结合SimpleDB和BusTub复盘数据库内核实现
大年初一时感觉有些无聊,感觉不如靠学习来打发时间.又想了想之前学过的关于数据库内核的项目几乎快要忘干净了,所以打算从今天开始,一直到开学,除了复习枯燥无味的专业课,再把SimpleDB以及BusTub这两个小数据库的源码啃一遍,希望能对数据库系统的实现有更完整和深入的理解吧.
1.存储引擎
存储引擎是数据库系统中直接对底层文件打交道的模块. 我认为这一模块的设计主要考虑了这几个问题:磁盘上文件中,数据如何排列组织?文件中的数据在内存上如何抽象?数据库系统如何利用内存加速IO的?内存上的内容如何落到磁盘上的?
1).内存模型与类型抽象
这一部分主要解决的是磁盘中结构化的数据如何在内存中进行抽象的问题. 传统数据库系统所维护的数据在底层仍然是以文件的方式存储在disk上,但是数据库系统又有结构化存储的特点,因此文件内部的数据组织往往与数据库结构化存储相适应.比如说对于关系型的数据库来说,文件中的数据以一个个table的方式组织,table内部有分为了一行行的tuple,tuple内部有一个个字段(value),不同的字段又有各自不同的类型.
存储引擎是直接对这些文件进行读写的模块,就避免不了对于文件数据的结构化处理,也就是说要将文件的内容转化为特定的数据结构.正如上面所说的table、tuple、value等等.其中value是最细粒度的单位,tuple次之.
value与type
关于value相关的实现,在BusTub的Value中,其中数据成员如下:
union Val { // 表示具体的值
int8_t boolean_;
int8_t tinyint_;
int16_t smallint_;
int32_t integer_;
int64_t bigint_;
double decimal_;
uint64_t timestamp_;
char *varlen_;
const char *const_varlen_;
} value_;
union {
uint32_t len_;
TypeId elem_type_id_;
} size_;
bool manage_data_;
TypeId type_id_; inline Value Add(const Value &o) const { return Type::GetInstance(type_id_)->Add(*this, o); }
inline Value Subtract(const Value &o) const { return Type::GetInstance(type_id_)->Subtract(*this, o); }
inline Value Multiply(const Value &o) const { return Type::GetInstance(type_id_)->Multiply(*this, o); }
inline Value Divide(const Value &o) const { return Type::GetInstance(type_id_)->Divide(*this, o); }Type及其派生类都有什么,其实没有实际的数据成员(倒是有一个TypeId),但是为特定类型的Value提供了像二元运算、compare等操作Value的方法.并且这些不同的Type具体类都有一个全局的单例对象,看上面Value中的Add、Subtract、Multiply等方法都是先通过Type::GetInstance获取此类型的单例对象,并执行其提供的方法的.这是在Type基类中的数据成员,第二个数组存储了不同类型的单例Type对象.
protected:
// The actual type ID
TypeId type_id_;
// Singleton instances.
static Type *k_types[14];
};此外Value对象是通过一个工厂类创建的,此工厂类除了创建还提供CastAs相关的函数.其中一部分实现:
// 关于Get类函数,是通过Value的构造函数实现的.
static inline Value GetTinyIntValue(int8_t value) { return Value(TypeId::TINYINT, value); }
static inline Value GetSmallIntValue(int16_t value) { return Value(TypeId::SMALLINT, value); }
static inline Value GetIntegerValue(int32_t value) { return Value(TypeId::INTEGER, value); }
......
// CastAs相关
static inline Value CastAsTinyInt(const Value &value);
static inline Value CastAsDecimal(const Value &value)
......tuple
搞清楚tuple的存储视图是最最重要的.尤其是支持VARCHAR类型变量的Tuple的内存布局.在BusTub中,其视图大致如下:
* Tuple format:
* ---------------------------------------------------------------------
* | FIXED-SIZE or VARIED-SIZED OFFSET | PAYLOAD OF VARIED-SIZED FIELD |
* ---------------------------------------------------------------------Tuple::Tuple(std::vector<Value> values, const Schema *schema) : allocated_(true) {
assert(values.size() == schema->GetColumnCount());
// 1. Calculate the size of the tuple.
uint32_t tuple_size = schema->GetLength();
for (auto &i : schema->GetUnlinedColumns()) {
tuple_size += (values[i].GetLength() + sizeof(uint32_t));
}
// 2. Allocate memory.
size_ = tuple_size;
data_ = new char[size_];
std::memset(data_, 0, size_);
// 3. Serialize each attribute based on the input value.
uint32_t column_count = schema->GetColumnCount();
uint32_t offset = schema->GetLength();
for (uint32_t i = 0; i < column_count; i++) { // 这其中对uninline的写入比较困难
const auto &col = schema->GetColumn(i);
if (!col.IsInlined()) {
// Serialize relative offset, where the actual varchar data is stored.
*reinterpret_cast<uint32_t *>(data_ + col.GetOffset()) = offset;
// Serialize varchar value, in place (size+data).
values[i].SerializeTo(data_ + offset);
offset += (values[i].GetLength() + sizeof(uint32_t));
} else {
values[i].SerializeTo(data_ + col.GetOffset());
}
}
}在BusTub中的Tuple的数据成员如下:
bool allocated_{false}; // is allocated?
RID rid_{}; // if pointing to the table heap, the rid is valid
uint32_t size_{0};
char *data_{nullptr};VARCHAR类型的字段为什么要将地址和值的存储相分离?
2).文件分页
了解了Value(字段)、Tuple(关系元组)在内存中的抽象之后,那么Table及其相关的文件又是如何组织的呢?在BusTub中,一个文件往往对应了一个表(一个表可以由多个文件组成),下面结合其中的Page以及TablePage进行剖析.
TablePage
在BusTub中,一个Page对象对应磁盘上的一个block,其大小为4kb,只不过前者是加载于内存上的概念,后者是在磁盘上的概念.因此一个Page对象中,也会有一个buffer(4kb大小)来存储数据,也就是下面的data_,其数据成员如下:
char data_[PAGE_SIZE]{};
page_id_t page_id_ = INVALID_PAGE_ID; // 页号,与某个block号对应
int pin_count_ = 0;
bool is_dirty_ = false;
ReaderWriterLatch rwlatch_;/**
* Slotted page format:
* ---------------------------------------------------------
* | HEADER | ... FREE SPACE ... | ... INSERTED TUPLES ... |
* ---------------------------------------------------------
* ^
* free space pointer
*
* Header format (size in bytes):
* ----------------------------------------------------------------------------
* | PageId (4)| LSN (4)| PrevPageId (4)| NextPageId (4)| FreeSpacePointer(4) |
* ----------------------------------------------------------------------------
* ----------------------------------------------------------------
* | TupleCount (4) | Tuple_1 offset (4) | Tuple_1 size (4) | ... |
* ----------------------------------------------------------------
*
*/HEADER部分表示整个TablePage的元数据.其中TablePage以一种类似于链式的方式维护,所以有PrevPageId和NextPageId作为指针.FreeSpacePointer表示一个文件中的偏移量,该偏移量从文件末尾开始,向低处增长(因为Tuple数据的增长和header中的增长呈现相反的方向),TupleCount表示的是当前所存储的Tuple的数量.后面的空间则存储了每个Tuple的offset和size.HEADER部分向文件高偏移处增长.
INSERTED TUPLES部分用来存储已经插入到此Table的tuples.由于在HEADER中每个Tuple的offset和size可以固定地确定为8 bytes,所以可以在HEADER中明确地划分为一个个slot,每个slot就像数组一样可以通过索引访问.当通过某个index访问某个slot时,就可以获取其中的offset以及size,从而直接在INSERTED TUPLES中定位该Tuple.INSERTED TUPLES部分由高向低增长.
