mit 6.830 数据库系统:lab 4
我早就听说mit 6.830的后半部分的难度会比前面难很多,但是似乎也没有想象中的难,虽然我的lab4可以暂时通过测试,但是希望后面的lab5中不会暴漏出隐藏的bug.此外这一部分的难点我认为在于Lock Manager的实现,以及Bufferpool的一些lock,evict,commit操作中的细节.但是其中的很多问题都在《概念》中有所涉及,我阅读了相关的章节,感觉因此lab的难度也降低了一些,思路也清楚了一些.
1.实现基础
1) 两段锁协议
简而言之,两段锁就是将一个事务lock和unlock的时机划分为两个阶段,第一个阶段只能上锁,第二个阶段只能解锁,而当第一个阶段转换到第二个阶段的标志性事件又是什么呢?可以认为是获得最后一个锁的时刻,也可以认为是发生第一个解锁的时刻.
两阶段锁可以保证confilict serializability,保证调度的依赖图是无环的.如果不使用两段锁协议可能出现下面图中的问题:
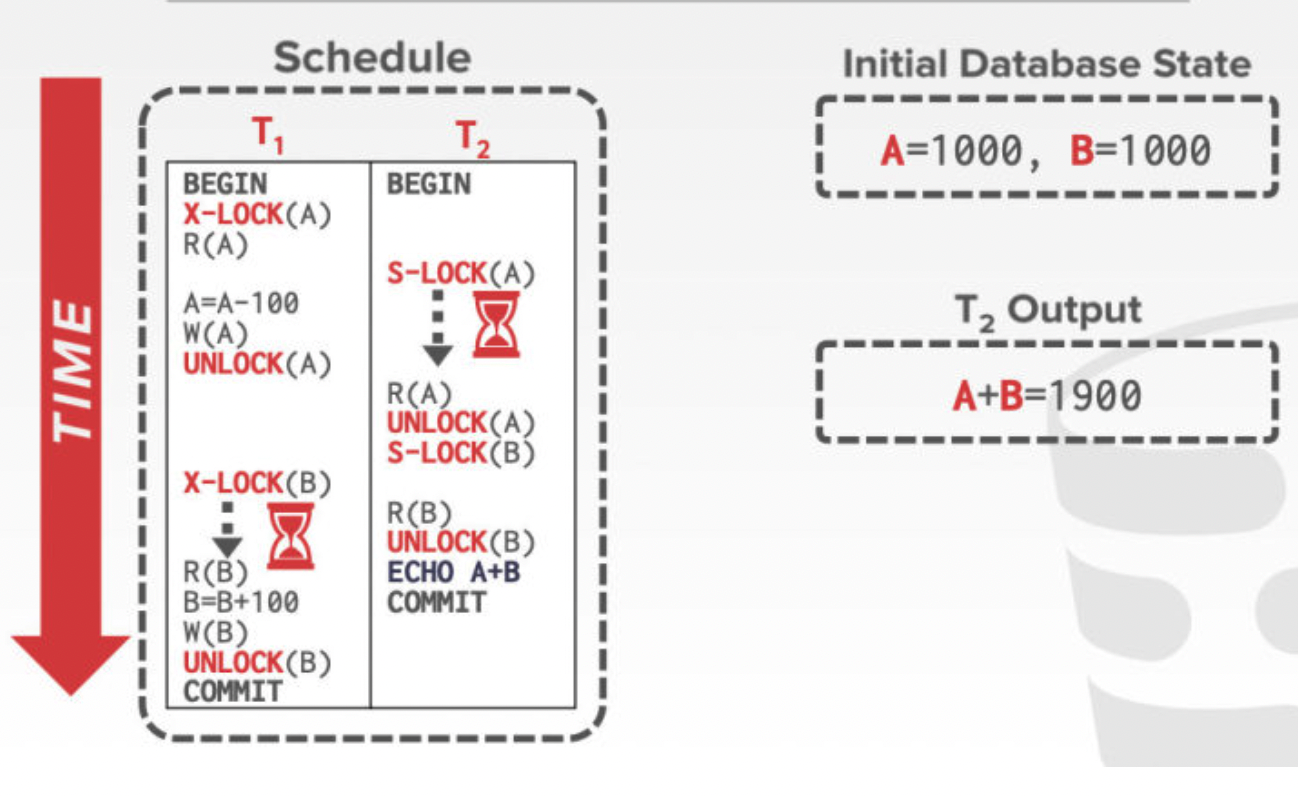
图中,理想的结果应该是A+B = 900 + 1100 = 2000,图中的问题在于在事务1进行写B之前,却被事务B抢到了B的共享锁,这个时候T1对B进行写的操作还没有完成就进行了读.因此这种情况就呈现了异一种T1事务被一分为二,中间穿插了T2的情况,因此总的来说,两段锁协议还是对于事务的原子性进行了控制.倘若使用了两段锁协议的话,将导致T1先执行,T2后执行的效果.
