LLVM IR Pass Labs
关于这个小项目, 我发现不少搞安全的大佬在学习编译原理都做过, 虽然我和他们想要走的学习路线并不一样, 学编译原理也没有想着去搞fuzz挖漏洞(毕竟我不太想做安全),但我认为他们确实提供了一个扎实又系统的编译原理学习路线, 我只是想满足自己写编译器的小小梦想, 并且编译这条技能树打通后, 也可以考虑和数据库内核相结合, 比如说查询引擎优化等等,或者读研乃至工作,编译都是一个值得考虑的路子. 总之, 我认为编译这一块还是很值得深入一学的.
0 .环境准备
这个项目的运行环境是基于docker构建的, 其中给出的文档中的命令如下:
$ cd Assignment1-Introduction_to_LLVM/FunctionInfo
$ docker run -it -v $(pwd):/mnt --rm --name cscd70_a1 cscd70:2021S但是我认为这样用起来不是太顺手, 因此我并不想关掉容器后,就将容器删除, 因此我没有加“--rm”,此外,我希望在后来写代码的时候通过vscode对容器ssh, 因此必须要设置容器的端口映射,并且配置容器内的ssh服务.在这里也简单地记录一下配置的过程吧.
相比前面的那个run命令,我做了点调整.
$ docker run -dit -p 14010:22 -v $(pwd):/mnt --name cscd70_a1 cscd70:2021S在容器中设置密码、更新源、安装openssh-server、修改ssh配置文件、重启ssh服务, 一套下来轻车熟路就可以了.
$ passwd
$ apt-get -y install openssh-server
$ vi /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
PermitRootLogin yes
$ /etc/init.d/ssh restart之后就可以使用vscode ssh容器来进行写代码了.
1. Introduction to LLVM
1) 输出函数信息
这一部分的实现相当简单.如下所示:
virtual bool runOnModule(Module &M) override {
outs() << "CSCD70 Function Information Pass"
<< "\n";
for (auto &func : M) {
showFuncInfo(func);
}
return false;
}
}; // class FunctionInfo
void FunctionInfo::showFuncInfo(const Function &func) {
outs() << "#Name:" << func.getName() << "\nArgs:" << func.arg_size() << "\nCalls:"
<< func.getNumUses() << "\nBlocks:" << func.size() << "\nInsts:"
<< func.getInstructionCount() << "\n";
}直接在Module中遍历函数就可以了, 对于所访问的函数, Function都提供了一些接口访问内部信息.
2) 局部优化实现
这一部分区分了三个不同的子任务, 但实现起来都是差不多的.
这里以MultiInstOpt为例简要分析一下:
virtual bool runOnFunction(Function &F) override {
std::list<Instruction*> delete_list;
for (auto &bb : F) {
for (auto &curr_ins : bb) {
if (curr_ins.isBinaryOp() && curr_ins.getOpcode() == Instruction::Sub) {
int curr_other_idx;
auto curr_const_int = getConstIntOperand(curr_ins, &curr_other_idx);
if (curr_const_int == nullptr) {
continue;
}
auto other_ins = dyn_cast<Instruction>(curr_ins.getOperand(curr_other_idx));
if (other_ins == nullptr) {
continue;
}
if (!other_ins->isBinaryOp() || other_ins->getOpcode() != Instruction::Add) {
continue;
}
int pre_other_idx;
auto pre_const_int = getConstIntOperand(*other_ins, &pre_other_idx);
if (pre_const_int == nullptr) {
continue;
}
// 然后判断常数部分的值是否相等
if (pre_const_int->getSExtValue() == curr_const_int->getSExtValue()) { // 可以被优化
curr_ins.replaceAllUsesWith(curr_ins.getOperand(curr_other_idx));
delete_list.push_back(&curr_ins);
}
}
}
}
for (auto delete_ins : delete_list) {
delete_ins->eraseFromParent();
}
return false;
}这一部分提供了以函数为单位的局部优化, 在每个函数内部可以通过遍历BasicBlock的方式遍历每一个指令. 根据Assignment的要求, 需要访问其中的操作数. 然而操作数是有区别的, 有可能是别的指令所定义的变量, 有可能是函数形参, 也有可能是常量. 如何知道究竟是哪一种类型呢? 以上三者分别对应了Instruction、Argument、Constant等等,可以通过lllvm中所提供的isa来判断(也可以用dyn_cast).在这里区分开Instruction和Constant就好了.