关于Tuple size
该位置的内容当为0时,表示的是该slot下没有插入Tuple.如果该slot有Tuple插入,就将该Tuple的size写入.此外,最高位留出来,用来做delete标记.
明确了TablePage的组织方式之后,简单地说一说Tuple的Insert、Update和Delete:
- Insert:
- 从0开始遍历slot,直到找到一个slot中的Tuple size为empty.
- 根据该Tuple的size向低处移动FreeSpacePointer,并将Tuple中的数据拷贝.
- 设置好该slot下的size和offset.
- Update,需要调整该slot对应的offset、size.并且其对应的数据也要重置,此外还需要将FreeSpacePointer还有高处的Tuple进行移动,并且重置offset.
- Delete.分为了两个阶段,一个是
MarkDelete(只是将Tuple size中的最高位设置为1),另一个是ApplyDelete:清空对应的数据区、HEADER中的Tuple size和Tuple offset;移动FreeSpacePointer指针,并且调整其他Tuple的offset.
这里的Delete行为为什么要分成两段式地处理呢?
其实这里还牵扯到一些与日志及恢复系统相关的东西,暂且先不深究.
TableHeap
一个TableHeap是一个存储在磁盘上的table的抽象.一个表往往由多个Page组成,这些Page以某种数据结构组织着,这里以最简单朴素的list为例,也就是TablePage所采用的方式.简而言之,一个表可以由TablePage所组成的list表示(至于B+树、Hash那些涉及到索引的先不说).
一个TableHeap中的数据成员如下:
BufferPoolManager *buffer_pool_manager_;
LockManager *lock_manager_;
LogManager *log_manager_;
page_id_t first_page_id_{}; // 该TableHeap的起始page所对应的id一个TableHeap中维护了组成一个表的所有TablePage的集合.
其中buffer_pool_manager是因为TableHeap相关的API内部实现中,涉及到对Page的访问,其中获取某个TablePage的操作,往往是通过一个BufferPoolManager(缓存池)完成的.TableHeap提供了对一个table的操作的基本接口,比如说Update、Insert、Delete等等:
bool InsertTuple(const Tuple &tuple, RID *rid, Transaction *txn); // 向该TableHeap插入一个Tuple
bool MarkDelete(const RID &rid, Transaction *txn); // 标记:从该TableHeap移除一个Tuple(通过rid)
bool UpdateTuple(const Tuple &tuple, const RID &rid, Transaction *txn); // 将rid对应的Tuple更新
void ApplyDelete(const RID &rid, Transaction *txn); // 从该TableHeap移除一个Tuple(通过rid)
void RollbackDelete(const RID &rid, Transaction *txn);Latch与Pin
在InsertTuple、MarkDelete、UpdateTuple等方法的实现中,往往需要对某些TablePage进行读写,在获取并操作某个TablePage时往往有如下的模式:
auto page = static_cast<TablePage *>(buffer_pool_manager_->FetchPage(rid.GetPageId())); // 获取某个TablePage,FetchPage中有对该页的Pin操作. page->RLatch(); // 上读锁(或者是page->WLacth为上写锁) ....... // reading operate for this page page->RUnlatch(); // 解开读锁 buffer_pool_manager_->UnpinPage(rid.GetPageId(), false); // Unpin这其中既有BufferPool中需要的Pin操作,也有保证线程安全的锁操作.其中Pin操作是为了防止该TablePage在该TablePage被操作的期间防止被从BufferPool上踢出,Latch实质上是该TablePage中的std::mutex,防止多线程读写该页所带来的data race问题.
3).全局元数据
BusTub有一个全局单例的Catalog对象.该对象维护了整个数据库系统中创建过的表、索引等实例,并且提供了访问这些实例的接口,也就是说,如果在User代码中想要获取或设置某个Table或者Index对象,都需要先通过Catalog中的get或set函数来进行.
Catalog中的数据成员如下:
[[maybe_unused]] BufferPoolManager *bpm_;
[[maybe_unused]] LockManager *lock_manager_;
[[maybe_unused]] LogManager *log_manager_;
std::unordered_map<table_oid_t, std::unique_ptr<TableInfo>> tables_;
std::unordered_map<std::string, table_oid_t> table_names_;
std::atomic<table_oid_t> next_table_oid_{0};
std::unordered_map<index_oid_t, std::unique_ptr<IndexInfo>> indexes_;
std::unordered_map<std::string, std::unordered_map<std::string, index_oid_t>> index_names_;
std::atomic<index_oid_t> next_index_oid_{0};next_table_oid_变量用于给创建的table分配编号.tables_中维护了TableInfo对象,TableInfo的实现如下:
struct TableInfo {
TableInfo(Schema schema, std::string name, std::unique_ptr<TableHeap> &&table, table_oid_t oid)
: schema_{std::move(schema)}, name_{std::move(name)}, table_{std::move(table)}, oid_{oid} {}
Schema schema_;
const std::string name_;
std::unique_ptr<TableHeap> table_;
const table_oid_t oid_;
};总的来说,基于这几个map就可以完成对某个Table或者Index对象的访问、设置或者创建.
全局元数据不仅仅通过Catalog对象的方式维护在内存中,也需要有持久化在磁盘中的方式.BusTub中定义了HeaderPage,也就是说会有一个HeaderPage文件持久化了这些元数据的内容.
4).磁盘I/O
其实在BusTub中,所需要写的文件分为log文件和db文件,后者包含了数据库存储的数据.可以说,整个数据库系统就只有一个db文件,所有的表和索引都存储于其中.只不过通过分页的方式,将该db文件划分为了一个个页(在磁盘中恰好是一个block的大小),page_id也就是某个page在db文件之中的序号(比如说0-4095段对应了page_id为0,4096-8191对应的是page_id为1,以此类推),每个Table或者Index都由一个或者几个Page组成.
其中提供了读写Page相关的方法:WritePage和ReadPage:
void DiskManager::WritePage(page_id_t page_id, const char *page_data) {
std::scoped_lock scoped_db_io_latch(db_io_latch_);
size_t offset = static_cast<size_t>(page_id) * PAGE_SIZE;
num_writes_ += 1;
db_io_.seekp(offset); // 移动文件游标到该Page的起始位置
db_io_.write(page_data, PAGE_SIZE); // 写入缓冲区的数据
if (db_io_.bad()) {
LOG_DEBUG("I/O error while writing");
return;
}
db_io_.flush();
}
void DiskManager::ReadPage(page_id_t page_id, char *page_data) {
std::scoped_lock scoped_db_io_latch(db_io_latch_);
int offset = page_id * PAGE_SIZE;
if (offset > GetFileSize(file_name_)) {
LOG_DEBUG("I/O error reading past end of file");
} else {
db_io_.seekp(offset); // 移动文件游标到该Page的起始位置
db_io_.read(page_data, PAGE_SIZE); // 读取一个Page的大小
if (db_io_.bad()) {
LOG_DEBUG("I/O error while reading");
return;
}
int read_count = db_io_.gcount();
if (read_count < PAGE_SIZE) { // 判断是否读取完整
LOG_DEBUG("Read less than a page");
db_io_.clear();
memset(page_data + read_count, 0, PAGE_SIZE - read_count);
}
}
}由于fstream不是线程安全的,所以还需要额外用一个锁用来保护.
5).缓存池
缓存池可以说是存储引擎中最最核心的设计,数据库系统作为一种IO密集型的系统,如果所有对数据的读写操作都直接以磁盘读写的方式进行,将会带来不可接受的开销.因此缓存池的设计旨在尽可能地将数据读写作用在内存而非磁盘上,在某个时机再将缓存池中的内容刷到磁盘上.