此外两段锁协议还是避免不了级联回滚和死锁的问题.在此不再多说.
下面说一说在test样例中的情况,其实我认为在test中对于事务的操作已经可以保证二段锁协议,因此即使不在Lock Manager中实现两段锁协议,也是可以通过测试.首先说,unlock只会在commit和abort时集中发生,也就是说,一个事务释放锁的动作确实是集中发生的,之后只要可以保证在调用commit中的release all时不发生acquire,就可以证明实现了二段锁协议.
而在测试中确实都是在commit前保证锁已经都获取了,所以commit或者abort的过程中没有穿插着锁的acquire.
2) BufferPool的相关操作
一个由于这里的锁都是Page级别的,在这里需要将Lock,flush,recover,evict相互联系起来.
全局的BufferPool内部持有一个Lock Manager,这个用来执行有关于锁的获取与释放等操作.
其中有关于flush,recover部分,这种操作在simpleDB只保证在commit和abort这两种情况下发生,相比于《数据库系统概念》中提到的在evicit时进行flush是由一些出入的.与之相配合的是,BufferPool不会踢出任何脏页,因此如果一连串的操作都是需要对页进行修改的情况应该怎么处理呢?这个时候岂不就会导致BufferPool中无页可踢了吗.在该lab中的实现只是简单地抛出一个异常.
在这里的BufferPool的的evict的选择,可以是一个正在被事务所读取的Page,因为单纯的读取操作并不会对Page中的数据进行修改,毕竟evict策略主要注意的问题还是踢出的页,是否会导致正在执行的修改操作丢失.
再试想一下,如果一个脏页被驱逐,会怎么样?虽然我们的evict只是将某个Page从池中踢出,但是后来进行的commit的flush动作,还是要基于BufferPool来完成,这样则会真正造成写丢失.
《数据库系统概念》中,所提到的方法,则是无论在read还是write时都进行pin,因为书中提到的buffer和lab中用java实现的不大一样,书中将buffer视为一块块内存,每块内存对应一个block(相当于lab中的page),进行读写的时候则是获取这块内存对应的地址,根据该地址进行读写.所以如果一个正在read的(block)page被驱逐替换成另一个block(page),那么则会影响正在进行的read.write操作更是具有具有破坏性,本来希望写入旧的block,结果反而将新替换到的block给改写了.所以这里主要的问题在于数据一致性问题.而当一个page(block)写完或者读取完的时候,执行unpin操作,此外为了应对多个read的情况,pin和unpin则会以计数的方式进行,当unpin使得该计数减到0时,因而可以被驱逐.
至于驱逐部分,书中主要介绍了在驱逐时进行flush的方式,更具体地说,应该说是在解除pin的脏页进行踢出并且写入disk.
关于上锁的规则,主要有如下几个,这些规则是与getPage的读写权限具有紧密联系的:
- 可以同时有多个事务上共享锁.
- 排他锁同一时刻只能有一个,并且其他共享锁也不能上.
- 如果想要请求排他锁,而此时被多个共享锁或者一个排他锁锁住,也会进入阻塞.
- 如果此时某事务想要上排他锁,但是此时确实该事务的共享锁,则会进行锁升级,升级为排他锁.
在《概念》中,pin和lock是紧接着发生的,unpin和unlock也是.
2.实验过程
Exercise 1,2,5
这一部分主要是LockManager的实现,主要参考了《数据库系统概念》.这个类主要主要包括,四个功能:接收锁请求,处理锁的Acquire,释放锁.其中的数据成员如下:
private ConcurrentMap<Integer,LinkedList<LockRequest>> lockTable_;
private ConcurrentMap<Integer,LockState> lockStates_;lockTable_用来记录manager所接受的请求,其中的每个key对应一个Page的hashcode,lockStates_记录每个数据(Page)的锁状态.其构造函数也就是初始化两个空的map.此外还有两个内部类:LockState,LockRequest,分别表示一个Page的锁状态和锁请求.前者的数据成员为lockType_,tid_,shardCnt_,分别是上锁的类型,持有锁的事务,对于共享锁的计数,这个共享锁计数在锁升级的时候需要用到.而LockRequest_的数据成员除了locktype,tid还有一个seq_,这个用来全局地唯一标识一个请求,也方便了调用者从lockTable_中索引出这个请求.
