LLVM学习记录
这篇博客,整理了一些我在学习LLVM或者写相关的代码时所学习过的基础知识, 很多部分参考了LLVM的官方文档等.
1. LLVM相关工具链
1) 工具链简要介绍

总体来说, 在编译阶段, LLVM中会涉及到以下这些数据结构的形式:
(1)将源代码转换为IR之前会处理成AST,
即TranslationUnitDecl.(2) IR转化为目标语言之前,
先生成DAG用于指令选择(SelectionDAG).然后转换为三地址形式(MachineFunction)用于指令选择.(3)
为了实现汇编器和链接器, 使用第四种数据结构(MCModule).
源代码在编译期间会涉及到一些中间数据结构的生成, 比如说AST, IR, DAG等等, 这些也正是编译的不同阶段的生成物, 这些数据结构既可以指在运行时保存在内存中, 也可以存储于磁盘(文件)之中. 对于前者的处理方式, 是通过clang以一个总管程序, 其下管理着编译各阶段的工作模块,编译中间所生成的数据结构可以在内存中在不同的模块之间传递. 如果想要通过文件的方式进行处理, 可以直接使用独立出来模块工具输出于磁盘.
关于上面提到的独立工具, 最重要的是opt和llc, 前者通过llvm中的libLLVMipa, 后者通过libLLVMCodeGen实现. 我们应当将LLVM理解为一个实现了各种编译器框架的库, 其他工具都是基于库中的某些子集实现的.