这其中实现和设计的难点在于:置换策略和Pin的处理.更多细节就参考我之前写过的一篇:CMU 15-445:project #1 - Buffer Pool
6).小结
如果暂且不考虑Logger的话,存储引擎的总体架构如下(这个图自己画的,好看不?):
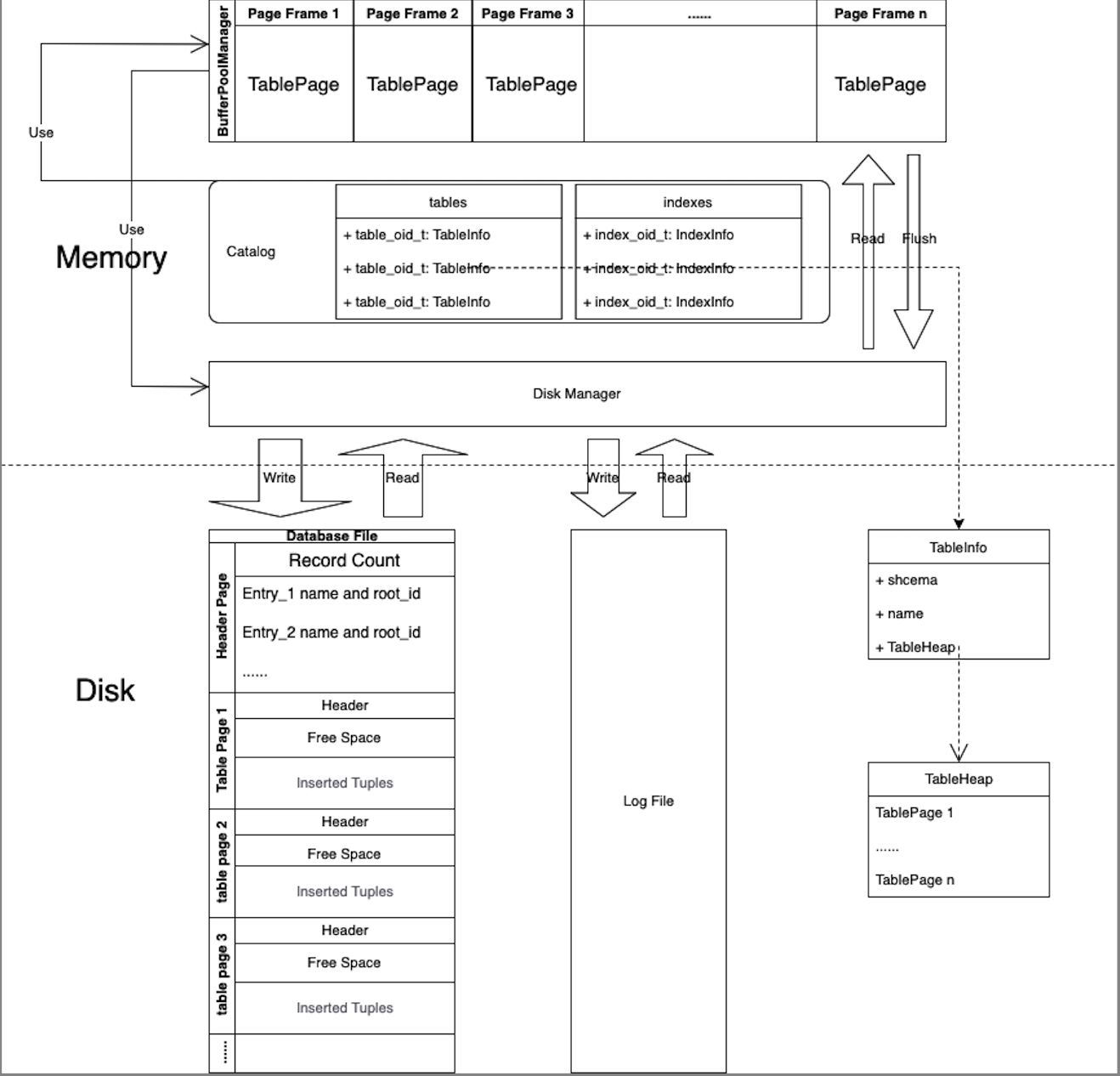
其中暂时不包含索引、日志、Lock等方面的细节.最终总结如下:
- DataBase File.重点在于,如何划分为一个个的Page,以及Page内部数据的组织格式.
- Disk Manager.需要这么一个从disk到内存的读写数据的搬运工,BufferPool中涉及到对Page进行读写的操作都是基于Disk Manager完成的.
- 数据模型.从最最基础的Type和Value,到Tuple,需要考虑的是Tuple如何处理可变长的Value?再到Table,Table是如何抽象的呢?可以说一个Table在BusTub中对应了一个TableHeap,一个TableHeap是一个或者多个Page的集合,这一部分又很多繁琐的代码.
- Catalog.用来在内存中保存全局元数据,比如说Table和Index的相关的信息.使得执行引擎可以通过一些get方法访问到某个特定的Table或者Index.
- Buffer Pool.利用系统的局部性原理,尽可能地将对数据的操作转移到内存中,Disk文件之所以需要分页,很大程度上是为了适应BufferPool存储的要求.其中对内存页的Pin以及置换策略是实现Buffer Pool的关键.
2.索引系统
索引系统常常被看作是存储引擎的一部分.在这里单独拎出来了.
1).内存数据结构
这里只讲解宏观、框架性质的东西,索引及其操作的实现细节,其中关于可拓展hash请见:CMU 15-445:project #2 - Hash Index.
2).索引文件组织
3.查询与执行
在数据库中,数据库将接受的SQL执行经过编译(以及优化)之后可以得到一个呈现树状的Query Plan,该Query将会被执行引擎执行(伴随着对存储引擎的访问),执行器运行结束后会产生结果.其大致的流程图如下:
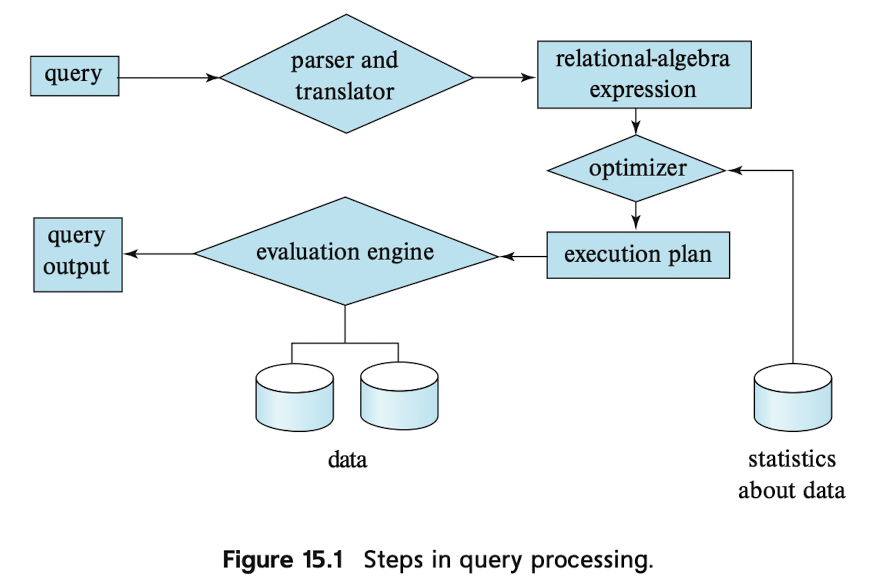
BusTub中只涉及到执行引擎的实现.也就是execution plan、evaluation engine的部分,其中对data的操作是通过调用存储引擎的接口实现的,比如说Buffer
Pool中对于页的读、写等.