对于其中Constant,
可以通过getSExtValue或者getZExtValue分别以signed和unsigned的方式返回int.
其中需要涉及到指令删除, 这里对于指令删除采用了一种延迟的技巧, 首先将其加入到一个list中, 最后再逐个删除, 因为如果在遍历时删除,会对遍历迭代器产生影响.
还有一个地方需要注意, 这其中涉及到对于def-use链的调整.我们需要删除一个Instruction, 也就意味着删除了该Instruction所对应的变量, 因此对于其他引用过该变量的地方应该进行替换.
𝑎 = 𝑏 + 1, 𝑐 = 𝑎-1 ⇒ 𝑎 = 𝑏+1, 𝑐 = 𝑏这里给出来的样子像是替换指令, 我最初的想法是“先删除再创建”,
但这实际上走了弯路,
只要将“c=a-1”删除,而引用过c的地方都换成b就好了.这里需要使用到replaceAllUsesWith,
其中的参数就对应了b.
这里真的可以体会到SSA的优越性, 如果没有SSA, 引用的变量就无法直接获取其对应的def指令. SSA可以使得每个use和def都能一一对应.
2. Dataflow Analysis
这一部分的实现需要对常用的数据流分析算法的模版有所理解:
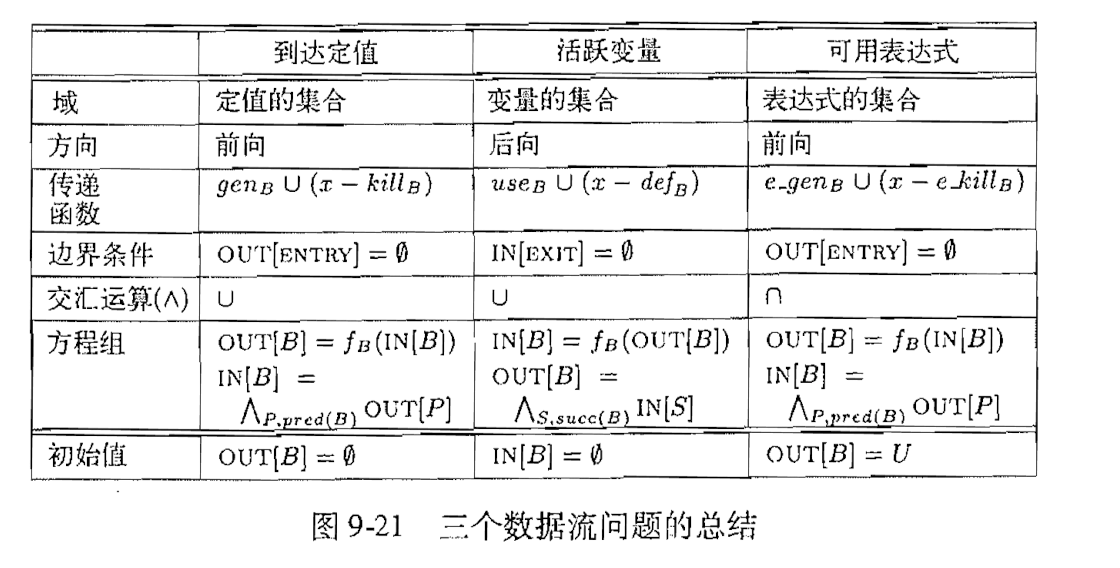
1) Framework的可变因素与模版参数
活跃变量分析和可用表达式分析都是一种迭代算法. 其中差别也主要在于上面所设计的一些数据结构.下面就从这些数据结构的角度去理解实现这个framework的关键要素.

首先, 这其中需要将不同类型的数据结构或参数带入到该Framework中, 因此Framework也就很自然地设计成了一个模版类.其中的参数也正合表格所提到的因素有关.下面所列举的这些因素都对应了Framework中的模版参数:
“域”这一部分, 分别是变量也可以是表达式. 我最初认为这两者都可以用Instruction来表示, 就不再需要额外的封装了, 但其实不然, 关于变量还需要包括Argument, 也就是函数参数.因此在实验中需要分别对两者进行封装, 也就是Variable和Expression
“方向“.遍历的方向所影响的是在这个FunctionPass中所需要遍历指令的顺序不同, 因此可以考虑不同的”方向“ 返回不同方式的迭代器. 之后遍历处理的部分就可以共用同一种代码实现了.所以在具体实现中, 需要编写代码来返回不同种类的迭代器(逆向或者正向).
