记录一个网络库的核心实现
TinyMuduo这个项目可以说是在理解并模仿陈硕的muduo的基础上所作,我在上个学期其实就想要着手去做这件事,不过中间因为种种原因搁浅了,到了寒假有时间了再次拾起,可以说是把之前挖的坑给填上了,项目地址:TinyMuduo.
关于这个项目的价值,首先我认为muduo中对于Modern C++的应用以及代码风格非常具有借鉴价值,其次可以对系统编程和网络编程有很大的锻炼,尤其是这个过程中需要查阅许多Linux系统调用的资料、以及多线程的一些东西,并且代码量也挺大,仅仅是我实现的这个Tiny版的,其核心库就有3k行左右的代码量,算上example和test大概都有将近5k行代码,虽然算不上是原创,但是自己一点一点地码出来并且进行debug,颇耗费时间.
在这篇博客之中,我会首先介绍其总体架构,然后就其中的某些核心模块进行说明,最后写一些我从中学习到的一些经验性的东西.
1. 总体架构
首先需要介绍的是,什么是reactor模式.reactor模式中,会有一个(或者多个)事件监听分发器,可以通过将特定的文件描述符和事件类型及其回调注册到事件监听器上,之后一旦某些被注册的相关事件触发,就会执行相应的回调.使用这种模式最大的优点在于,无需主动等待某个文件描述符的事件触发(避免了因为等待某个文件描述符的事件而阻塞了其他的文件描述符).结合网络编程的话,这些事件往往就有一个listen的fd的可读事件(往往是新连接建立)、一个tcp连接对应的fd上的可读事件(连接上有新数据到来)等等.
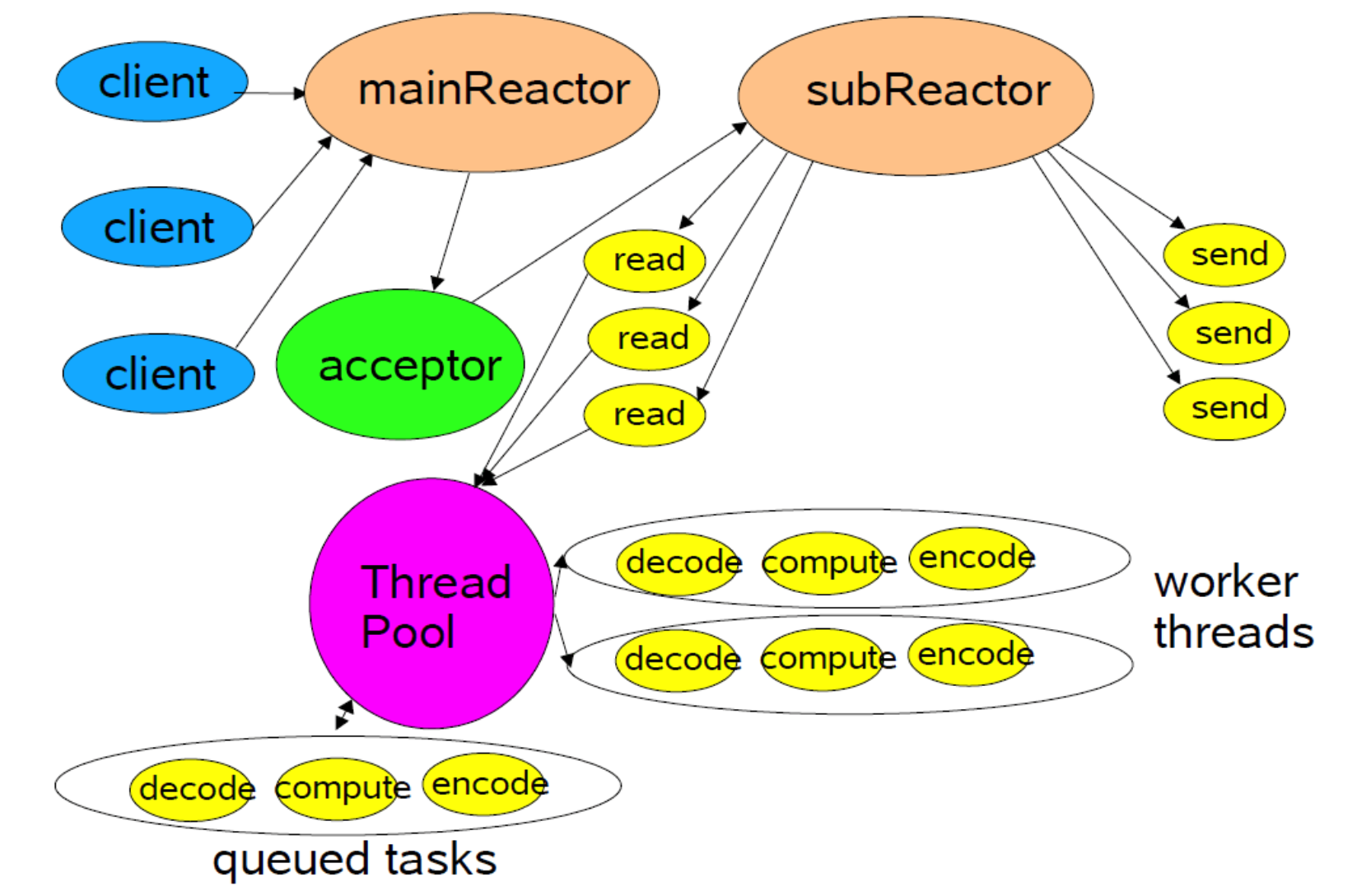
2. 核心模块
1).Socket、Channel
Socket和Channel这两部分可以说是系统中最最基础的组件,前者封装了一个打开了的非阻塞文件描述符,后者描述了一个文件描述符在注册到reactor时所需要的属性和方法.两者组合绑定到一起,描述了一个“会被注册到reactor的非阻塞文件描述符”,这么一种对象.