1).执行引擎
这一部分结合BusTub中的相关实现进行说明.其实现主要分为这几部分:
- Plan Node的表示以及实现.Plan Node时通过查询或者操作命令所转换成的一种类似于AST的树状结构.根据不同的命令类型,结点有不同的类型,比如说delete、update、insert等.这一部分之所以呈现为树状的结构,不仅仅是为了便于语句的抽象与表示,也是因为SQL操作本身具有层次依赖性,比如说Limit限制数量的是来源于子结点产生的Tuple.
- Executor的实现.既然Plan Node组成的了一棵树,那么我们需要对这个树进行遍历,在遍历每个结点时执行相应的操作,才可以产生最终的结果,在遍历每个Plan Node时,都会有一个Executor去执行相应的操作,正是因为有不同类型的Plan Node,因此也会有不同类型的Executor对应不同的Plan Node.Executor会有对存储引擎的直接访问,从中读、写Tuples.正是因为每个Plan Node都会有相应的Executor处理,因此总体来看,一系列Execution Plan的执行,也会有一个"Executors Tree".
- 执行引擎以及总体结构.在BusTub中,执行引擎接收一个Plan Tree(根),然后创建相应的Executor,然后调用Executor,返回结果.
- Expression的实现.
Execution Engine
这一部分,起到一个“总管家”的身份,执行引擎中承上启下的一环(上:Execution Plan,下:存储引擎).在BusTub中的实现比较简单:
bool Execute(const AbstractPlanNode *plan, std::vector<Tuple> *result_set, Transaction *txn,
ExecutorContext *exec_ctx) {
// Construct and executor for the plan
auto executor = ExecutorFactory::CreateExecutor(exec_ctx, plan);
// Prepare the root executor
executor->Init(); // 使用每个执行器执行Plan Node,首先调用Init,然后在while循环中调用Next
// Execute the query plan
try {
Tuple tuple;
RID rid;
while (executor->Next(&tuple, &rid)) { // 将tuple返回到结果集合中
if (result_set != nullptr) {
result_set->push_back(tuple);
}
}
} catch (Exception &e) {
// TODO(student): handle exceptions
}
return true;
}对外只有一个接口.其中的内容,就是根据plan创建一个exector,将其初始化之后对executor进行遍历(执行),最终得到返回结果.exector看似只是一个单独的对象,但实际上和这个plan来说都是一个树状的结构,结合ExecutorFactory::CreateExecutor以及Executor的相关实现可以验证.如下:
static std::vector<const AbstractExpression *> empty_agg_exprs;
static std::vector<AggregationType> empty_agg_types;
/** The distinct plan node to be executed */
const DistinctPlanNode *plan_;
/** The child executor from which tuples are obtained */
std::unique_ptr<AbstractExecutor> child_executor_;
SimpleAggregationHashTable aht_;
SimpleAggregationHashTable::Iterator aht_iterator_;上面是DistinctExecutor的数据成员,其中有一个child_executor_作为数据成员,也就是“子结点”.很多其他类型的Executor也是这样,也会有一个或者更多child_executor_作为数据成员.因此ExecutorFactory::CreateExecutor,也是以一种递归的方式创建Executor的:
case PlanType::Insert: {
auto insert_plan = dynamic_cast<const InsertPlanNode *>(plan);
auto child_executor =
insert_plan->IsRawInsert() ? nullptr : ExecutorFactory::CreateExecutor(exec_ctx, insert_plan->GetChildPlan());
return std::make_unique<InsertExecutor>(exec_ctx, insert_plan, std::move(child_executor));
}
// Create a new update executor
case PlanType::Update: {
auto update_plan = dynamic_cast<const UpdatePlanNode *>(plan);
auto child_executor = ExecutorFactory::CreateExecutor(exec_ctx, update_plan->GetChildPlan());
return std::make_unique<UpdateExecutor>(exec_ctx, update_plan, std::move(child_executor));
}
// Create a new delete executor
case PlanType::Delete: {
auto delete_plan = dynamic_cast<const DeletePlanNode *>(plan);
// 这个地方可以体现,Child的创建呈现一种递归的方式
auto child_executor = ExecutorFactory::CreateExecutor(exec_ctx, delete_plan->GetChildPlan());
return std::make_unique<DeleteExecutor>(exec_ctx, delete_plan, std::move(child_executor));
}以上是其中部分Executor的创建方式,会递归地调用ExecutorFactory::CreateExecutor创建子执行器.
分析完了Executor的创建,我们需要关心一个Executor对象怎么调用,或者为什么要以这种方式进行调用.
采用火山模型的Executor
这里最大的好处在于,对于不同操作类型的结点,都可以提供一致的接口被调用,也就是BusTub中的Init和Next.具有优秀的可拓展性.其中Init是该Executor的初始化操作,Next是Executor的具体执行操作.
Expression
许多Plan Node需要有Expression进行“修饰”,比如说Aggregate操作中的having、group by等,seq scan中的predicate,因此不同类型的Plan Node也会有不同类型的Expression去修饰.
Execution Plan
Execution Plan的作用可以体现在,“执行器树”正是通过遍历Plan Node
Tree构造出来的,并且在执行器运行时往往需要访问其对应Plan
Node中需要的信息,比如说seq
scan中的predicate表达式等.在BusTub中,也是通过简单的多态实现的,有一个基类AbstractPlanNode,派生类则有AggregationPlanNode、DeletePlanNode、DistinctPlanNode等.
其中关于AbstractPlanNode的定义如下:
class AbstractPlanNode {
public:
/**
* Create a new AbstractPlanNode with the specified output schema and children.
* @param output_schema the schema for the output of this plan node
* @param children the children of this plan node
*/
AbstractPlanNode(const Schema *output_schema, std::vector<const AbstractPlanNode *> &&children)
: output_schema_(output_schema), children_(std::move(children)) {}
/** Virtual destructor. */
virtual ~AbstractPlanNode() = default;
/** @return the schema for the output of this plan node */
const Schema *OutputSchema() const { return output_schema_; } // 返回格式
/** @return the child of this plan node at index child_idx */
const AbstractPlanNode *GetChildAt(uint32_t child_idx) const { return children_[child_idx]; }
/** @return the children of this plan node */
const std::vector<const AbstractPlanNode *> &GetChildren() const { return children_; }
/** @return the type of this plan node */
virtual PlanType GetType() const = 0;
private:
const Schema *output_schema_; // 返回元组的模式
/** The children of this plan node. */
std::vector<const AbstractPlanNode *> children_; // 作为树的子结点
};可见output_schema_、children是基本的元素,前者用于限定该Plan
Node输出结果的模式,后者则是在Plan Node Tree中的子结点.
Executor
在BusTub中,Executor的具体实现是lab3要做的部分,这是我当时所做的笔记:CMU 15-445:project #3 - Query Execution.
上面简要的提了一下Executor树状的特点,以及火山模型的方式.从整个系统的视角上来看,其实这里还会涉及到一些与事务、索引、并发控制相关的部分,这些部分我想在其他模块进行分析.此外,在BusTub中,这一部分采用了简单的多态实现.继承体系只有两层.其中一个基类AbstractExecutor,其余的AggregationExecutor、DeleteExecutor、HashJoinExecutor等为派生类.至于一些具体实现的东西,在上面的博客中也提到很多了,这里我只借一点具体实现的例子来强调一下执行引擎和存储引擎的交互吧.
