入local变量.
有关于object的处理:
void object_class::code(ostream &s) {
if (name == self) {
emit_move(ACC, SELF, s);
return;
}
// 如果是当前class中的attr
CgenNodeP curr_cgen = codegen_classtable->get_curr_class();
int offset;
if (envTable->lookup(name, &offset)) {
emit_load(ACC, offset, FP, s);
emit_gc_update(FP, offset, s);
return;
}
if (codegen_classtable->get_attr_offset(curr_cgen->get_name(), name, &offset)) { // 属于attr类型的
emit_load(ACC, offset, SELF, s);
emit_gc_update(SELF, offset, s);
}
}如果是self,最终的返回结果则是SELF.否则就先通过环境表查找符合该name的local或者formal变量,如果没有从当前class中的attribute中进行查找,这也体现了attribute往往位于更外层的作用域的特点.
4) new
关于new的处理,简而言之就是确定好类型之后调用Object.copy,之后再调用其init函数.
void new__class::code(ostream &s) {
std::string object_name = type_name->get_string();
if (type_name == SELF_TYPE) {
// 首先获取此时的class
// CgenNodeP curr_cgen = codegen_classtable->get_curr_class();
// object_name = curr_cgen->get_name()->get_string(),不可以使用curr_class类似的方式
emit_load(T1, 0, ACC, s); // 首先获取class tag
emit_load_address(T2, CLASSOBJTAB, s); // 获取objtab
emit_sll(T1, T1, 3, s); //获取了offset
emit_add(T2, T1, T2, s); // 获取的对应的proobj地址
emit_load(ACC, 0, T2, s); // 地址中的内容
emit_jal("Object.copy", s);
emit_load(T1, 0, ACC, s); // 首先获取class tag
emit_load_address(T2, CLASSOBJTAB, s);
emit_sll(T1, T1, 3, s);
emit_add(T2, T1, T2, s); // 获取的对应的init地址
emit_load(A1, 1, T2, s);
emit_jalr(A1, s);
} else {
std::string protobj_object = object_name + PROTOBJ_SUFFIX;
emit_load_address(ACC, const_cast<char *>(protobj_object.c_str()), s);
emit_jal("Object.copy", s);
std::string init_object = object_name + CLASSINIT_SUFFIX;
emit_jal(const_cast<char *>(init_object.c_str()), s);
}
}其中对于非SELF_TYPE的处理还是比较简单的.而对于SELF_TYPE需要先获取class
tag,然后通过class tag从object table中检索出对应的项.回忆之前的object
table,需要将tag *
8才能得到偏移,也就是emit_sll(T1, T1, 3, s),因为每一项占4个字节,每个class有2项.因此可以获取proobj的地址,进而可以调用Object.copy返回新分配的对象的地址到ACC中.之后再以类似的方法获取init地址,并且调用即可.
总之,需要牢记的是,在这个实验中,所涉及的对象的赋值,创建和返回等操作都是对象的地址完成的.
5) typcase
这一部分的实现逻辑相对来说是比较复杂的.关于其语法规则,比如说下面的代码:
case self of
n : Bazz => (new Foo);
n : Razz => (new Bar);
n : Foo => (new Razz);
n : Bar => n;
esac;首先计算出self,然后self尝试对逐个case的类型进行匹配,其中n将会被self赋值,并且作为case中的临时变量.如果符合某个case的类型,则会返回其对应的表达式.通过语义分析,我们可以确定这几个case中涉及到的类型都是处于同一个继承链之下的.self所要匹配的是在继承链中和他关系最近的类型.
因此在翻译汇编代码时,首先需要生成self对应的代码,然后收集case中的class type,对其进行排序,处于继承链尾端(辈分小的)排在前面.然后对排好序的case进行遍历,在遍历每个case时,通过比对tag来确定是否匹配(在运行时,一旦匹配到tag,就执行对应的表达式代码,而不是继续运行next_lebal).其相关的代码如下:
for (auto case_class : sorted_cases) {
// emit_branch(out_lebal, s);
Symbol cgen_type = case_class->get_type_decl();
CgenNodeP cgen = codegen_classtable->get_cgennode(cgen_type);
int next_case_lebal = codegen_classtable->get_labelid_and_add(); // 获取新lebal
// 通过比较tag确定是否是后代
int start_tag = cgen->get_classtag();
int end_tag = start_tag + cgen->get_descendants_cnt();
emit_blti(T1, start_tag, next_case_lebal, s);
emit_bgti(T1, end_tag, next_case_lebal, s);
// 将expr对应的对象入栈
emit_push(ACC, s);
envTable->enterscope();
envTable->add_local_id(case_class->get_name());
case_class->get_expr()->code(s); // 生成代码
envTable->exitscope();
emit_addiu(SP, SP, 4, s);
emit_branch(out_lebal, s); // 结束跳转出去
emit_label_def(next_case_lebal, s); // 不做中间的处理*/
}之所以要排序,是因为这样可以保证辈分小的class
type可以先匹配到.结合上面代码,首先获取新的lebal,随后获取当前case的tag,并根据之前求的子孙数来确定匹配范围.之后则生成匹配成功相关的代码,需要将case中声明的临时变量入栈(也就是ACC,因为该临时变量是与最初的变量相绑定的).之后的生成代码方式类似于let.之后生成emit_branch(out_lebal, s),这是只有匹配成功才会运行指令.然后是next_lebal,这是匹配失败直接跳转到的地方.
dfs序、子孙数、匹配范围
之前我们提到过,我们在设置class tag时采用的dfs序.如果想通过class tag来判断某个class A是否是另一个class B的子孙(更准确地说是否符合<=的关系),需要求出B的子孙数,如果B本身的tag是3,其子孙数为3,那么如果A是B的子孙的话,tag需要处于[3, 6]中.
因此如果class A的tag为a,class B的tag是b,A <= B 的充要条件是 b <= a <= b+ descendant_cnt(B).
6) 其他表达式
其他表达式相对而言比较简单,比如说plus,sub等这种二元运算,需要先通过Object.copy拷贝一个对象作为最终要返回的结果.
void plus_class::code(ostream &s) {
// s << "# coding plus class\n";
e1->code(s); // 返回到a0的结果是一个表示Intconst的label,也就是lebal
emit_push(ACC, s); // 其结果是Int对象的地址
e2->code(s);
emit_jal("Object.copy", s); //由于Int是基于对象进行计算的,所以不能单纯地计算,还需要创建出一个对象
// 最后的返回值也应该是一个对象
emit_load(T1, 1, SP, s); // 此时T1保存的是expr1产生的Int的地址
emit_load(T2, ATTR_BASE_OFFSET, T1, s); // 获取Int1中的具体的value
emit_load(T3, ATTR_BASE_OFFSET, ACC, s); // 获取Int2中的具体的value
emit_addiu(SP, SP, 4, s); // 将SP恢复
// 此时的ACC仍然是复制出来的Int3
emit_add(T3, T2, T3, s);
// 将T3的结果加载到ACC地址对应的Int3中
emit_store(T3, ATTR_BASE_OFFSET, ACC, s);
}首先对生成e1的代码,并将其地址push到栈中,随后再对e2生成代码,并且对其进行Object.copy.此时在heap上创建了一个新的对象,它将会作为最终的返回值,但是此时和e2的对象是相等的.之后获取e1和e2的值,分别载入到T2和T3中,将其相加的结果赋值给copy出来的对象(其中的value).由于之前通过语义分析,所以plus的e1和e2一定是Int类型的.