至于Socket的实现中的一些细节,没有太多可说的,其车成员函数大概是对listen、accept、bind等系统调用做一层浅浅的封装.其中运用了RAII保证对Socket(文件描述符)的自动关闭,其析构函数如下:
Socket::~Socket() {
::close(fd_);
}关于Channel的实现则要复杂得多,这一部分首先要考虑的是,如果是基于Epoll的事件监听器,都需要哪些属性?
- 要被注册到Epoll中的文件描述符.
- Interest Event的类型.
- 返回Event类型及其相关回调.
因此其数据成员如下:
bool in_loop_; // 是否已经加入到loop中
ChannelState state_; // 被注册到Epoll中,该Channel对应的fd所处的状态.
EventLoop *owner_loop_; // 所归属的循环体
uint32_t event_; // Interested Event
uint32_t revent_; // 从epoll_wait中返回的事件
const int fd_; // 需要被监听事件的文件描述符
std::weak_ptr<void> tie_;
bool tied_;
// read、write、close、error等类型事件的回调函数
CallBackFunc read_callback_;
CallBackFunc write_callback_;
CallBackFunc close_callback_;
CallBackFunc error_callback_;其中相关的api主要是对于event、revent等字段的修改和返回等操作.之所以需要一个EventLoop指针,是因为每个Channel都归属于一个EventLoop(因为每个EventLoop中都会有一个惟一Epoller),可以说每个Channel都需要借助EventLoop访问其所归属的Epoller,才可以进行EPOLL_CTL_ADD,EPOLL_CTL_MOD等等,这些操作正是当一个Channel中对应的interested
event更新时所需要进行的.因此在Channel中也就有一个update函数,其实现如下:
void update() {
owner_loop_->updateChannel(this);
}
void EventLoop::updateChannel(Channel *channel) {
epoller_->updateChannel(channel);
}在epoller中的updateChannel会根据当前fd在epoller的状态(也就是Channel中的state字段)去判断所需要执行的更新操作,究竟是EPOLL_CTL_ADD、EPOLL_CTL_MOD还是EPOLL_CTL_DEL.这个将会在后面细说.至于update什么时候需要调用,那就是当Channel中所对应的文件描述符的event(Interested event)发生改变的时候.比如说:
void setReadable() {
event_ |= READ_EVENT;
update();
}
void setWritable() {
event_ |= WRITE_EVENT;
update();
}每个Channel中还有一个handleEvent方法,该方法起到一个分发器的作用,在Reactor的Epoller中,等到epoll_wait返回到某些事件时,将其中的每个Channel的revet都设置好,然后会从中遍历每个Channel调用的handleEvent方法,在该方法中,会通过检查revent的事件类型,调用相应的回调,具体逻辑如下所示:
if (revent_ & READ_EVENT) { // 可读事件
if (read_callback_) {
read_callback_();
}
}
if (revent_ & WRITE_EVENT) { // 可写事件
if (write_callback_) {
write_callback_();
}
}
if (revent_ & EPOLLERR) {
if (error_callback_) {
error_callback_();
}
}
if ((revent_ & EPOLLHUP) && !(revent_ & EPOLLIN)) {
if (close_callback_) {
close_callback_();
}
}最后,简要地说明一下Socket和Channel之间的关系,在一个基于事件驱动的网络库中,两者往往不是独立存在使用的,通常组合在一起,描述一个“会被注册到reactor并监听的非阻塞文件描述符”,比如说后面的Acceptor、TcpConnection,因此两者的生命周期往往也是“同生共死”的.
2).Epoller、EventLoop
Epoller是实现事件监听与分发的核心对象,其核心是linux epoll,这是一种常用的IO复用技术.其工作模式相当于epoller维护了一个个文件描述符的interest events,当其中某个(某些)文件描述符的interest event触发的时候,epoller就可以返回这些事件,接着就可以对这些事件一一进行相应处理.