其实未必所有操作类型都会涉及到对存储引擎的直接读写.只有DeleteExecutor、InsertExecutor、SeqScanExecutor、UpdateExecutor会直接调用存储引擎接口的.这些操作所依赖的数据往往需要从disk(或者buffer)拉取,或者对这些数据需要写入到数据库中.而其他类型的Executor所依赖的数据往往不是数据库中的“实体数据“,是一些从子执行器中生成的,因此也不会直接访问存储引擎.
对于直接访问存储引擎的情况,以DeleteExecutor为例:
bool DeleteExecutor::Next([[maybe_unused]] Tuple *tuple, RID *rid) {
Tuple tmp_tup;
RID tmp_rid;
Transaction *txn = exec_ctx_->GetTransaction();
auto indexes = AbstractExecutor::exec_ctx_->GetCatalog()->GetTableIndexes(info_->name_);
while (child_executor_->Next(&tmp_tup, &tmp_rid)) { // 每次遍历都会删除一个,并且需要将有关的Index项也删除
try {
if (txn->IsSharedLocked(tmp_rid)) {
exec_ctx_->GetLockManager()->LockUpgrade(txn, tmp_tup.GetRid());
} else {
exec_ctx_->GetLockManager()->LockExclusive(txn, tmp_tup.GetRid());
}
txn->AddIntoDeletedPageSet(tmp_tup.GetRid().GetPageId());
info_->table_->MarkDelete(tmp_rid, AbstractExecutor::exec_ctx_->GetTransaction()); // 最初只是调用Mark Delete
for (auto index : indexes) {
IndexWriteRecord index_record(tmp_rid, info_->oid_, WType::DELETE, tmp_tup, index->index_oid_,
exec_ctx_->GetCatalog());
txn->AppendTableWriteRecord(index_record);
index->index_->DeleteEntry( // 对Index上的更新,也就是将其对应的Index项移除
tmp_tup.KeyFromTuple(info_->schema_, index->key_schema_, index->index_->GetKeyAttrs()), tmp_rid,
AbstractExecutor::exec_ctx_->GetTransaction());
}
if (txn->GetIsolationLevel() != IsolationLevel::REPEATABLE_READ) {
exec_ctx_->GetLockManager()->Unlock(txn, tmp_tup.GetRid());
}
} catch (TransactionAbortException &e) {
return false;
}
}
return false;
}其中会对该table调用MarkDelete,该方法来源于存储引擎中Catalog中的TableInfo对象,更往底层深入,则会涉及到Buffer
Pool对Page的操作.像InsertExecutor、UpdateExecutor也是以类似的方式,SeqScanExecutor稍微有点不同,是通过遍历TableIterator实现的,但是其底层也是通过Buffer
Pool对数据库进行读取.
至于一些不需要直接访问存储引擎的Executor,比如说:
bool LimitExecutor::Next(Tuple *tuple, RID *rid) {
if (limit_cnt_ >= plan_->GetLimit()) {
return false;
}
Tuple tmp_tup;
RID tmp_rid;
while (child_executor_->Next(&tmp_tup, &tmp_rid)) {
*tuple = tmp_tup;
*rid = tmp_rid;
limit_cnt_++;
return true;
}
return false;
}但是其子执行器有可能会直接访问存储引擎,或者“子子执行器”中,总之,在一个“执行器树”中,必然会有对存储引擎的访问,只要是涉及到对数据库实体数据访问情况都会需要访问存储引擎,而这些“实体数据“恰恰又是所有数据操作的源.
2).优化器
在BusTub中并没有涉及到优化器的实现,但是在SimpleDB中有相关的模块,这是我当初实现相关Lab时所作的博客:mit 6.830 数据库系统: lab 3.在这里简单地复盘一下.结合上面提到的框架图,优化器的实现不仅仅包含优化器本身,还包括statistics的收集,不过在SimpleDB中涉及Join操作的优化,即连续的Join操作.
其中结合SimpleDB中的测试用例,我们可以得出大概这样的流程:
final int IO_COST = 103; // 表示IO开销的参数
JoinOptimizer j; // 优化器
Map<String, TableStats> stats = new HashMap<>(); // 每个Table都需要用到的Statistics(用于估算代价的统计数据)
List<LogicalJoinNode> result; // 保存优化后的结果,也就是优化后的序列
List<LogicalJoinNode> nodes = new ArrayList<>(); // 表示一个Join序列
Map<String, Double> filterSelectivities = new HashMap<>(); //
TransactionId tid = new TransactionId();
// 创建表所需要的HeapFile文件
List<List<Integer>> smallHeapFileTuples = new ArrayList<>();
HeapFile smallHeapFileA = SystemTestUtil.createRandomHeapFile(2, 100,
Integer.MAX_VALUE, null, smallHeapFileTuples, "c");
HeapFile smallHeapFileB = createDuplicateHeapFile(smallHeapFileTuples,
2, "c");
......
// 创建表,注册到Catalog
Database.getCatalog().addTable(smallHeapFileA, "a");
Database.getCatalog().addTable(smallHeapFileB, "b");
......
// 为每个表创建相应的TableStats
stats.put("a", new TableStats(smallHeapFileA.getId(), IO_COST));
stats.put("b", new TableStats(smallHeapFileB.getId(), IO_COST));
......
// Put in some filter selectivities
filterSelectivities.put("a", 1.0);
filterSelectivities.put("b", 1.0);
......
// 构造Join序列
nodes.add(new LogicalJoinNode("a", "b", "c1", "c1",
Predicate.Op.LESS_THAN));
nodes.add(new LogicalJoinNode("b", "c", "c0", "c0", Predicate.Op.EQUALS));
......
// SQL解析器
Parser p = new Parser(); // 代入SQL语句到Parser,并且
j = new JoinOptimizer(
// 首先是一个通过解析SQL得来的Logical Plan node
p.generateLogicalPlan(
tid,
"SELECT COUNT(a.c0) FROM a, b, c, d,e,f,g,h,i WHERE a.c1 < b.c1 AND b.c0 = c.c0 AND c.c1 = d.c1 AND d.c0 = e.c0 AND e.c1 = f.c1 AND f.c0 = g.c0 AND g.c1 = h.c1 AND h.c0 = i.c0;"),
nodes); // 完整的Join序列
result = j.orderJoins(stats, filterSelectivities, false); // 运行,获取优化的结果
- 在表创建、注册到Catalog上时,会创建相应的TableStatistic对象,也是全局可访问的.
- Parser将SQL语句解析成Plan Node
Tree的时候,结合其中涉及的
TableStats求出这段Join操作序列的最低开销顺序.
Statistics
SimpleDB中有一个TableStats类,一个TableStats对象为当前已经创建过的某个Table维护一些需要被Optimizer用到的信息,SimpleDB中有一个全局的TableStats
Map.一个表的TableStats对象会在表创建时进行初始化,当Table被更新时,其中的内容也会有相应的更新.一个TableStats对象的数据成员如下:
private int tableId_;
private HeapFile tableFile_; // 对应的是一个表
private TupleDesc tableDesc_;
private int ioCostPerPage_; // 访问表中的每个Page所带来的IO开销
private int tupleNum_; // 一个表中的Tuple数量
private HashMap<Integer,Field> maxValues_; // Int的最大值和最小值,每个Field都有一个
private HashMap<Integer,Field> minValues_;
private HashMap<Integer,IntHistogram> intHisMap_; // Int字段的直方图
private HashMap<Integer,StringHistogram> strHisMap_; // string字段的直方图之所以需要将tupleNum_设置为一个数据成员,有利于后面在进行两个表的Join时,快速得到其中的Tuple数,在Hash
Join中,两个表的Tuple数量是其估算开销的关键,ioCostPerPage_则会被用于估算Join开销的公式中.当该Table中有Tuple更新时,其中直方图和极值都需要更新.当Optimizer运行的时候,会访问当前所涉及到的表的TableStats,从而估算出开销.