”交汇方向“, 也就是方程组求解过程中所涉及的运算.对应MeetOp中关于Intersect和Union的实现.
其他因素都可以使用相同的代码处理, 无需作为“可变因素”,在后面详细分析.
在Framework类中其模版参数如下:
template <typename TDomainElem, typename TDomainElemRepr, Direction TDirection,
typename TMeetOp> //
class FrameworkTDomainElem对应的正是域, 要么是Expression,
要么是Variable.第二个参数在这两者分析中都是bool类型,
表示的是一个Expression/Variable是否可用/活跃.第三个参数是一个枚举类(分为向前和向后),
表示的是传递方向.第四个参数代表了交汇运算符.
2) Framework中的核心数据结构
protected:
// Domahein
std::vector<TDomainElem> Domain; // Domain是一个表达式的集合
// Instruction-Domain Value Mapping
std::unordered_map<const Instruction *, DomainVal_t> InstDomainValMap; // 这个map表示的是某个指令bitmap
std::unordered_map<const Value *, unsigned> InstIndexMap;前者是收集的该Function中所有域的集合.InstDomainValMap是每个Instruction对应的bitmap,
在正向迭代中, 该bitmap是每个表达式的OUT集合, 如果是反向的,
则是IN集合.InstIndexMap是我加上了,
用来记录每个Domain在Bitmap中的索引,
无论是Variable还是Exprssion(我在Expression中增加了该表达式所对应的Value指针为数据成员)都对应了一个Value,
利用多态的特性可以统一用Value指针来表示.
3) 迭代算法实现
bool runOnFunction(const Function &F) {
// initialize the domain
initializeDomain(F); // 首先对Domain进行初始化
// apply the initial conditions
TMeetOp MeetOp;
for (const auto &Inst : instructions(F)) {
InstDomainValMap.emplace(&Inst, MeetOp.top(Domain.size())); // 此时该map每个key对应一个Instruction, 其中的集合为全false
}
while (traverseCFG(F)) { // 遍历cfg, 也就对应了算法核心迭代部分
}
printInstDomainValMap(F); // 打印出来结果
return false;
}其中迭代算法的总体代码流程如上所示.initializeDomain通过遍历每个Instruction来收集Domain.这一部分对于Liveness和AvailExpr有不同的实现方式.然后是定义MeetOp,
初始化每一个表达式的Bitmap集合, 在后面的实现中,
都是将其输出化为全0的集合.之后while(traverseCFG(F))迭代.最终输出结果.
void initializeDomain(const Function &F) {
for (const auto &Inst : instructions(F)) { // 根据函数中的每一个指令来对Domain进行初始化
initializeDomainFromInst(Inst); // 每个指令都有use和def集合
}
}上面的initializeDomaininFromInst是一个纯虚函数,
在AvailExpr和Liveness中有不同方式的实现:
virtual void initializeDomainFromInst(const Instruction &Inst) override { // AvailExpr
if (const BinaryOperator *const BinaryOp =
dyn_cast<BinaryOperator>(&Inst)) {
InstIndexMap[&Inst] = Domain.size();
Domain.emplace_back(*BinaryOp);
}
}
virtual void initializeDomainFromInst(const Instruction &Inst) override { // Liveness
for (auto op_it = Inst.op_begin(); op_it != Inst.op_end(); ++op_it) {
auto operand = op_it->get();
if (dyn_cast<Argument>(operand) || dyn_cast<Instruction>(operand)) {
auto findit = InstIndexMap.find(operand);
if (findit == InstIndexMap.end()) {
InstIndexMap[operand] = Domain.size();
Domain.emplace_back(Variable(operand));
}
}
}
}Expression这个概念在LLVM中更加准确地说对应的是BinaryOperator这一概念, 如果当前遍历的Instruction符合该类型就将其加入同时记录其Index.在Liveness中,通过检查操作数的方式进行收集, 其中需要Argument和Instruction(前者容易遗漏). 我最初在实现时, 考虑的不是遍历操作数, 而是直接遍历Instruction本身,也就是def. 但这实际上会造成对Argument的遗漏.
