数据库系统概念:Chapter 12:Query Processing and Optimization
Query Processing
1.Overview
Query processig一般包含三个部分:
- 解析,翻译.也就是将数据库操作语言解析并翻译成可以对存储系统进行操作的表达方式.
- 优化.
- 评估性能.
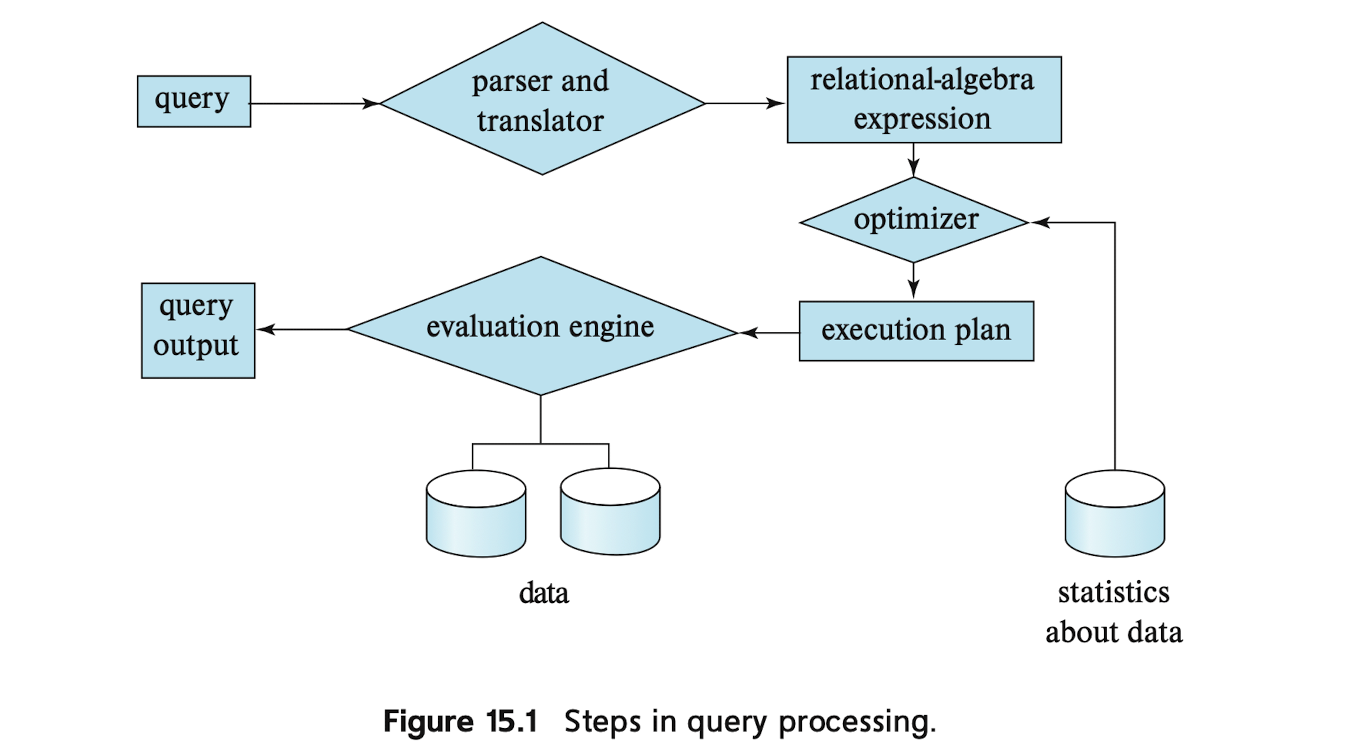
比如说,SQL语言可以经过解析和翻译变成关系代数的形式,然而对于相同的关系代数又可以有不同的方法执行,比如说,如果需要寻找每一个小于75000的数,那么这个时候可以直接遍历instructor中的每一个tuple或者借助B+树的索引来查找.
所以这个时候,一个关系代数需要标识出其处理方式,因此标识了处理方式的关系代数被称为evaluation primitive.由一个查询行为拆解成的一个个evaluation primitive序列称为query-execution plan.
optimizer会根据statistics和关系代数表达式生成execution plan,进而交给evaluation
engine执行并输出查询结果.optimizer会产生一种开销比较小的方案.
2.Measures of Query Cost
在这里讨论optimizer需要对查询开销进行测量的方法.
其中主要考虑:disk的访问次数,CPU占用时间,分布式系统中网络开销等方面.