Optimizer
优化器()工作的核心逻辑如下:
public List<LogicalJoinNode> orderJoins(
Map<String, TableStats> stats,
Map<String, Double> filterSelectivities, boolean explain)
throws ParsingException {
// 这里采用了一种动态规划的方式,根据Join运算的可结合性
int n = joins.size();
PlanCache planCache = new PlanCache();
for (int i = 1; i <= n; i ++) {//从长度为1到长度为n
// 从0开始,size为i的子段
Set<Set<LogicalJoinNode>> subsets = enumerateSubsets(joins,i); // 一个有长度为i的子段所组成的集合
Iterator<Set<LogicalJoinNode>> subsetIt = subsets.iterator(); // 枚举这些长度为i的子段
while (subsetIt.hasNext()){ //内部分别对应一段集合
double optcost = Double.MAX_VALUE;
List<LogicalJoinNode> bestList = null;
int card = 0;
Set<LogicalJoinNode> nodeSet = subsetIt.next(); // 获取当前node一项
Iterator<LogicalJoinNode> setIt = nodeSet.iterator(); // 从该node开始
while (setIt.hasNext()) { // 遍历该子段
LogicalJoinNode node = setIt.next(); // 取出该子段作为分割点
CostCard csa = computeCostAndCardOfSubplan(stats,filterSelectivities,node,nodeSet,optcost,planCache);
if (csa != null) { // 是否需要更新
optcost = csa.cost;
bestList = csa.plan;
card = csa.card;
}
}
planCache.addPlan(nodeSet,optcost,card,bestList); // 这里的Plan Cache
}
}
Set<LogicalJoinNode> allSet = enumerateSubsets(joins,n).iterator().next();
List<LogicalJoinNode> resultList = planCache.getOrder(allSet);
if (explain) {
printJoins(resultList,planCache,stats,filterSelectivities);
}
return resultList;
}对于连续的Join操作,这里采用了动态规划的方式处理.
如果让我在BusTub引入优化器(Join Optimizer)模块,应该怎么做?
首先对于Statistics来说,我会考虑将其放置于每个表的TableInfo中,因此这一部分会在每个表创建时进行初始化.由于BusTub中字段类型要比SimpleDB多,因此就需要设置更多不同类型的直方图类,这里采用简单的多态(即一个抽象类,其他都是具体类),这一部分的实现应当会相当的繁琐.
对于Optimizer部分,我认为难题在于,对于一个完整的Plan Node Tree,应当遍历一遍从中获取一段段Join操作及其根Plan,之后采用类似与SimpleDB中的算法求出“最优序列”,然后根据最优序列在Plan Node Tree中移动相应的结点的位置.
4.事务与并发控制
在BusTub中,这一部分有两个核心的模块,分别是TransactionManager、LockManager.前者用于维护和追踪整个数据库系统中的事务,后者用于处理事务并发访问数据时所发出的锁(行级锁)请求.LockManager中对于锁请求的处理深刻地影响了很多事务的特性,比如说隔离级别、两阶段锁协议等等.此外,这一部分在开发时需要在执行引擎中改动部分代码,可以说事务与并发控制模块和执行引擎本身就存在一定的交互.
总的来说,我认为这一部分有以下几个核心的问题:
- 系统是如何管理一个事务的生命周期的?
- Transaction中如何实现原子性?有关于隔离型的实现呢?
- LockManager以怎样处理锁的方式,实现隔离级别以及两阶段锁协议的?
- 执行引擎与
Transaction、LockManager模块的关系是什么?
这些问题会在下面分析.此外,关于lab中相关模块的实现,之前所做的博客:CMU 15-445:project #4 - Concurrency Control.
1).Transaction、TransactionManager
首先对于“事务”这个概念的封装,结合BusTub中对于Transaction的封装,其中的数据成员如下:
private:
TransactionState state_; // 状态
IsolationLevel isolation_level_;
std::thread::id thread_id_; // 线程id
txn_id_t txn_id_;
std::shared_ptr<std::deque<TableWriteRecord>> table_write_set_; // 该事务所写过的table集合
std::shared_ptr<std::deque<IndexWriteRecord>> index_write_set_; // 该事务所写过的index集合
lsn_t prev_lsn_;
std::shared_ptr<std::deque<Page *>> page_set_; // 所新增的page的集合
std::shared_ptr<std::unordered_set<page_id_t>> deleted_page_set_; // 所移除的page的集合
std::shared_ptr<std::unordered_set<RID>> shared_lock_set_; // 事务当前所持有的shared锁
std::shared_ptr<std::unordered_set<RID>> exclusive_lock_set_; // 事务当前所持有的exclusive锁其中state_可以说用来管理一个事务的生命周期,isolation_level_表示该事务的隔离级别,隔离级别将会影响一个事务生命周期的设置,比如说“可重复读”的事务会呈现“GROWING、SHRINKING、COMMITTED、ABORTED”四种状态的生命周期,而其他隔离级别却不包含SHRINKING.下面的几个set,比如table_write_set_,index_write_set_,deleted_page_set_,page_set_都与事务原子性相关的实现,有关,因为“要么都做,要么一点都不做”,对于abort的事务需要进行回滚,在回滚时就通过记录在这些set中的信息进行.
Transaction所提供的方法很简单,通常就是对这些数据成员的setter或者getter.
关于TransactionManager,该class提供了一些控制Transaction的方法,并且有:
static std::unordered_map<txn_id_t, Transaction *> txn_map;
static std::shared_mutex txn_map_mutex;也就是说,在数据库系统中会有一个全局的map跟踪整个系统中所存在的事务,往往也是外界访问某些事务的接口.至于其中所提供的控制Transaction的方法,核心有:Begin、Commit、Abort,这与对某个事务生命周期的管理相关.
其中Begin,主要是创建并初始化一个Transaction对象,并将其记录在txn_map中.Commit、Abort的实现与事务的原子性有关:
void TransactionManager::Commit(Transaction *txn) { // 设置事务状态
txn->SetState(TransactionState::COMMITTED);
// Perform all deletes before we commit.
auto write_set = txn->GetWriteSet();
while (!write_set->empty()) { // 因为delete操作的特殊性,所以多一步遍历,用来完整地将delete操作做完
auto &item = write_set->back();
auto table = item.table_;
if (item.wtype_ == WType::DELETE) {
// Note that this also releases the lock when holding the page latch.
table->ApplyDelete(item.rid_, txn);
}
write_set->pop_back();
}
write_set->clear();
ReleaseLocks(txn); // 释放所有锁
global_txn_latch_.RUnlock();
}Commit意味着一个事务中的动作全部完成.由于存储引擎中对于Delete的处理是两段式的,因此这里需要根据write_set中的记录对这些Delete操作进行apply.之后将所有锁进行释放.
而Abort的实现相对来说比较复杂,这意味着“全部都不做”,因此需要回滚.
void TransactionManager::Abort(Transaction *txn) { // 相比Commited还会涉及到恢复
txn->SetState(TransactionState::ABORTED);
// Rollback before releasing the lock.
auto table_write_set = txn->GetWriteSet();
while (!table_write_set->empty()) {
auto &item = table_write_set->back();
auto table = item.table_;
if (item.wtype_ == WType::DELETE) {
table->RollbackDelete(item.rid_, txn); // 恢复
} else if (item.wtype_ == WType::INSERT) { // 移除
// Note that this also releases the lock when holding the page latch.
table->ApplyDelete(item.rid_, txn);
} else if (item.wtype_ == WType::UPDATE) { // 换成旧的
table->UpdateTuple(item.tuple_, item.rid_, txn);
}
table_write_set->pop_back();
}
table_write_set->clear();
// Rollback index updates
auto index_write_set = txn->GetIndexWriteSet();
while (!index_write_set->empty()) { // 将Index进行修改
auto &item = index_write_set->back();
auto catalog = item.catalog_;
// Metadata identifying the table that should be deleted from.