其中迭代算法的核心, 也就是迭代算法的核心部分, 这一部分根据各种教科书中给出的伪代码就很容易实现:
bool traverseCFG(const Function &F) {
bool has_changed = false; // 用来表示是否有block发生了变化
DomainVal_t ibv;
for (auto &bb : getBBTraversalOrder(F)) { // 这里用的基本块是forward的顺序
ibv = getBoundaryVal(bb); // 首先获取所有前驱结点meet起来的结果
bool is_changed = false; // 用来表示该block是否发生了变化
for (auto &ins : getInstTraversalOrder(bb)) {
is_changed = transferFunc(ins, ibv, InstDomainValMap[&ins]);
ibv = InstDomainValMap[&ins];// 设置好下一个Instruction需要的入口集合(有可能是in也可能是out)
}
// 此时的ibv在Liveness中是该block的in,在AvialExpr中是block中的out,change也就是表示的该
// out或者in是否发生变化
has_changed |= is_changed;
}
return has_changed;
} 参考:

简而言之, 每次迭代都以基本块为单位, 首先需要获取的是out[p]集合,
通过getBBTraversalOrder即可获取,
并设置为当前遍历块的in集合, 之后如果想要实现“oldout = out[i]”,
则需要将此BasicBlock的指令从头到尾迭代一遍,
对其调用transferFunc.当循环退出后,
is_changed表示的就是该BasicBlock的out是否发生变化.最终要返回的has_changed表示的则是这整一轮迭代是否出现变化.
关于transferFunc.有趣的是,在不同迭代方向下,IV和OV的意义有所不同,当为Forward时,IV对应的正是in集合,OV则是所要求的out;如果是backend方向,IV对应的则是out,OV是in集合.“OV”是需要通过“IV“进行更新的,其返回值表示OV有没有发生改变.也就对应了前面的is_changed的设置.
virtual bool transferFunc(const Instruction &Inst, const DomainVal_t &IV,
DomainVal_t &OV) = 0;关于其中的传递函数, 两者的实现有所区别:
bool Liveness::transferFunc(const Instruction &Inst, const DomainVal_t &IBV, DomainVal_t &OBV) {
DomainVal_t OLD_OBV = OBV;
OBV = IBV;
// 将该Inst def的部分去除掉
auto find_def_it = InstIndexMap.find(&Inst);
if (find_def_it != InstIndexMap.end()) { // 表示该指令存在一个def
OBV[find_def_it->second] = false;
}
// 将use的部分合并上
for (auto op_it = Inst.op_begin(); op_it != Inst.op_end(); ++op_it) {
auto operand = op_it->get();
if (dyn_cast<Argument>(operand) || dyn_cast<Instruction>(operand)) {
auto findit = InstIndexMap.find(operand);
if (findit != InstIndexMap.end()) { // 如果该def之前是存在的话
OBV[findit->second] = true;
}
}
}
// 比较是否发生了更新
for (size_t i = 0; i < IBV.size(); ++i) {
if (OBV[i] != OLD_OBV[i]) {
return true;
}
}
return false;
}上面是活跃变量部分的实现,首先需要保存OLD_OBV, 然后设置新的OBV, 新的OBV就是IN集合去掉def并上use.对于def的处理很简单,Inst本身就是def.至于use还是通过访问operand的方法,通过dyn_cast判断是否为Argument或者Instruction类型.最后比较是否有chenged.
3. Loop Invariant Code Motion
感觉到了Assignment3这一部分难度明显上来了呢.尤其是寄存器分配是新加的部分,我尝试着去实现,但是失败了😭.
1) 循环不变量计算
关于循环不变量相关的代码消除,其核心算法有两个关键:
- 如何判断循环不变量?循环不变量涉及到的都是由BinaryOperator定义的,因此取决于其Operand.该Operand应满足一下条件:(1)是Constant;(2)已经确定为循环不变量;(3)改变量的定义不处于该Loop,并且处于外部.当所有Operand都符合三个条件之一时,此表达式就是一个循环不变量.
- 什么样的循环不变量可以外提?该循环不变量所对应的表达式(Instruction)同时为所有exit block的支配结点.
此算法仍然是一个迭代算法, 迭代算法会在每一次迭代更新一个循环不变量的集合,当循环不变量的集合和上一轮没有发生变化时,迭代结束.
关于迭代算法的简单思考
前面的活跃分析、可用表达式以及这里的循环不变量计算都用到了迭代算法.也很显然它们有共同之处,即更新时需要根据一些不变信息(比如活跃分析中的def和use集合,循环不变量计算中关于Constant和是否处于外部循环的判断),也需要根据一些变化的信息(也就是每一次迭代要更新的信息,比如说活跃分析中的OUT集合,循环不变量计算中的不变量集合),一旦这些变化的信息没有发生改变,接下来迭代中的所有信息也就都成了“不变信息”,因此接下来无论进行多少迭代,其结果都不会发生改变,因此可以判定为迭代结束.