一般来说在大型数据库中,I/O是主要的开销,但是随着闪存和SSD以及主存大小增大并更充分地利用,I/O的开销大大减小了.CPU开销占比增大,关于CPU的开销,数据库系统常会配置有关的参数,将参数与执行过程中的tuple数量等做乘积因此估算CPU开销.
在此将“传输磁盘的块数”以及“随机访问I/O次数”作为重要指标,一般来说随机读的耗时要多不少.比如说,传输一个block花费0.1ms,而随机读4ms.
此外读写磁盘块开销不同,写大概是读的两倍,因为写完后还需要读取一遍验证写操作的成功,书中的讨论中忽略这个细节,假定两者几乎相等,此外缓冲区的大小也是重要的因素.
由于缓冲区的影响,开始读取数据时总是假定从disk中读出,不考虑已经在buffer中的情况,这也是书中的悲观估计.
这一章剩余的部分,很大程度上是在介绍不同operator的各种算法,不同的算法有不同的开销计算方式适合不同的场景,这一部分日后再深入研究
Query Optimization
1.Overview
同一个sql语句可以转化成多个不同样式的关系表达式,也就可以有多个不同的query-evaluation plan,然而如何从众多不同的plan中挑选出最低开销的呢?不同的plan又该如何进行开销的计算和比较呢?
这些工作都交给optimizer来做,首先它会生成多个不同的等价的query-evalution plan,这个过程可以分为3步:
- 生成逻辑等价的表达式.
- 增加注释,形成
query-evalution. - 计算开销,相互比较,选出其中一个.
2. Transformation of Relational Expressions
等价的关系表达式最终会生成相同的输出,这个不言而喻,但是产生的Tuple的顺序不保证一致.
下面书中则列举了一堆关系代数的等价转换法则,不再枚举.
其中多个等价plan中,很重要的一个地方在于Join Order.良好的顺序使得因为Join而产生的中间输出中,其中包含的Tuple会比较少,这往往有利于减小开销.
3. Estimating Statistics of Expression Results
对于一个operation的计算,需要知道输入及其statistics.比如说
r ⋈ (s ⋈ t),就要先得出 s ⋈ t的statistics.
对应一个生成的表达式或者plan,可以将其组织成一个树,自底向上地进行递归,每经历一个node就可以利用Catalog中的statistics进行计算,最终递归到root也就得出了这个表达式下的cost.
不过需要注意的是,虽然我们确实经过一定的statistics进行估价,但是这并不是完全精确的评估,很多被估出的结果,在真实运行中可能也不是最低开销的.
1) Catalog Information
Catalog用来存储整个Database中全局的表的信息,这些信息很多都会用于table的statistics的计算中,究竟有哪些信息呢: tuple的数量,blocks的数量,每个tuple的size,一个block中的tuple数等等.
除此以外还有一些关于索引的信息也储存在Catalog中.
Catalog中的table是处于动态变化中的,这意味着statistics也需要进行动态地变化吗?一般系统中不会这么做,这样做太频繁,开销太大.这也更体现了查询优化的statistics并不是完全精确的.
为了描述数据的分布状况,数据库中会使用直方图.直方图的横轴一般是一个个value range,纵轴则表示某个range对应的frequency.
对于某些数据库系统的应用中,通常还会有某些数据出现特别频繁的情况,这个时候为了更好地查询结果,还会维护一个list,其中有n个频率最高的value.而直方图中则不会有这list中的几个value.
2.Selection Size Estimation
size estimate的状况与selection predicate.其中几种常见的predicateop都是和直方图的性质息息相关的,自己就能推出来,在mit
6.830 中这一部分也是重点实现,所以就不再多说.
3. Join Size Estimation
在此说明一下,有关于Join Size的计算.
在这里分了几个不同的情况:
- 如果R交S是空,也就是两者没有共同属性,那么就是
N_r * N_s个. - 如果R中为主键,这个结果就不会大于s,如果S是主键而R不是的话,相反.
- 如果R^ S既不是R的码也不是S的码,这种情况最难确定.
4. Choice of Evaluation Plans
表达式并不等于plan,还需要附加上特定的算法才可以算是plan.
在这里主要介绍cost-based optimizer.很多时候,应用场景是where语句中使用Join
predicate.倘若对多个关系Join的操作,全部枚举出来,数量过于庞大.在此设计了一种动态规划的算法,动态规划算法的一个特点在于利用递推避免了过多的枚举,最终推导出来结果.