TableInfo *table_info = catalog->GetTable(item.table_oid_);
IndexInfo *index_info = catalog->GetIndex(item.index_oid_);
auto new_key = item.tuple_.KeyFromTuple(table_info->schema_, *(index_info->index_->GetKeySchema()),
index_info->index_->GetKeyAttrs());
if (item.wtype_ == WType::DELETE) {
index_info->index_->InsertEntry(new_key, item.rid_, txn); // 做逆操作
} else if (item.wtype_ == WType::INSERT) {
index_info->index_->DeleteEntry(new_key, item.rid_, txn);
} else if (item.wtype_ == WType::UPDATE) {
// Delete the new key and insert the old key
index_info->index_->DeleteEntry(new_key, item.rid_, txn);
auto old_key = item.old_tuple_.KeyFromTuple(table_info->schema_, *(index_info->index_->GetKeySchema()),
index_info->index_->GetKeyAttrs());
index_info->index_->InsertEntry(old_key, item.rid_, txn);
}
index_write_set->pop_back();
}
table_write_set->clear();
index_write_set->clear();
// Release all the locks.
ReleaseLocks(txn); // 将所有锁释放掉
// Release the global transaction latch.
global_txn_latch_.RUnlock();
}这其中的回滚需要涉及到对写过的Table的回滚,以及Index回滚.回滚实质上就是做逆操作,对于某些逆操作需要根据保存的“旧值”进行,比如说UpdateTuple以及Index的Update等.而这些信息都会保存在TableWriteRecord或者IndexWriteRecord中,关于这些”WriteRecord“对象,都会在执行器做相关的操作时生成,并加入到该事务的set中.
至此,关于原子性的实现,可以说:Transaction中会维护有关于Table、Index的WriteRecord,在执行器运行时(Next)中,比如DeleteExecutor、UpdateExecutor等,会在其关联的Transaction中添加相关的WriteRecord.如果该事务正常结束,也就是Commit,只要对发生过的Delete进行apply就好了,这与存储引擎中的二段式Delete处理有关,如果是Abort的话,就遍历这些WriteRecord的集合,做逆操作,逐个回滚.
数据库系统是如何管理一个Transaction的生命周期的?
首先通过
TransactionManager的Begin创建一个事务,随后将该事务相关的执行任务与该事务相关联,大概如下所示:
auto exec_ctx1 = std::make_unique<ExecutorContext>(txn1, GetCatalog(), GetBPM(), GetTxnManager(), GetLockManager()); // 其中有一个指向事件的指针 ...... GetExecutionEngine()->Execute(&insert_plan, nullptr, txn1, exec_ctx1.get());随后代入将相关的plan以及
ExecutorContext对象代入到执行引擎中,该事件中的操作也就开始运行了(当然一个事件可以有多个plan).
最终调用Commit或者Abort.
GetTxnManager()->Abort(txn1)该事件的生命周期也就结束了.
关于生命周期这里只是笼统地说一说了,如果相结合两段锁协议等机制的话,就去看上面我写过的那篇博客就好了.
2).LockManager
事务的隔离性需要借助Lock来实现.由于在执行器中,所涉及的事务对数据库中Tuple的读写操作需要上锁,LockManager就用于处理来自执行器中锁请求,尤其是会根据不同事务隔离级别有不同的处理方式.其实这一部分的细节,我在lab4的那篇博客里说得已经差不多,这里就不再多说了.
关于执行引擎和Transaction以及LockManager的关系?
再执行器的接口中(Execute),需要将其所属的Transaction代入,因为在执行器执行(Next)时,需要通过访问该事务,以获取其隔离级别、锁状态等信息,从而通过调用LockManager来发送不同上锁请求.比如说,下面的这种情况:
if (txn->IsSharedLocked(tmp_rid)) { exec_ctx_->GetLockManager()->LockUpgrade(txn, tmp_rid); } else { exec_ctx_->GetLockManager()->LockExclusive(txn, tmp_rid); }对于上写锁的情况,如果之前就已经占用了读锁,那么需要调用LockManager的LockUpgrade,否则就是LockExclusive.
除此之外,执行器在执行时还需要将WriteRecord加入到该事务相应的集合中.
3).小结
最后,为这一模块的简单的归纳几点:
- Transaction的封装与实现.也就是说,实现一个Transaction类需要包含哪些数据成员?由于原子性的需要,事务需要维持一些Write Record确保根据这些东西可以在Abort时撤销操作,达到“要么什么都不做”的效果.还需要追踪当前所持有的锁,这使得当调用Commit或者Abort时,将该事务的Lock释放掉.除此之外,还有隔离级别、生命状态等等.
- TransactionManager中操作事务的接口.比如Commit、Abort等,其中Abort的实现相对复杂,毕竟有撤销已写操作的需要.
- LockManager中不同的锁的类型,以及上锁、解锁、升级锁的API.这里有Shared和Exclusive两种类型,并且为行级锁(以RID为单位).对于每个RID,维护一个请求队列,并记录该RID的上锁信息、占用事务等,当执行器中有事务发出锁请求时,会加入相应的队列,通过轮询该队列的方式判断是否满足上锁条件,并借助条件变量控制事务的阻塞,达到锁的效果.
- 执行引擎中,与Transaction以及LockManager的关系.简而言之,执行器必须访问其所属的事务(获取隔离级别、锁状态等),也必须通过调用LockManager中提供的锁相关API完成锁操作(因事务隔离级别而处理方式不同).
5.日志及恢复系统
我做的是2021版本的BusTub,其中没有关于这一模块的实现,据说2019版的是有这一部分,所以就找了相关的源码去研究了.这其中大致可以分为三个模块,分别是LogManager、LogRecovery、CheckpointManager:
- 日志系统,其中主要在于日志文件的组织方式,数据库系统中如何、何时输出日志,日志系统的工作模式等问题.
- 检查点,应该如何做出检查点,当打印检查点时数据库系统中其他模块都有什么样的响应.
- 恢复系统,如何扫描log文件,在这个过程中如何undo和redo.
1).其他模块中的相关细节
LSN
lsn即日志序列号,可以视为数据库系统中对于修改操作的逻辑时钟,系统中发生过的每个修改行为都会有一个相应的lsn编号.
日志系统维护了一个全局的lsn编号,每当有一个修改操作发生时,就会自增,因此这也就是该修改操作所对应的lsn编号.在Page中也会有一个lsn域,对应的是该Page最新的修改动作.就像其他字段一样,Page中的lsn域首先也是在内存中修改,随后该Page从BufferPool中踢出时才会flush到数据库文件中.此外日志系统中还会记录当前成功flush到日志文件中的lsn编号.
WAL
数据库系统中一些机制实现的难点在于需要考虑到多个模块的交互,即多个模块彼此配合才可以实现某种特定的机制.比如说这里的WAL机制.如何保证修改记录对应的日志文件先于数据库文件写完呢?