其中重要的API,有epoll_create,用于创建一个“事件监听器”,返回的是一个文件描述符,因此对于这种对象也是通过文件描述符来进行管理的(因此其析构函数和Socket一样,都对该文件描述符进行close),还有epoll_wait,阻塞地等待interest events中有事件触发并返回,返回值为触发的interest event的数量,一般搭配while循环,以一种类似于轮询的方式运行.epoll_ctl则有ADD、MOD、DEL等操作类型,分别与文件描述符的注册、修改interest event类型、移除有关.
由于Epoller通常是放置一个循环体中,每一轮通过epoll_wait工作, 在该网络库中,EventLoop正是对这样“运行着Epoller的循环体”所进行的封装,因此对于两者的关系,我们可以说一个EventLoop是一个Epoller的归属者.
在EventLoop中的核心函数如下:
void updateChannel(Channel *channel);
void removeChannel(Channel *channel);
void loop();
void runInLoop(QueuedFunctor func);loop用来运行循环体,也就是启动该EventLoop进行工作.runInLoop被外部调用,将一些需要执行的任务加入到EventLoop的任务队列中,运行.updateChannel、removeChannel是对Epoller中updateChannel、removeChannel的一层wrapper.
EventLoop的核心数据成员如下:
const pid_t thread_id_;
std::mutex mutex_;
std::unique_ptr<Epoller> epoller_; // 一个EventLoop是一个Epoller的所有者
std::unique_ptr<TimerQueue> timer_queue_;
// 用于唤醒正在因为epoll_wait所导致的休眠
int wakeup_fd_;
std::unique_ptr<Channel> wakeup_channel_;
ChannelVector active_channels_; // 用于存放从poll中所返回的channels
std::deque<QueuedFunctor> queued_list_;为什么需要一个wake_fd_及其Channel?
对于一个runInLoop的任务来说,不希望该任务会因为epoll_wait的阻塞导致迟迟没有运行.因此需要一个wakeup_fd将其唤醒.wakeup_fd就像其他文件描述符及其Channel一样在EventLoop被初始化时注册,并设置为可读.当执行wakeup函数时,实质上是对该文件描述符进行write,因此会触发可读事件,EventLoop就从epoll_wait的休眠中苏醒过来了.
loop方法的实现逻辑如下,也描述了一个事件循环的工作模式:
void EventLoop::loop() {
is_looping_ = true;
is_quit_ = false;
while (!is_quit_) {
active_channels_.clear();
auto return_time = epoller_->epoll(defaultTimeoutMs, active_channels_);
for (auto channel : active_channels_) {
channel->handleEvent(); // 处理返回的事件
}
doQueuedFunctors();
}
is_looping_ = false;
}简而言之,首先调用Epoller中的epoll方法(实际上就是对epoll_wait的封装,当从epoll_wait返回之后,将结果填充到active_channels_,还包括对返回事件类型的设置).之后遍历active_channels_,分别调用其中的事件回调,处理事件.最后将外部加入到任务运行,这就是一轮循环中所做的事情.
上面所涉及到的Epoller中关于epoll方法的实现细节如下:
TimeStamp Epoller::epoll(int timeout_second, ChannelVector &channel_list) {
auto timeout_millsecond = timeout_second; // epoll中的单位是mill second,要先转化一下
if (timeout_millsecond > 0) {
timeout_millsecond = timeout_second * static_cast<int>(TimeStamp::MillSecondsPerSecond);
} // 如果是-1000就会出现反复频繁触发的问题
uint16_t epoll_cnt = ::epoll_wait(epoller_fd_, &*events_.begin(),
static_cast<int>(events_.size()), timeout_millsecond); // max_size就是一次读取的最大事件数
TimeStamp now_time = TimeStamp::getNowTimeStamp();
channel_list.reserve(epoll_cnt);
for (size_t i = 0; i < epoll_cnt; ++i) { // 这里有一个地方需要注意, 要用的是epoll_cnt,而不是直接遍历events
// 从中读取指针,其中藏着Channel的指针
Channel *channel = static_cast<Channel*>(events_[i].data.ptr);
channel->setRevent(events_[i].events);
channel_list.push_back(channel); // 将Channel追加进入
}
if (epoll_cnt == events_.size()) { // 需要扩容,借助vector的可扩容机制
events_.resize(2 * epoll_cnt);
}
return now_time;
}借助epoll_event中的data保存Channel指针
epoll_event结构体描述了一个可以被epoll监听的事件,其组成如下:
struct epoll_event { uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ } __EPOLL_PACKED; typedef union epoll_data { void *ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t;其中data是一个联合体,用于保存与该event相关的一些数据,其中ptr可以保存任何类型的指针,如果将Channel的指针保存在其中,就可以在epoll_wait返回之后直接通过返回的epoll_event来获取对应的Channel了,无需额外再维护一个fd到Channel的map.