接下来对这些独立的工具进行简要的介绍:
- opt, 输入是IR,用于对IR进行优化,输出也是IR.
- llvm-as, 将可读的IR文件(.ll)转化为llvm bitcode形式(.bc).
- llvm-dis, 是前者的逆向工具, 将llvm bitcode(.bc)转化成IR(.ll).
- llc, 通过特定后端将LLVM位码转换成目标汇编语言或者目标语言.
- llvm-link, bitcode文件的链接器.
总体来说, 一个完整的编译过程如下所示:
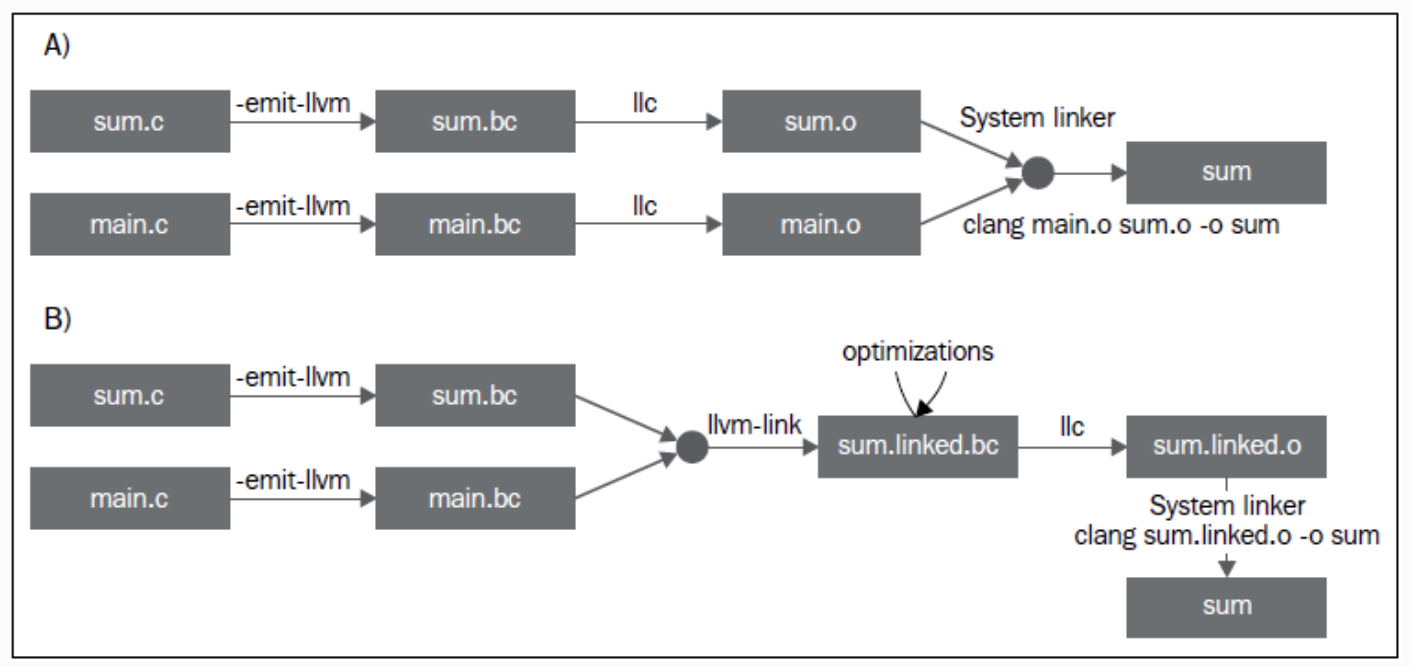
2. LLVM IR
为什么要设计IR? 正所谓“软件工程中任何问题都可以通过增加一层来解决”.增加了一层IR, 可以使得后续的程序优化都基于IR来完成, 并且设计了IR之后, 当需要涉及新的编程语言时, 不再需要专门为其设计后端部分, 只要遵循一定的IR规范, 只设计好前端部分就可以.这大大增强了模块的可复用性.
IR从形式上来看, 就像是汇编语言的伪代码.其中在llvm中其编译模式如下:
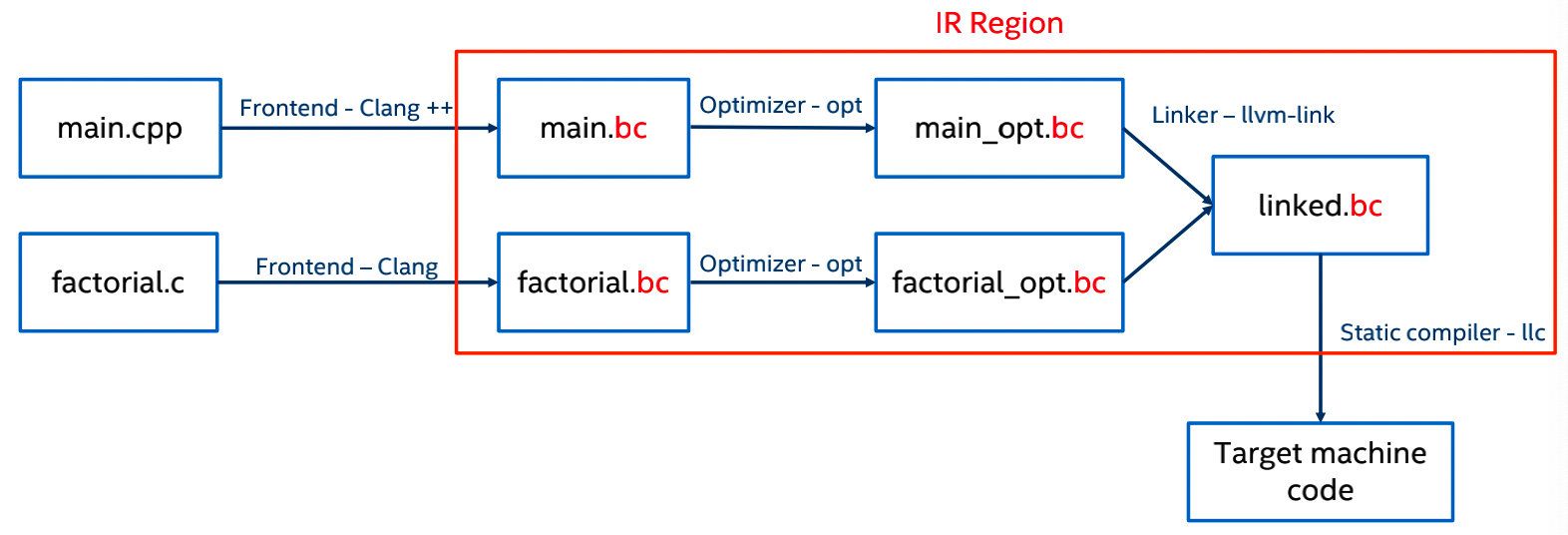
llvm规范的IR模式下, 其所构建的数据结构如下:
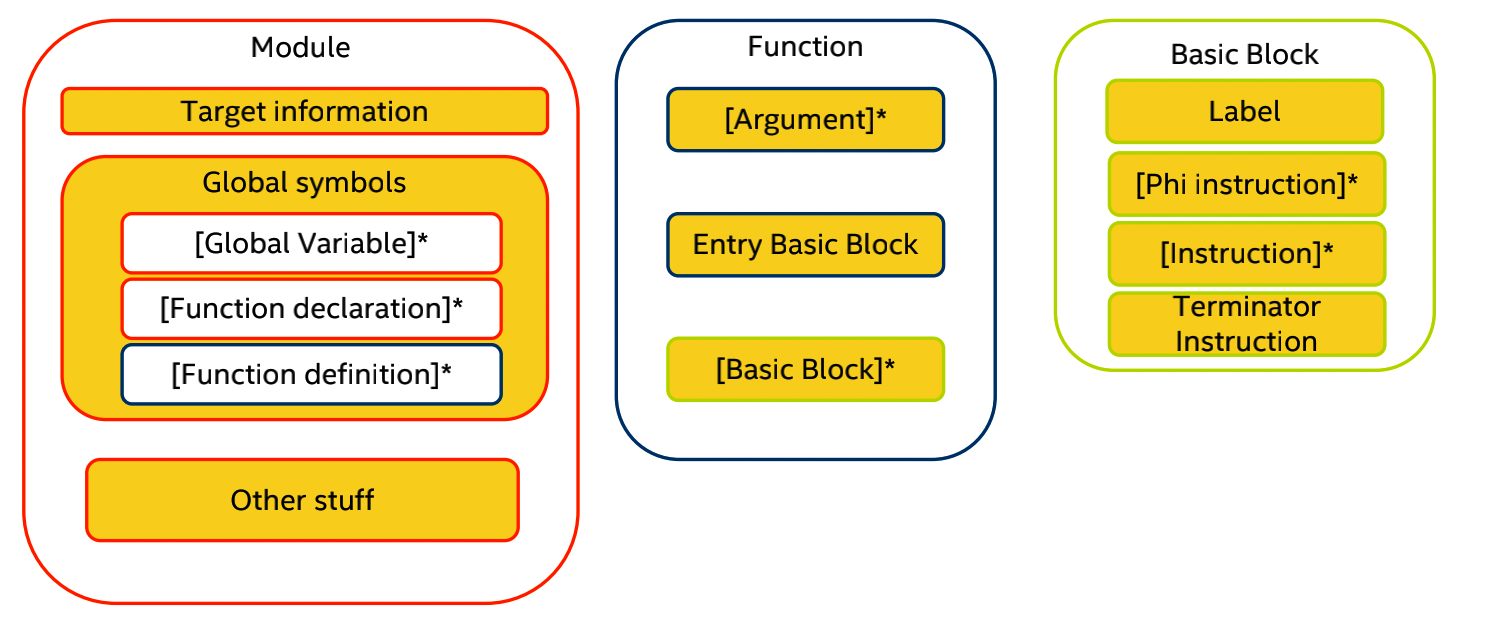
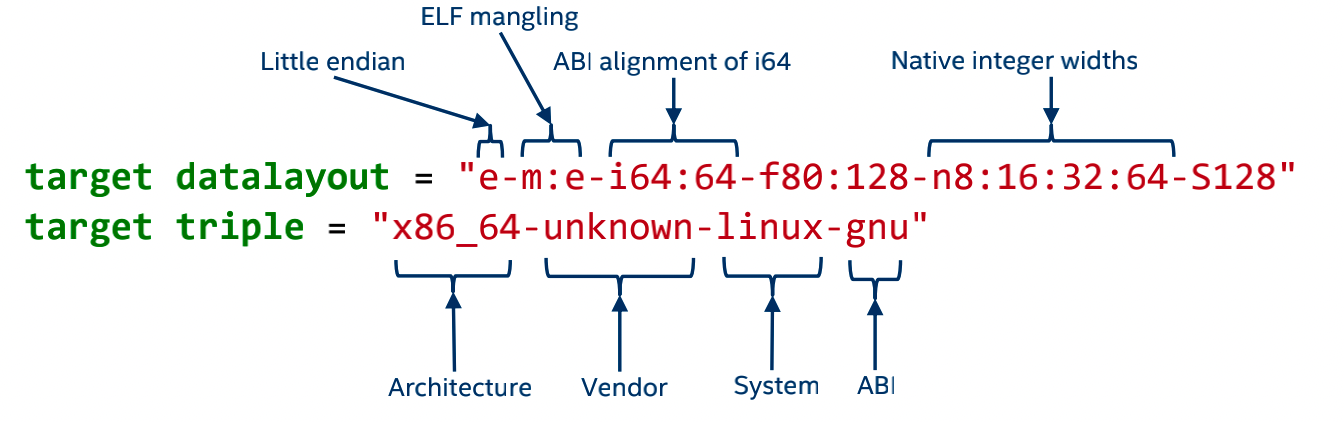
其中关于Target information主要由两部分组成:
下面是一个简单的程序片段及其翻译成IR代码的形式:

其中关于寄存器, 有unamed和named之分, 其中即使是像result这样已经命名的“寄存器” 到后面转化成目标代码时也需要进行转化.在LLVM IR中假定寄存器在使用上是无限的.
在IR代码中, Type也是一个重要的概念, 比如说上面的i32.这通常作为指令语句中的操作数.对于生成指令所需要格式, 应当参考LLVM Language Reference完成.
接下来给定一个更加复杂的例子:

其中关于基本块的概念, 上面代码中可以划分出3个基本块.根据基本块可以得出CFG如下:
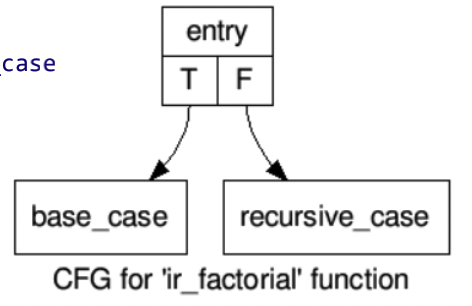
接下来是一个迭代累乘的例子:
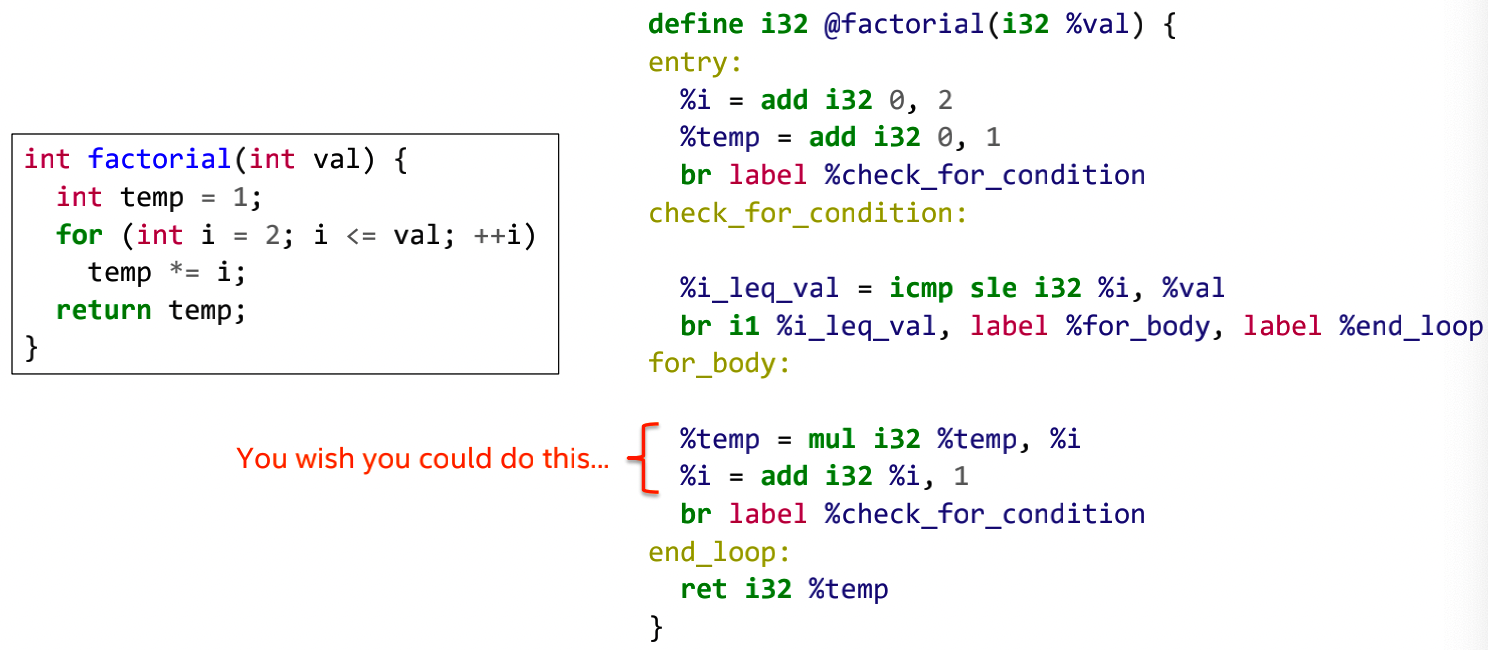
在上面的这份代码中, 会出现“multiple definition of local value named
‘temp’”的错误,
因而引出SSA的问题.因此对temp重新命名为new_temp,