依赖设置
关于Loop有关的优化, 需要了解一些与循环相关的信息,以及控制流图中的循环信息(比如说循环中的支配结点等).而这些信息都不是LLVM库直接提供的,而是经过前面的数据流分析所获得的,所以需要增加依赖,表示这一部分Pass需要借用之前的一些分析结果来进行处理.
virtual void getAnalysisUsage(AnalysisUsage &AU) const override {
/**
* @todo(cscd70) Request the dominator tree and the loop simplify pass.
*/
AU.addRequired<DominatorTreeWrapperPass>(); // 用于检查某个Instruction是否是支配结点
AU.addRequired<LoopInfoWrapperPass>();
AU.setPreservesCFG(); // 保留之前所求出的数据流图的结果.
}getAnalysisUsage也是很多Pass需要override的方法.因此设置好了分析依赖之后,
就可以获取相关的数据结构,进而在后续阶段读取使用:
if (loopInfo == nullptr) {
loopInfo = &(getAnalysis<LoopInfoWrapperPass>().getLoopInfo());
}
if (dominatorTree == nullptr) {
dominatorTree = &(getAnalysis<DominatorTreeWrapperPass>().getDomTree());
}其中,loopInfo和dominatorTree都是该Pass中的数据成员.
核心数据结构
const LoopInfo *loopInfo;
const DominatorTree *dominatorTree;
std::unordered_set<Instruction*> InvariantSet; // 所收集的循环不变量的集合前两者之前有所介绍,InvariantSet则用来保存在迭代时所确定的循环不变量.用于在后续迭代中查询变量是否为循环不变量.
核心实现
核心实现也就是迭代算法收集不变量的实现.在runOnLoop中只对应了一行:
while (traversalLoop(L)) {}traversalLoop的返回值表示的是这一轮迭代有没有发生改变.关于runOnLoop(优化的粒度是一个Loop).runOnLoop的全部实现如下:
virtual bool runOnLoop(Loop *L, LPPassManager &LPM) override {
if (L->getLoopPreheader() == nullptr) {
return false;
}
InvariantSet.clear();
if (loopInfo == nullptr) {
loopInfo = &(getAnalysis<LoopInfoWrapperPass>().getLoopInfo());
}
if (dominatorTree == nullptr) {
dominatorTree = &(getAnalysis<DominatorTreeWrapperPass>().getDomTree());
}
// 首先需要从中找出循环不变量,通过遍历Instruction来确定, 收集到一个list中
while (traversalLoop(L)) {
}
for (auto Invariant : InvariantSet) { // 将对应的指令移动到Preheader中
// 需要判断的是是否是exit的支配结点
if (checkIsExitsDom(L, Invariant)) {
moveInvariant(L, Invariant);
}
}
// 接下来根据所收集的指令判断是否可以并进行移动
return false;
}首先需要判断当前Loop是否有Preheader,然而什么样的Loop是没有Preheader的呢?LLVM中注释解释道:
If there is a preheader for this loop, return it. A loop has a preheader if there is only one edge to the header of the loop from outside of the loop. If this is the case, the block branching to the header of the loop is the preheader node. This method returns null if there is no preheader for the loop.
也就是说循环外部结点到达header只有一个边的情况下,才是有Preheader的情况.
之后对于InvariantSet的初始化,我最初也在纠结,这个集合应该作用于所有Loop,还是单个Loop呢?在这里是对单个Loop有效的,因此每个runOnLoop都clear,如果不clear,后面下面移动代码会导致重复移动的情况,我认为将该集合表示为所有Loop的倒也还可以,不过需要增加一个map来判断该Instruction是否已经移动,从而防止重复移动代码的情况.