至于updateChannel函数,其本质上也就是Epoller中的updateChannel,该函数利用了channel对应的文件描述符在Epoller中的具体状态来判断接下来具体的update行为.update最底层是利用了epoll_ctl函数来进行操作,相关代码如下:
void Epoller::update(int32_t op, Channel *channel) {
struct epoll_event event;
memset(&event, 0, sizeof(event));
event.events = channel->getEvent();
event.data.ptr = channel;
int ret = ::epoll_ctl(epoller_fd_, op, channel->getFd(), &event);
if (ret < 0) {
LOG_ERROR << "epoll ctl " << channel->getFd() << " error, epoller fd is " <<
epoller_fd_ << ", the errorno is " << errno;
}
}epoll_ctl的参数分别对应了epoller关联的文件描述符、CTL操作类型(MOD、DEL、ADD)等类型、被监听的文件描述符、更新后的epoll_event.
关于Epoller的数据成员如下:
uint16_t epoller_fd_;
EventsVector events_;
ChannelsMap channels_map_;分别是Epoller本身的文件描述符,还有用于监听的interest event的集合,当前所维护的Channel的集合.这里的Epoller是使用的水平触发.
epoll水平触发和边缘触发的区别
水平触发指的是,一旦被监听的文件描述符中的事件处于某种状态(符合interest event),调用epoll_wait就会一直返回,直到该事件事件被处理,以至于不再处于该状态.边缘触发指的是,只在文件描述符的event类型发生变化的时候返回一次.
水平触发模式的使用对后来对于读写事件的处理产生了重要的影响,在后面结合Buffer以及TcpConnection会细说.
3).Acceptor、TcpConnection、TcpServer
关于Acceptor和TcpConnction,都可以说基于Socket和Channel的组合所构成的对象,前者指的是一个持续listen用来接收连接的文件描述符,后者则是从Acceptor中所accept所得的网络连接.一个Acceptor,和一个个活跃的TcpConnection构成了一个TcpServer类的核心成分.
由于这时基于epoll IO复用的网络库,Acceptor和TcpConnection也需要被加入到Epoller对象及其EventLoop中.在这两个class的设计中,主要考虑的是如何将网络事件和Channel中的Epoll事件结合起来.比如说Acceptor连接到来对应了Channel中的read事件,网路连接的数据到来、数据可写、连接关闭等事件也就对应了Channel中的read、write、close.考虑清楚这些对应关系之后,就需要考虑这些事件所对应的回调了.
关于Acceptor中所涉及的事件回调,最核心的就是readHandle,对于一个listen的描述符来说,读事件就意味着有新的连接到来,对其调用accept就行了,正常情况下再根据返回的文件描述符和地址代入到newconnection_func_中(TcpServer会为其提供的回调),其中的readHandle的实现如下:
void Acceptor::handleNewConn() {
SockAddress peer_addr;
auto accept_fd = socket_.accept(&peer_addr);
if (accept_fd < 0) {
if (errno == EMFILE) { // 错误类型对应了文件描述符耗尽的类型
::close(idel_fd_);
idel_fd_ = ::accept(socket_.getFd(), nullptr, nullptr);
::close(idel_fd_);
idel_fd_ = ::open("/dev/null", O_RDONLY | O_CLOEXEC);
}
} else { // 表示正常返回,执行
if (newconnection_func_) {
newconnection_func_(accept_fd, peer_addr); // 执行回调函数
} else {
::close(accept_fd); // 关闭返回的socket
} // 加入到该循环对应的epoll中
}
}借助idel_fd_处理文件描述符耗尽的问题
如果在readHandle中由于文件描述符耗尽的原因,就会导致accept一直失败的问题,如果一直无法accept对该连接返回成功,该事件就一直得不到处理,导致在epoll_wait一直返回.在这里利用一个提前就分配好的idel_fd_,将该文件描述符关闭后,accept返回到idel_fd中,然后再关闭回到初始的状态,该连接所对应的事件就可以得到处理,也就不会留在epoll_wait中一直返回了.
关于TcpConnection的实现则是比较复杂的:
- TcpConnection中的读、写、关闭、错误事件都需要设置相应的handle.不像Acceptor基本只用到了readHandle.
- TcpConnection需要考虑数据的读写问题.读写问题需要结合非阻塞IO以及epoll水平触发的特点来设计.
- 对于连接关闭问题的处理较复杂,需要考虑此时进行读写行为的影响.
TCP连接所需要关注的三个半问题
这三个半问题指的是:连接的建立、数据的读写、连接关闭、连接关闭后的回调(算半个).
其中前三个问题是最为必要的,接下来将会围绕着这几个问题来展开介绍TcpConnection中的相关实现.