其后面的i修改为i_plus_one.在SSA中对于出现分支的情况,
需要用Phi来表示这种不确定的变量.SSA在LLVM的IR中是贯彻始终的.
下面是一种采用了SSA的形式:

关于全局变量, 其前缀为@.
Type System And Geps
首先看数组类型:
@array = global [17 x ]
@array = global [17 x i8]
@array = global [17 x i8] zeroinitialzerGEP指令指的是Get Element Pointer指令.其中语法表示如下:
<result> = getelementptr <ty>, <ty>* <ptrval>, [i32 <idx>]+可以通过某一个base的指针, 根据一定的偏移量获取新的指针.

关于struct相关的语法, 其形式是一个"type + {}"的形式.比如说:
%MyStruct = type { i8, i32, [3 x i32]}补充
一个.ll文件所对应的内容对应了内存中抽象成的Module.该数据结构可以视为一个程序的顶层数据结构.除了包含了一些函数(内部由基本块和指令构成),还包含了一系列外围对象, 比如全局变量、目标数据布局等等.总之在理解Module的结构和作用时, 应当结合.ll文件的内容去理解.
总体上, 总结LLVM IR语法的核心特点:
- 使用SSA.这使得我们编写代码访问一个被引用的变量时可以直接获取其唯一的定义(Instruction).进而生成use-def链变得简单, use-def将会用于常量传播和冗余表达式消除等优化.SSA的使用避免了再需要通过数据流分析构造use-def链.
- 形式上,采用了三地址形式.就像是汇编语言的伪代码一样.
- 变量体现为无限数量的虚拟寄存器.
关于目标数据布局(target layout):
target datalayout = "e-p:64:64:64-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:64:64-f32:32:32-f64:64:64-v64:64:64-v128:128:128-a0:0:64-s0:64:64-f80:128:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.7.0"这一部分的信息所对应的数据结构是IR/DataLayout等数据结构.
3. LLVM Programmer’s Manual
简要的记录一下阅读Manual时比较重要和基础的东西, 如果这个不好好读一读的话, 些LLVM Pass完全就无从下手.