接下来分析traversalLoop的实现:
bool LoopInvariantCodeMotion::traversalLoop(Loop *L) { // 每次只针对某一特定的L, 对应了runOnLoop中的L
bool is_changed = false;
for (auto BB : L->getBlocks()) {
if (loopInfo->getLoopFor(BB) != L) { // 每次只针对特定的L
continue;
}
for (auto &Inst : *BB) {
if (!isInSet(&Inst) && isInvariant(L, &Inst)) {
InvariantSet.insert(&Inst); // 加入到集合中
is_changed = true;
}
}
}
return is_changed;
}这里需要对此Loop中的所有Instruction进行遍历,不过这里的关于BasicBlock只能表示此Loop头尾之间的所有BasicBlock,而不一定处于本Loop之中(比如说可能处于内部的某个嵌套循环之中),因此对于这种情况就continue.对该指令进行遍历时首先判断之前是否已经处于Inst中,
并且通过isInvariant来做具体的判断.如果发现新的循环不变量,就加入到集合,并设置changed.
关于isInvariant的实现如下:
bool LoopInvariantCodeMotion::isInvariant(const Loop *loop, Instruction *const I) { // loop 也正是当前所处理的I所处于loop
bool IsVariable = true;
auto isOutLoop
= [&](const Instruction* inst) -> bool {
return loop->contains(inst);
};
for (auto oper_it = I->op_begin(); oper_it != I->op_end(); ++oper_it) {
bool op_is_const, op_is_inset, op_notsame_loop;
op_is_const = isa<Constant>(oper_it);
auto oper_inst = dyn_cast<Instruction>(oper_it);
if (oper_inst != nullptr) {
op_is_inset = isInSet(oper_inst);
op_notsame_loop = !isOutLoop(oper_inst);
} else {
op_is_inset = false;
op_notsame_loop = false;
}
// 判断循环所处的位置,是否位于循环外部
IsVariable &= (op_is_inset || op_is_const || op_notsame_loop);
}
return IsVariable &&
isSafeToSpeculativelyExecute(I) &&
!I->mayReadFromMemory() &&
!isa<LandingPadInst>(I);
}其核心在于对操作数的判断,结合前面所提到的符合循环不变量的条件也就不难实现这一部分的代码.其中对于是否处于外部循环的实现,采用contains完成,该方法可以用来判断某个Inst是否处于某个loop之中.
收集完这一轮的循环不变量时,需要先判断是否可以移动之后才可以进行移动.
bool LoopInvariantCodeMotion::checkIsExitsDom(const Loop *loop, const Instruction *Inst) {// 在一个控制流图中, 其Exit Block往往有好几个
SmallVector<BasicBlock*, 0> exit_blocks;
loop->getExitBlocks(exit_blocks);
for (auto exit_block : exit_blocks) {
// 检查Inst是否为该Block的支配结点
if (!dominatorTree->dominates(Inst, exit_block)) { // 如果不是支配结点
return false;
}
}
return true;
}
void LoopInvariantCodeMotion::moveInvariant(const Loop *loop, Instruction *Inst) {
auto perheader = loop->getLoopPreheader();
Inst->moveBefore(perheader->getTerminator());
}通过getExitBlocks方法可以返回该Loop的所有退出块,对于Inst应该满足的条件是:为所有exit
block的支配结点.通过dominatorTree中的dominates方法判断.在移动代码时,获取该Loop的Preheader,将该Inst移动到里面就可以.其实顺序不需要讲究,因为循环不变量对应的指令往往是没有什么依赖关系的.
2) 寄存器分配
这一部分我没写出来,网上找的大佬的代码都是旧版的,这一部分也没有.之所以困扰我一方面是因为理解寄存器分配的算法有点难,另一方面是因为这其中涉及到很多LLVM的数据结构我没有整明白,而且接下来的学习任务有些紧张,所以尝试写了写之后就先搁浅了,我是真的废物.
之前的Pass都是基于IR处理,而寄存器分配的Pass处于一个不同的阶段,这一部分位于指令选择与指令调度之后,此时该Pass所接受的形式不再是IR,而是MachineFunction,可以说已经接近目标汇编语言,但只是没有将其中的虚拟寄存器转化为物理寄存器.因此这里所需要使用的LLVM中的API和数据结构和前面的Pass都不太一样.