关于连接的建立,需要结合Acceptor和TcpServer来进行分析,在前面我们已经知道Acceptor的readHandle中已经将到来的新连接获取了其对应的文件描述符以及地址,接下来要做的就是执行一个newconnection_func_(作为一个Acceotor的私有数据成员(函数回调类型的)),该回调函数由TcpServer提供,其实现如下:
void TcpServer::newConnFunc(int fd, SockAddress &address) {
// 首先获取一个io loop用来处理
auto io_loop = pool_->getNextLoop();
// 根据fd和address创建一个Connection
char name_buf[ip_.length() + 32];
memset(name_buf, 0, sizeof(name_buf));
sprintf(name_buf, "#%s:%u:%u", ip_.c_str(), port_, curr_conn_number_++);
std::string conn_name = name_buf;
sockaddr_in localaddr;
bzero(&localaddr, sizeof(localaddr));
socklen_t addrlen = static_cast<socklen_t>(sizeof(localaddr));
if (::getsockname(acceptor_->getListeningFd(),
reinterpret_cast<sockaddr*>(&localaddr), &addrlen) < 0) {
LOG_ERROR << "Get local sockname error in TcpServer, the acceptor fd is " << acceptor_->getListeningFd();
}
SockAddress local_address(localaddr);
auto conn = std::make_shared<TcpConnection>(io_loop, conn_name, fd,
local_address, address);
connection_map_[conn->getName()] = conn;
conn->setCloseCallback(std::bind(&TcpServer::removeConnForClose, this, std::placeholders::_1));
conn->setConnectionCallback(connection_callback_);
conn->setMessageCallback(message_callback_); // 设置回调函数
io_loop->runInLoop(std::bind(&TcpConnection::establish, conn));
}这一部分属于TcpServer部分的代码,将会在Acceptor所处的线程中执行,然后从线程池中挑选出一个io线程,该线程中的EventLoop(Epoller)将会用来监听这个新创建的连接.下面的过程就是创建一个TcpConnetion对象,并且加入到TcpServer的map中,并且设置好相关的回调函数,之后调用TcpConnetion中的establish函数,注意该函数是借助runInLoop,使其恰好运行在该TcpConnection所处的io线程中.因此也可以说连接的创立在网络库中是一个异步的过程.至于TcpConnection中的establish函数,其实现细节如下:
void TcpConnection::establish() { // 该函数也要保证放在该loop所处的线程中处理
if (state_ == Connecting) { // Connecting表达的是一个尚未建立连接的状态,或者可以说是即将建立连接的意思
setState(ConnectionState::Connected); // 设置成已经建立好连接
channel_->tie(shared_from_this()); // tie
channel_->setReadable(); // channel注册可读事件到Epoller上
}
connection_callback_(shared_from_this()); // 连接建立/销毁相关的回调
}其中关于tie的设置,与Channel中事件回调中,是否需要判断悬垂指针有关.
tie的作用是什么?
std::weak_ptr<void> tie_; bool tied_; void Channel::tie(const std::shared_ptr<void> &obj) { tie_ = obj; tied_ = true; } void Channel::handleEvent() { if(tied_) { auto guard = tie_.lock(); if(guard) { handleEventWithGuard(); } } else { handleEventWithGuard(); } }用于判断该Channel对应的TcpConnection有没有被析构,防止handleEvent还未执行完就出现TcpConnection(包括其中的Channel)被析构的情况.
连接关闭分为两种,第一种是被动关闭,也就是client端断开了连接,第二种是server端主动断开连接,这两种处理方式不同.其中对于第一种,体现为该连接对应的事件在epoll_wait中返回为可读事件,但是::read返回值为0.正如同readHandle中的代码:
void TcpConnection::readHandle() {
if (!channel_->isReadable()) {
return;
}
int error_no;
ssize_t retn = read_buffer_.read(channel_->getFd(), &error_no);
if (retn > 0) { //正常的读取
message_callback_(shared_from_this(), &read_buffer_, TimeStamp::getNowTimeStamp());
} else if (retn == 0) { // 表明client端已经退出.