首先我们需要考虑的是什么时候写数据库文件?结合BufferPool机制,当一个内存页被踢出的时候,会将该Page刷盘到数据库文件之中.结合存储引擎以及LogManager我们可以知道,当内存页被修改时同时也会生成一个LogRecord,并且调用LogManager::AppendLogRecord,由于日志系统是异步运行的,所以即使内存页已经被修改将要被踢出并flush的时候,也不能保证此时日志文件已经被flush了,因此需要在一个Page被踢出,尚未flush到数据库文件时,对日志文件进行flush.相关的代码细节如下:
frame_id_t BufferPoolManager::GetVictimFrameId() { // 当一个Page需要从buffer pool中题出来时
frame_id_t frame_id;
if (!free_list_.empty()) {
frame_id = free_list_.front();
free_list_.pop_front();
} else {
if (!replacer_->Victim(&frame_id)) {
return INVALID_PAGE_ID;
}
// flush log to disk when victim a dirty page
if (enable_logging) {
Page &page = pages_[frame_id];
if (page.IsDirty() && page.GetLSN() > log_manager_->GetPersistentLSN()) {
log_manager_->Flush();
}
}
}
return frame_id;
}通过"log_manager_->GetPersistentLSN"可以得知当前日志文件已经flush完的lsn编号,如果该内存页中的lsn编号大于它,说明还有尚未flush完的日志记录.
2).LogManager
这里日志系统的实现比较简陋,比muduo的日志系统要简单得多,但总得来说还是采用了前后端的模式,前端被user code(一般是数据库系统的其他部分,比如说执行引擎)调用构造日志消息,后端接收到这些日志消息,每隔一定阶段就将日志消息刷到日志文件中(往往是前端buffer写满的时候).
再LogManager对象中,重点在于两个buffer:log_buffer,flush_buffer,一个用于接收来自日志前端的日志消息,另一个则是在log_buffer写满之后,将其转移到flush_buffer中,后端日志线程将其flush到日志文件之中.
关于前端,提供了一个LogManager::AppendLogRecord接口,相关的代码如下:
lsn_t LogManager::AppendLogRecord(LogRecord *log_record) {
std::unique_lock<std::mutex> lock(latch_);
// flush log to disk when the log buffer is full
if (log_record->size_ + log_buffer_offset_ > LOG_BUFFER_SIZE) {
// wake up flush thread to write log
need_flush_ = true;
cv_.notify_one(); // 唤醒后台线程,首先flush掉,将flush buffer中的消息消费掉,否则现在buffer就是满的
// block current thread until log buffer is emptied
cv_append_.wait(lock, [&] { return log_record->size_ + log_buffer_offset_ <= LOG_BUFFER_SIZE; });
} // 等待可以被消费掉
// serialize header
// 将header的内容进行序列化
log_record->lsn_ = next_lsn_++; // 内存中会追踪lsn,也就是日志版本号
memcpy(log_buffer_ + log_buffer_offset_, log_record, LogRecord::HEADER_SIZE); // 相当于直接append
int pos = log_buffer_offset_ + LogRecord::HEADER_SIZE; // 并且获取了append之后的header_size
switch (log_record->GetLogRecordType()) {
case LogRecordType::INSERT:
memcpy(log_buffer_ + pos, &log_record->insert_rid_, sizeof(RID));
pos += sizeof(RID);
log_record->insert_tuple_.SerializeTo(log_buffer_ + pos); // 将其中剩余的内容序列化
break;
......
}
log_buffer_offset_ += log_record->size_; // 移动缓冲区中的offset
return log_record->lsn_; // 返回标号
}首先需要检查log_buffer中是否还有足够的空间写入该log_record,如果没有足够的空间,就唤醒正在等待的后台日志线程(会将log_buffer的内容“消费”到flush_buffer中),并且借助条件变量等待log_buffer有足够的空间.之后设置这条日志消息的lsn编号,并且将日志消息的header写入.之后根据日志消息的类型进行特定的写入(写入到log_record).写完之后需要移动log_buffer的偏移量.
至于日志系统中后台线程,及其运行逻辑:
void LogManager::RunFlushThread() { // 运行后台的log thread
if (enable_logging) { // 实现还是比较简陋的
return;
}
enable_logging = true;
flush_thread_ = new std::thread([&] {
while (enable_logging) {
std::unique_lock<std::mutex> lock(latch_);
// flush log to disk if log time out or log buffer is full
cv_.wait_for(lock, log_timeout, [&] { return need_flush_.load(); });
if (log_buffer_offset_ > 0) {
std::swap(log_buffer_, flush_buffer_);
std::swap(log_buffer_offset_, flush_buffer_offset_);
disk_manager_->WriteLog(flush_buffer_, flush_buffer_offset_);
flush_buffer_offset_ = 0;
SetPersistentLSN(next_lsn_ - 1); // flush完之后,就设置persistentLSN
}
need_flush_ = false;
cv_append_.notify_all();
}
});
}后台日志线程中,会使用条件变量等待log_buffer写满,等待被唤醒之后,将log_buffer中内容借助disk_manager将日志消息写入到日志文件.其中维护了变量persistent_lsn_,改变量指的是当前已经成功写入到日志文件之中的lsn编号.
BusTub中日志系统的缺点
这个日志系统相对来说是比较简陋的,主要原因在于User Thread(就是调用LogManager::AppendLogRecord的线程)会因为等待后台线程消费而陷入阻塞.muduo中的日志系统正是为了解决这个问题而设计了双缓冲机制.
LogManager还会为每个日志消息指定日志序列号(lsn).
BusTub中打印日志的时机
- 一个事务开始的时候会有一个BEGIN类型的日志消息.
- 一个事务结束的时候,也就是Commit或者Abort的时候.
- 事务在运行期间.具体地说,是存储引擎中TablePage中的相关接口被调用时.例如
TablePage::ApplyDelete中有:if (enable_logging) { BUSTUB_ASSERT(txn->IsExclusiveLocked(rid), "We must own the exclusive lock!"); LogRecord log_record(txn->GetTransactionId(), txn->GetPrevLSN(), LogRecordType::APPLYDELETE, rid, delete_tuple); lsn_t lsn = log_manager->AppendLogRecord(&log_record); SetLSN(lsn); txn->SetPrevLSN(lsn); }
3).CheckpointManager
void CheckpointManager::BeginCheckpoint() {
transaction_manager_->BlockAllTransactions(); // 阻塞当前的所有事件
log_manager_->Flush(); // 强制性地刷盘
buffer_pool_manager_->FlushAllPages(); // 将buffer pool中的刷到磁盘上
}
void CheckpointManager::EndCheckpoint() {
// Allow transactions to resume, completing the checkpoint.
transaction_manager_->ResumeTransactions(); // 结束掉一个检查点
}在数据库系统中,通常会每隔一定的周期就建立一个检查点,建立检查点的作用在于避免恢复时从头到尾扫描日志文件而带来冗余的恢复操作.BusTub在建立检查点时,调用BeginCheckpoint,会阻塞新的事务建立并运行,之后强制性地将log_manager、buffer_pool中的数据进行flush.当这些flush完毕之后,调用EndCheckpoint,接触新事务的阻塞,数据库系统之后正常运行.
其中体现了数据库系统先写日志文件,再写数据库文件的特点.
4).LogRecovery
LogRecovery将会扫描日志文件,并且通过undo、redo操作来执行日志恢复操作.其提供的相关接口主要也是Undo、Redo.基于LogRecovery的恢复动作很简单:先调用Redo再调用Undo就可以了.
当Redo时,会扫描日志文件中的每条记录,并比对该Page中的lsn和日志记录中的lsn,如果Page中的lsn编号较小,就需要重做,这对应了只写了日志文件,没来得及写数据库文件就宕机的情况.与此同时还会收集“活跃事务”,也就是直到系统崩溃还没有完成的事务,也就是在扫描时,如果没有扫描到该事务的Commit或者Abort记录,就会被判定为“活跃事务”.
当Undo时,将之前收集的活跃事务中的操作撤销.
5).小结
总的来说,我认为这一部分的核心在于对lsn相关操作的理解和把握.