不过LLVM中有提供的几种寄存器分配的实现,我想以后有时间再学一学吧.
example中的简单实现
CSCD70的example中给出了一个简单的寄存器实现.像之前的Pass一样,这里也是一个class,继承了MachineFunctionPass和LiveRangeEdit::Delegate.正如之前所写的Pass一样,首先需要说明的是该Pass所需要的依赖,其中涉及的代码如下:
INITIALIZE_PASS_DEPENDENCY(SlotIndexes)
INITIALIZE_PASS_DEPENDENCY(VirtRegMap)
INITIALIZE_PASS_DEPENDENCY(LiveIntervals)
INITIALIZE_PASS_DEPENDENCY(LiveRegMatrix)
INITIALIZE_PASS_DEPENDENCY(LiveStacks);
INITIALIZE_PASS_DEPENDENCY(AAResultsWrapperPass);
INITIALIZE_PASS_DEPENDENCY(MachineDominatorTree);
INITIALIZE_PASS_DEPENDENCY(MachineLoopInfo);
INITIALIZE_PASS_DEPENDENCY(MachineBlockFrequencyInfo);
INITIALIZE_PASS_END(RAMinimal, "regallominimal", "Minimal Register Allocator",
false, false)这里的INITIALIZE_PASS_DEPENDENCY声明的作用和getAnalysisUsage中设置依赖类似,其中逐个简要说明其中的意义:
- SlotIndexes.用于给指令编排序号, 编排序号的重要作用之一在于为变量的LiveInterval确定区间.比如说指令A序号为01B指令B的序号为09B,因此活跃在这两个指令之间的变量的LiveInterval就对应了[01B, 09B),不过这只是其中一段.
- VirtRegMap.维护了一些虚拟寄存器有关的Map,比如说到物理寄存器的Map(也正是寄存器分配时需要设置的).
- LiveIntervals.维护了变量的LiveInterval的集合,关于LiveInterval其中主要的数据结构有一个VNInfo,代表了一个def点(通过SlotIndex表示),还有一个Segment,表示一个左必右开区间(start、end,还有一个指向VNInfo的指针),表示一段活跃期,LiveRange表示一个虚拟寄存器的完整周期,是Segment的集合.而LiveInterval继承自LiveRange,主要是多了Reg寄存器和Weight权重.
- LiveRegMatrix.通过两个维度判断虚拟寄存器之间有无interference.分别是Slot indexes和register unit.数据成员主要是一个VirRegMap和LiveIntervals的指针.有checkInterference,assign等方法.
- LiveStacks.类似于活跃分析,但是分析的不是寄存器,而是Slot.(说实话不是太懂这个东西).
因此这些分析结果也都有相应的数据成员,在runOnLoop函数中,一开始就是初始化与这些以来相关的数据结构:
const SlotIndexes *SI; // 用于给每个指令编成序号
// Virtual Register Mapping
VirtRegMap *VRM; // 是一个从虚拟寄存器到物理寄存器的Map, 也是我们实现寄存器分配所需要填充的内容
const TargetRegisterInfo *TRI; // 目标寄存器Info
MachineRegisterInfo *MRI;
// Live Intervals
LiveIntervals *LIS; // 寄存器的活跃间隔
std::queue<LiveInterval *> LIQ; // FIFO Queue
LiveRegMatrix *LRM;// Register Class Information
RegisterClassInfo RCI;
std::unique_ptr<Spiller> SpillerInst; // 提供了spill方法
SmallPtrSet<MachineInstr *, 32> DeadRemats;在runOnMachineFunction中,做完一些初始化之后,将LiveInterval结点一个个地加入LIQ,之后从LIQ中将结点逐个弹出,并对其调用selectOrSplit.其中弹出队列中的处理过程基本如下:
while (LiveInterval *const LI = dequeue()) { // 将FIFO逐个弹出并进行染色
// again, skip all unused registers
if (MRI->reg_nodbg_empty(LI->reg())) {
LIS->removeInterval(LI->reg());
continue;
} // 如果出现了nodbg_empty就需要移除
LRM->invalidateVirtRegs();
// 2. Allocate to a physical register (if available) or split to a list of
// virtual registers.
SmallVector<Register, 4> SplitVirtRegs;
MCRegister PhysReg = selectOrSplit(LI, &SplitVirtRegs); // Split也就是需要溢出的,这种情况下,需要将其进行split
if (PhysReg) { // 如果是可以分配的寄存器,就可以进行赋值了,寄存器分配的目标就在于设置一个Map
LRM->assign(*LI, PhysReg);
}
// enqueue the splitted live ranges
for (Register Reg : SplitVirtRegs) { // 所返回的
LiveInterval *LI = &LIS->getInterval(Reg);
if (MRI->reg_nodbg_empty(LI->reg())) {
LIS->removeInterval(LI->reg()); // 对于分裂的如何进行处理??为什么需要进行分裂呢?
continue;
}
enqueue(LI);
} // 对于Split的应该进行怎样的处理呢?