closeHandle();
} else {
errorHandle();
}
}closeHandle中代码如下:
void TcpConnection::closeHandle() {
setState(ConnectionState::DisConnected);
channel_->setDisable();
TcpConnectionPtr conn(shared_from_this());
close_callback_(conn);
}
// close_callback_
void TcpServer::removeConnForClose(const TcpConnectionPtr &conn) {
loop_->runInLoop(std::bind(&TcpServer::removeConnForCloseInLoop, this, conn));
}
void TcpServer::removeConnForCloseInLoop(const TcpConnectionPtr &conn) {
auto findit = connection_map_.find(conn->getName());
if (findit != connection_map_.end()) {
connection_map_.erase(findit);
conn->getLoop()->runInLoop(std::bind(&TcpConnection::destroy,
conn));
}
}
// TcpConnection::destory
void TcpConnection::destroy() {
channel_->setDisable();
channel_->remove();
connection_callback_(shared_from_this());
}其实其中所涉及的操作主要包含channel的移除和在TcpServer中map中的移除.由于one loop per thread的原则,这两部分动作还是需要分开的,其中读map中TcpConnection的移除作用与主线程(也就是TcpServer中的base thread), 该channel的移除应该在该TcpConnection所处的io线程中,但是channel在TcpConnection中是通过std::unique_ptr管理的,在两个线程中究竟谁先移除这一点无法确定,我们期望的情况是TcpConnection能够等到channel的remove等操作做完之后在移除(析构).如果真的该TcpConnection在channel移除前就析构了,后面的channel就成了悬垂指针,channel的remove就不能成功了.因此在这里(closeHandle中)创建了一个临时的std::shared_ptr,使得该TcpConnection的总的引用计数+1,并且代入到close_callback(以及destroy),所以这个时候及时map中的erase调用后,TcpConnection的引用计数也不会是0,而是1.知道等到destory执行完之后,该TcpConnection对象才真正被析构.实质上就是延长该TcpConnection对象的生命周期直到destory运行完.当一个TcpConnection被析构的时候,其中的Socket也会被析构,因此close掉了.
然后就是server端主动关闭连接的行为,这里需要额外考虑的情况就是如果此时server端正在写应该怎么办?怎样保证client接收到的可读信息是完整的?
void TcpConnection::shutdown() { // 通常在服务端进行半关闭
// 要考虑到写操作的情况,如果当前不处于writable
setState(ConnectionState::DisConnecting); // 设置成Connecting,writeHandle中会有相应的判断
loop_->runInLoop(std::bind(&TcpConnection::shutdownInLoop, this));
}
void TcpConnection::shutdownInLoop() {
if (!channel_->isWritable()) {
Socket::shutdownWrite(channel_->getFd());
}
}因此这里只考虑关闭对该socket的“写”,并且设置状态为DisConnecting.该DisConnecting作用在writeHandle中有所体现:
if (write_buffer_.getReadableSize() == 0) { // 如果改写的东西都已经写完了
channel_->disableWritable();
// 还需要考虑WriteComplete的情况及其回调函数
if (state_ == ConnectionState::DisConnecting) {
shutdownInLoop(); // 执行未完全完成的关闭状态
}
}以上分支对应了如果要写的数据都已经写完的时候,首先关闭channel的可写事件,然后如果状态为DisConnecting,表明之前调用过shutdown函数,也就是说server之前要主动关闭该连接.如果符合就调用shutdownInLoop,之后才正式的设置为“不可写”.
为什么这里不是彻底关闭(close),而是一个half-open connection状态的连接
此时我们可以确定我们确实已经将写缓冲区中的数据写入到该连接的fd上了,但是client端究竟有没有接收到,这一点我们无法确定,如果此时client还没有完全接收到完整的数据就close掉的话,就会造成client端接收的数据缺失.所以这里的shutdown不会调用close,只是调用shutdown,关闭“写”,使得server再后来无法再写入新的数据.
等到client端的readHandle中出现返回0时,才是真正close的时候.
接下来说明关于TcpConnection上的读写操作,在此之前,首先需要说一下Buffer.这里的TcpConnection所使用的非阻塞IO,epoll又是水平触发,这些因素都对读写的方式有重要的影响.
Buffer对于“水平触发epoll+非阻塞socket”数据读写的必要性
首先对于读数据来说,只要有可读数据就会一直返回,因此无法确定一次读入的数据究竟是不是完整的一个报文,因此对于所读入的数据需要有一个Buffer缓存起来.
对于写入的数据,::write不一定能够将所需要写的所有数据一次性地写入,因此需要有一个Buffer用来保存所需要写到数据,每成功写入一点Buffer就少一点,直到Buffer为空就可以视为这一段数据都送走了.