关于RTTI.首先是关于isa<>, cast<>, dyn_cast<>等.
isa就像Java中的instanceof返回值时bool类型,用来判断某个对象(指针或者引用)是否是某个特定class类型的.
cast<>用来将基类指针(或者引用)转化成派生类.dyn_cast<>则类似于dynamic_case<>.
关于strings.主要是StringRef,可以通过.str获取其std::string对象.formatv与格式化字符串有关, 其使用方式类似于printf, 但是关于类型没有严格限制, 也不需要必须标明类型.其中相关的例子如下:
// Left, right, and center alignment
S = formatv("{0,7}", 'a'); // S == " a";
S = formatv("{0,-7}", 'a'); // S == "a ";
S = formatv("{0,=7}", 'a'); // S == " a ";
S = formatv("{0,+7}", 'a'); // S == " a";
// Custom styles
S = formatv("{0:N} - {0:x} - {1:E}", 12345, 123908342); // S == "12,345 - 0x3039 - 1.24E8"
// Adapters
S = formatv("{0}", fmt_align(42, AlignStyle::Center, 7)); // S == " 42 "
S = formatv("{0}", fmt_repeat("hi", 3)); // S == "hihihi"
S = formatv("{0}", fmt_pad("hi", 2, 6)); // S == " hi "
关于lambda.function_ref相当于C++标准中的std::function.使用起来几乎也是一模一样.
关于数据结构.
先写几个感觉容易用到的.ArrayRef是定长数组, 使用起来和数组几乎一样,
当API参数类型为ArrayRef时, 可以通过std::vector, 普通定长数组,
llvm::SmallVector来传递.返回值应该也是同样的道理.SmallSet使用起来类似于std::set.关于Map的有StringMap,IndexedMap等等.
1) Helpful Hints for Common Operations
下面是一些遍历操作:
// 遍历function中的BasicBlock
Function &Func = ...
for (BasicBlock &BB : Func)
errs() << "Basic block (name=" << BB.getName() << ") has "
<< BB.size() << " instructions.\n";
// 遍历BasicBlock中的Instructions
BasicBlock& BB = ...
for (Instruction &I : BB)
errs() << I << "\n";
// 直接通过Function遍历Instructions
std::set<Instruction*> worklist;
// or better yet, SmallPtrSet<Instruction*, 64> worklist;
for (inst_iterator I = inst_begin(F), E = inst_end(F); I != E; ++I)
worklist.insert(&*I);
// 遍历Blocks中的predecessors或者successors
#include "llvm/IR/CFG.h"
BasicBlock *BB = ...;
for (BasicBlock *Pred : predecessors(BB)) {
// ...
}下面是一些修改相关的操作:
// 创建Instruction
auto *ai = new AllocaInst(Type::Int32Ty);
auto *pa = new AllocaInst(Type::Int32Ty, 0, "indexLoc");
// Insert Instruction
// Deleting Instructions2) The Core LLVM Class Hierarchy Reference
这一部分主要接收IR在内存中所采用的数据结构表示.