} // while (dequeue())其中最重要的函数是selectOrSplit.该函数涉及的操作如下:
- 首先获取一个可供分配的物理寄存器的序列.
- 之后对于该指令,遍历可用物理寄存器序列,通过LiveRegMatrix中的checkInterference判断是否冲突,如果不冲突就直接返回就好了;如果冲突就加入一个溢出候选寄存器序列(因为溢出的变量虽然会溢出到内存中,但是从内存中取出此变量时仍然需要寄存器).
- 遍历溢出候选寄存器序列,从中调用spillInterferences(可以尝试从候选寄存器中找出来一个可以分配给当前指令的,因此也就免去了对当前指令的spill),如果溢出寄存器序列中有可以spill(其实spill的是其对应的变量)的,就返回该寄存器.相关的源代码如下:
for (MCRegister PhysReg : PhysRegSpillCandidates) { // 这一部分考虑进行split的操作
if (!spillInterferences(LI, PhysReg, SplitVirtRegs)) { // 会讲split的结果返回到SplitVirtual中
continue;
}
return PhysReg; // 这种情况,就是该PhysReg可以腾出来分配给当前指令的情况
}- 最终将当前指令spill,也就是前面都没有出现返回的情况,相关实现如下:
LiveRangeEdit LRE(LI, *SplitVirtRegs, *MF, *LIS, VRM, this, &DeadRemats); // 用于修改Liveness范围的
SpillerInst->spill(LRE);接下来细说spillInterferences.
bool spillInterferences(LiveInterval *const LI, MCRegister PhysReg,
SmallVectorImpl<Register> *const SplitVirtRegs) {
SmallVector<LiveInterval *, 8> IntfLIs;
for (MCRegUnitIterator Units(PhysReg, TRI); Units.isValid(); ++Units) { // 物理寄存器可能是有别名的,所以采用这种方式遍历
LiveIntervalUnion::Query &Q = LRM->query(*LI, *Units);
Q.collectInterferingVRegs();
for (LiveInterval *const IntfLI : Q.interferingVRegs()) { // 遍历其中冲突的虚拟寄存器
if (!IntfLI->isSpillable() || IntfLI->weight() > LI->weight()) {
return false;
}
IntfLIs.push_back(IntfLI);
}
}
// Spill each interfering vreg allocated to PhysRegs.
for (unsigned IntfIdx = 0; IntfIdx < IntfLIs.size(); ++IntfIdx) {
LiveInterval *const LIToSpill = IntfLIs[IntfIdx];
// avoid duplicates
if (!VRM->hasPhys(LIToSpill->reg())) {
continue;
}
// Deallocate the interfering virtual registers.
LRM->unassign(*LIToSpill);
LiveRangeEdit LRE(LIToSpill, *SplitVirtRegs, *MF, *LIS, VRM, this,
&DeadRemats);
SpillerInst->spill(LRE);
}
return true;
}简而言之,这个过程分为两步骤:
- 第一阶段,收集该物理寄存器所涉及的虚拟寄存器,由于物理寄存器也许有别名,所以在通过
MCRegUnitIterator遍历,之后通过LRM中的query返回LiveIntervalUnion::Query,之后可以获取该Unit所对应的与LI冲突的虚拟寄存器的集合,然后再对此遍历,只要出现了不可spill或者spill weight大于LI的,就返回false.因此可以说只有当一个候选物理寄存器中与LI冲突的所有虚拟寄存器都比LI的spill weight小,才可以将该候选物理寄存器spill. - 第二阶段,将该物理寄存器所涉及的虚拟寄存器溢出.
使用基于spill cost的优先级队列
在example中只是使用了普通队列, 在LLVM basic register allocator中,使用的是一个优先级队列,并且根据计算的LiveInterval的权重来排序,该权重用于衡量spill的代价,其中最常用的计算方式如下:
Cost = [(is_defs + is_use)*10^loop-nest-depth]/degree
因此在将结点加入到队列时,导致代价低在队列底部,代价高的在上部,这使得在后来pop队列时,代价高的优先具有被分配的机会,因此实际被spill的往往都是代价比较低的变量,显然相比使用普通的队列是一种优化.
此外,在example中,没有实现split,split是一种通过将一个大的活跃区间分割成一个个小活跃区间的方法,用于降低spill的代价,在example中,SplitVirtRegs集合全程都是空的.
相关参考
Tutorial-Bridgers-LLVM_IR_tutorial