首先来说一说read相关的.在readHandle中,首先只是将从连接上到来的数据先读入到inbuffer上,然后调用message_callback_.其中在网络应用中,往往有对于数据内容的解析,在这个解析的过程中,所读取到的数据才被分为了一个个数据包(报文).一个报文往往由多段读取的数据结果组成,因此最终一个报文的解析过程应该也分为好几步,因此TcpConnection中有一个数据成员context,表示的就是每次解析所保存的“上下文信息”,如下所示:
std::any context_;比如HttpServer中的onMessage函数:
void HttpServer::onMessage(const TcpServer::TcpConnectionPtr &conn, Buffer *buffer,
TimeStamp timestamp) {
HttpParser* parser = std::any_cast<HttpParser>(conn->getContext()); // 此时已经
if (!parser->parsing(buffer)) { // 中间出现了错误
conn->send("HTTP/1.1 400 Bad Request\r\n\r\n");
conn->shutdown();
}
if (parser->isFinishAll()) {
onRequest(conn, parser->getRequest());
parser->reset(); // 同时清空
}
}在对于http的处理中,我们可以将HttpParser看作是一个解析报文的状态机,一边读取当前Buffer中的数据,一边根据解析的结果设置其中的HttpRequest,最终是否能够判断是一个完整的报文取决于是否根据合法格式解析完一整个报文.也就是其中的parser->isFinishAll()这个时候表示的是一个完整的Request报文已经解析完了.因此到这里可以说,网络库只负责处理TcpConnection上的可读事件,并将数据填充到Buffer中,至于Buffer中的数据如何解析和分包,则取决于用户定义的代码如何取出并解析字符串,属于业务逻辑的部分.网路库的用于代码中,对于较复杂的情况,需要定一个Context相关的class(也很类似于状态机),保存上次解析所得的结果,好使得后来的解析能够基于上次的结果进行.
之后是与写数据相关的东西.与之有关的是,TcpConnection所提供的外部接口send,当编写server端的用户代码时,经常需要调用.其具体实现如下:
void TcpConnection::send(const char *content, size_t len) { // send的实际操作中可能涉及到IO,因此保证其放入到IO线程中操作
if (state_ == ConnectionState::Connected) {
if (loop_->isOuterThread()) {
loop_->runInLoop(std::bind(&TcpConnection::sendInLoop, this, content, len));
} else {
sendInLoop(content, len);
}
}
}
void TcpConnection::sendInLoop(const char *content, size_t len) {
if (state_ == ConnectionState::DisConnected) {
return;
}
ssize_t wroten = 0, remain = len;
bool has_error = false;
if (!channel_->isWritable() && write_buffer_.getReadableSize() == 0) {
wroten = ::write(channel_->getFd(), content, len);
if (wroten >= 0) {
remain -= wroten;
} else {
LOG_ERROR << "the send in loop error";
has_error = true;
}
}
if (remain != 0 && !has_error) { // 还有剩余的话,就先输出到buffer上
write_buffer_.append(content + wroten, remain);
if (!channel_->isWritable()) {
channel_->setWritable();
}
}
}在muduo中,还有与高水位写相关的回调,但是在这里我没有实现,我只保留了最主干的一些功能.简而言之,Buffer等本身并非线程安全,因此对于send操作还是通过runInLoop使得其只能运行在该TcpConnection所处的io线程中.在sendInLoop中,
在水平触发epoll+非阻塞socket中,如何控制write事件的开关?
首先我们需要知道的是,在一般情况下,write事件的触发条件是什么?简而言之,只要内核中的buffer没有写满,就会一直在epoll_wait中返回可写事件,因此及时我们什么都不想写,也一直都会有这种事件返回,这根本就是无用的,浪费开销的行为.因此一直保持writable是不可取的.所以考虑的是一种,需要写时再打开,写完就立马关闭的方式.
首先此时不是处于writable的状态,就先尝试直接通过::write写数据,如果直接就写完了,就可以不做多余的事情.否则,就将剩余的部分加入到write_buffer中,并且开启channel中的writable.剩余的部分就借助writeHandle,将缓冲区中的内容写入.当缓冲区中的数据为空时,表示的写结束.其中writeHandle的实现如下:
void TcpConnection::writeHandle() {
if (!channel_->isWritable()) {
return;
}
int error_no;
ssize_t retn = write_buffer_.write(channel_->getFd(), &error_no);
if (retn > 0) {
write_buffer_.retrieve(retn); // 移动write index
if (write_buffer_.getReadableSize() == 0) { // 如果改写的东西都已经写完了
channel_->disableWritable();
if (state_ == ConnectionState::DisConnecting) {
shutdownInLoop(); // 执行未完全完成的关闭状态
}
}
} else {
errno = error_no;
LOG_ERROR << "write error in write handle";
}
}每次writeHandle就写一点,写完之后就关闭channel的writable.此时还考虑到如果此时有等待写操作的shutdown的情况.
至此,可以说围绕着连接建立、关闭、数据读写,就可以将TcpConnection以及TcpServer中最核心的代码逻辑梳理完了.
3. 经验与思考
1) one loop per thread和线程安全
one loop per thread不仅仅是使得每个线程都运行一个循环体那么简单,更重要的一点是,每个线程都有特定职责,根据其职责使得对于某些对象的操作只能局限于某一个循环之中,因此原本因为某些对象可能会在不同线程中被操作而导致的data race被化解,因此它们终将会在其所归属的线程中被操作.