总体的继承体系如(不考虑list node):
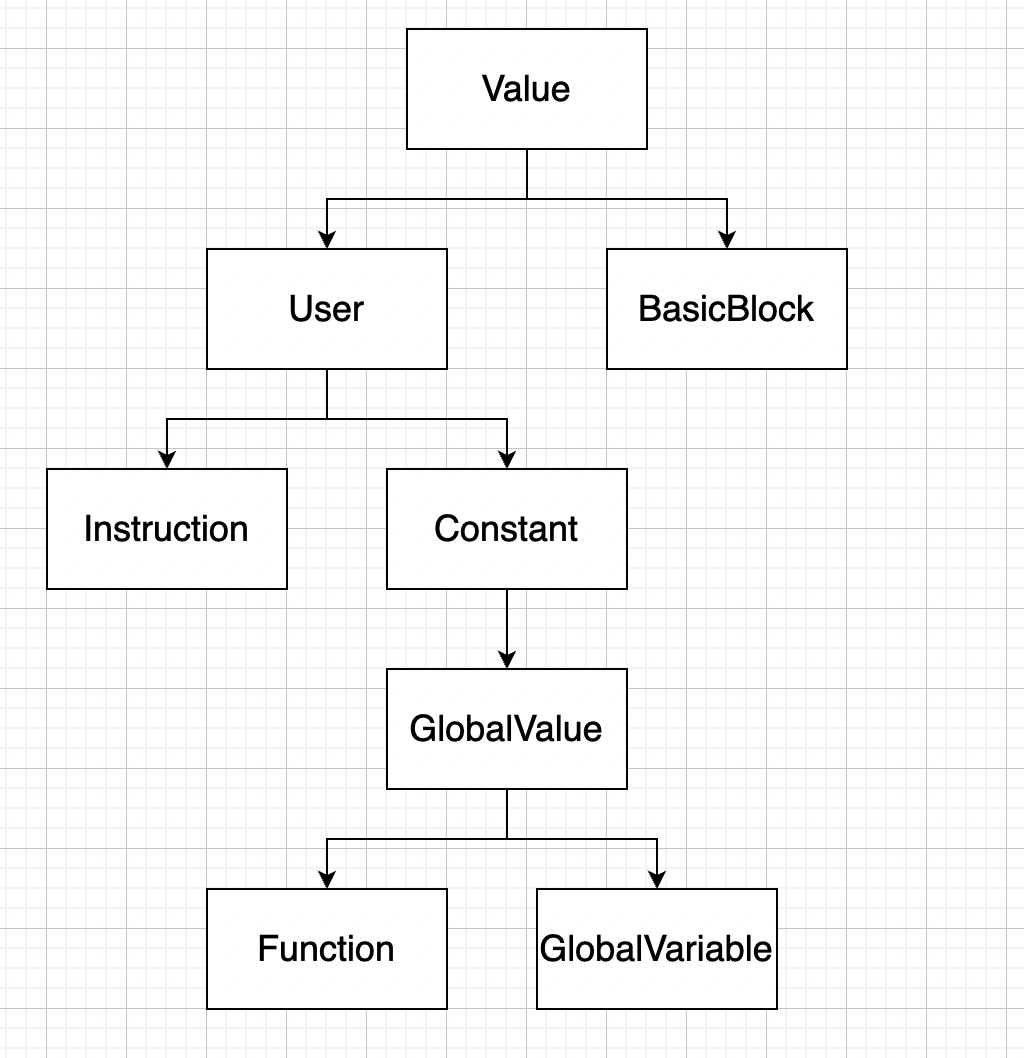
这一部分涉及到的东西还挺多的.
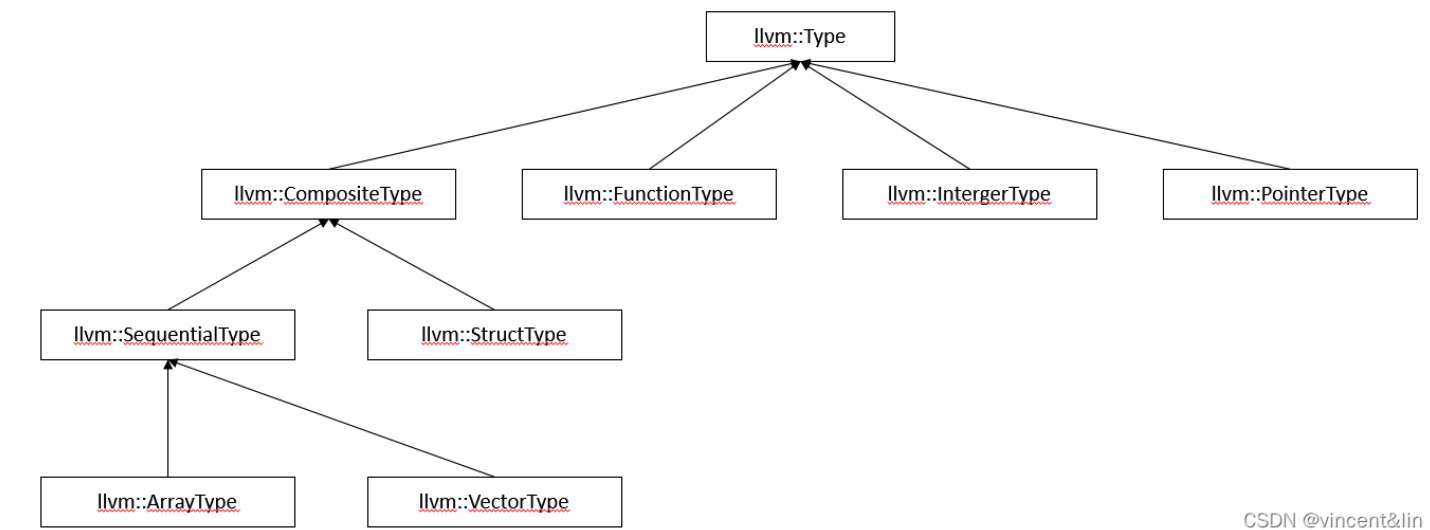
Type.在llvm IR中, 其中涉及的变量是有类型之分的.
Value.正如同linux系统中的一切皆文件, llvm中也有一个重要的概念, 也就是一切皆Value, 后面会提到的Module、User、Instruction等class都是从class中派生出来的.狭义的Value表示指令中有类型的值.每一个Value都有一个type,并且可以通过getType从中获取.其中开放的接口有:Users相关的迭代器、number, 还有getType, hasName, getName等等.尤其是replaceAllUsesWith可以用来设置其中的Users.
Module,可以看作是对于一个程序的抽象.其中的数据成员有一系列Function、GlobalVariable、SymbolTable, 并且对于这些对象都提供对外访问的接口.
Instruction,用来描述一条具体的指令. 其中包含了指令类型、操作数.其中提供的方法有getOpcode用来返回指令类型, 通过User::getOperand或者User::setOperand()用来获取/修改下标的指令的操作数.关于这些Operand, 其类型都是Value的.由于Instruction除了继承User之外还继承了一个表示list node class的类用于适配与list, 还有getParent用来返回其所处的基本块等.
Constant,表示的是所有常量的基类.