正如每一个thread都与一个EventLoop相绑定一样,很多对象也都与某个EventLoop想绑定,进而也可以说这些对象都与唯一一个线程想绑定.比如说Acceptor对象,它必定和TcpServer中的Base Loop相绑定;TcpConnection对象也将会和线程池中的某个IO Loop绑定.因此一些涉及到对Acceptor进行的操作,比如说TcpServer中的start:
void TcpServer::start() {
if (is_running_) {
return;
}
is_running_ = true;
loop_->runInLoop(std::bind(&Acceptor::listen, acceptor_.get()));
pool_->start();
}
void Acceptor::listen()
{
loop_->assertInLoopThread();
listening_ = true;
acceptSocket_.listen();
acceptChannel_.enableReading();
}显然是需要将Acceptor对象的listen操作runInLoop到Acceptor所绑定的线程中的.正是有了这种协议的保证,listen中对于内部数据的操作即使本身不是线程安全的,也没用锁去专门保护它们,但也能够防止线程安全.因为在runInLoop的保证下,无论是哪些线程调用了start,其中对于Acceptor对象的操作(listen)都转化到了一个线程中.
再举一个关于TcpConnection的例子,TcpConnection中的很多数据成员及其操作本身都不是线程安全的,尤其是读写Buffer.应对这种问题的方式仍然是runInloop,比如说:
void TcpConnection::shutdown() {
setState(ConnectionState::DisConnecting); // 设置成Connecting,writeHandle中会有相应的判断
loop_->runInLoop(std::bind(&TcpConnection::shutdownInLoop, this));
}
void TcpConnection::shutdownInLoop() {
if (!channel_->isWritable()) {
Socket::shutdownWrite(channel_->getFd());
}
}其中shutdown函数可以说是提供给上层的一个接口,它会在什么地方被用户代码调用是个不确定的问题,因此很有可能会出现被多个线程调用的问题.其中setState中的state变量本身就是一个std::atomic变量,保证了线程安全.但是对于channel->getFd的关闭操作需要专门放置到此channel所属的线程中.
说了这么多,runInLoop究竟是怎么实现的呢?
void EventLoop::runInLoop(QueuedFunctor func) {
if (func == nullptr) { // 不可以为空
return;
}
if (isOuterThread()) {
// 加入到队列里
{
std::lock_guard<std::mutex> lockGuard(mutex_);
queued_list_.push_back(std::move(func));
}
wakeup(); // 唤醒loop,loop中将会处理被加入到队列中的函数
} else { // 直接运行
func();
}
}其实这个地方仍然有锁开销,只不过临界区要短了许多,只针对任务队列.如果不遵守只运行在特定线程中的规则的话,也可以考虑通过锁来保护这些对象的操作,但是这样的临界区就会长很多,因此开销也就大得多.
总的来说,为了避免多个线程对某些对象操作所导致的线程安全问题,这种技术要求某个对象的操作必须局限于一个线程之中,如果有其他线程调用对该对象的操作,就将其操作转移到这个特定的线程之中去.
2) 通过std::function+std::bind来替代多态
C++中面向对象的继承与多态是使用起来很容出错,容易写出难以维护代码的特性.因此有些大佬建议,继承与多态能不用就不用.
当我们需要一种方法在不同的class中有多种不同的实现时,就想到用多态.然而多态有许多地方导致代码变得难以维护,比如说多态往往伴随着继承体系的建立,当程序不断演进时,有些class需要在继承体系上移动,这麻烦得很.此外,一个派生类很多时候只需要override一个或者一部分虚函数,但是多态的语法中却有要override所有虚函数的要求.
比如说一个Thread的设计,如果是常规的OO设计,会写一个Thread的基类,其中的run函数是需要被override的,还要有具体的实现类,用来将其中的run进行override.这种方式有个麻烦的地方在于,如果我们需要用到多个不同的run行为的Thread,就得定义多个实现类.
如果使用“std::bind+std::function”来替代多态的话,比如说:
class Thread {
public:
using ThreadCallBack = std::function<void()>;
Thread();
~Thread();
void start();
void setThreadCallBack(ThreadCallBack cb) { cb_ = cb; }
private:
void run() { cb_(); }
ThreadCallBack cb_;
};在这种方式下,如果我们想要创建出运行不同过程的Thread,只需要通过setThreadCallBack传递不同的function就好.在网络库中,Channel的相关设计也是如此,其中Channel的数据成员有一下回调:
CallBackFunc read_callback_;
CallBackFunc write_callback_;
CallBackFunc close_callback_;
CallBackFunc error_callback_;3) onMessage回调少用栈上不定长buffer
一个程序的所占用内存大小不应该随着其所处理数据的大小而增长.比如说:
void onConnection(const TcpConnectionPtr &conn) {
if (conn->connected()) {
string fileContent = readFile(g_file);
conn->send(fileContent);
conn->shutdown();
}
}对于这种问题的解决方式:我们可以每次只处理固定大小的内容,一个文件将会分为多次处理完,因此需要一个std::any来保存上下文.在上面的例子中,context可以是FILE*中文件偏移的位置.