Function, 继承自GlobalObject, 表示的是一个全局的独立对象.其中使用Argument class来表示函数的形参.其中的数据成员有几个BasicBlock,Argument,还有一个SymbolTable.其中的符号表用来对某个变量进行lookup.尤其是在处理函数内部的变量时, 有时需要区分时形参还是局部变量等等.
BasicBlock, 维护了a list of Instructions.一定归属于某个Function之中.在访问时, 除了可以获取其中的指令, 还可以结合CFG来进行访问, 比如说通过getSinglePredecessor访问前一个基本块.
体会Value和User设计的巧妙之处
4. The LLVM Target-Independent Code Generator
1) Target description classes
这一部分主要由一系列的Info构成.
2) Machine code description classes
5. LLVM后端
其中一些关于指令选择和指令调度的部分, 我没怎么学过, 所以这方面只从宏观的层面写一下.
1) 总体架构
和IR Pass一样, 这一部分也是由一些分析Pass和变换Pass所组成.
这其中涉及到主要阶段如下:
- 指令选择,
将IR转化成指定目标的
SelectionDAG结点, 根据IR生成一个有向无环图(DAG)的形式.当此阶段结束为止, DAG中的所有LLVM IR结点都会转化为目标机器结点, 也就是机器指令而非LLVM IR指令. - 指令调度.DAG更多时候只能表达一种依赖图关系, 无法通过DAG直接得到指令序列, 因此需要结合原本的IR, 在生成对应的目标指令序列.
- 寄存器分配, 之前的的寄存器形式都是虚拟寄存器, 这里分配成实际的物理寄存器, 由于目标机器的寄存器集合是有限的, 所以对于某些虚拟变量是需要溢出的.
经过以上阶段后, 最终输出目标代码.