关于lockState的状态,也就是锁的类型,有三种:
public enum LockType {
SHARED_TYPE,EXCLUSIVE_TYPE,NULL_TYPE
}其中锁的容斥规则如下:
- 当前为NULL_TYPE,上SHARED_TYPE和EXCLUSIVE_TYPE都可以.
- 当前为EXCLUSIVE,既不可以上EXCLUSIVE也不可以上SHARED_TYPE.
- 当前为SHARED_TYPE,可以上其他的SHARED_TYPE,如果当前只有一个共享锁,并且请求的排他锁也是来自事务的,那么就会触发锁升级.
在LockManager中,AddRequest用来用来追加外部锁的请求,其实现如下:
public synchronized long AddRequest(PageId pageId, TransactionId tid, Permissions perm) { //只可有一个线程访问,达到互斥访问的效果
int hashcode = pageId.hashCode();
LockType lockType = perm2LockType(perm);
if (!lockTable_.containsKey(hashcode)) {
lockTable_.put(hashcode,new LinkedList<LockRequest>());
lockStates_.put(hashcode,new LockState());
}
Random random = new Random();
long seqno = random.nextLong();
lockTable_.get(hashcode).add(new LockRequest(lockType,tid,seqno));
return seqno;
}主要就是生成新的LockRequest加入到对应的list中.对于AcquireLock这个函数,首先需要将该锁和当前状态进行比对,通过LockState中的方法canAcquire.其中关于canAcquire的内部实现,就如同前面所说明的加锁规则一样.
public synchronized boolean AcquireLock(PageId pageId,TransactionId tid,Permissions perm,long seqno) {
int hashcode = pageId.hashCode();
LockType lockType = perm2LockType(perm);
LockState state = lockStates_.get(hashcode);
boolean canAcquire = state.canAcquire(lockType,tid);
if (!canAcquire) {
return false;
} else { //其中包含了null,也就是没有锁占用的情况
boolean isfound = false;
Iterator<LockRequest> requestIt = lockTable_.get(hashcode).iterator();
while (requestIt.hasNext()) {
LockRequest request = requestIt.next();
long seq = request.getSeqno();
if (seq == seqno) {
//request.setWaiting_(false); //取消等待
isfound = true;
break;
}
}
return isfound;
}
}当判断好之后,遍历该Page对应的list,根据是否返找到返回true或者false.其实这一部分的实现有一些冗余.关于释放锁的实现,要容易得多,首先定位到该pageHash的list,找到该tid对应的之后就进行移除,如果影响当前的锁状态,则还需要对锁的状态进行更新.
public synchronized void ReleaseLock(int pageHash,TransactionId tid) {
int hashcode = pageHash;
LockType currType = lockStates_.get(hashcode).getLockType();
TransactionId currTid = lockStates_.get(hashcode).getTid();
if (lockTable_.containsKey(hashcode)) {
Iterator<LockRequest> requestIterator = lockTable_.get(hashcode).iterator();
while (requestIterator.hasNext()) {
LockRequest request = requestIterator.next();
if (request.getTid().equals(tid)) {
if (currType.equals(LockType.EXCLUSIVE_TYPE) && tid.equals(currTid)) {
lockStates_.get(hashcode).setTid(null);
lockStates_.get(hashcode).setLockType(LockType.NULL_TYPE);
} else if (currType.equals(LockType.SHARED_TYPE)) {
int shardCnt = lockStates_.get(hashcode).shardCnt_;
if (shardCnt == 1) {
lockStates_.get(hashcode).setTid(null);
lockStates_.get(hashcode).setLockType(LockType.NULL_TYPE);
} else {
lockStates_.get(hashcode).setShardCnt(shardCnt - 1);
}
}
requestIterator.remove();//移除这一项
}
}
}
}比较需要注意的是关于锁状态的更新,如果正是该事务所持有的互斥锁,直接当前锁状态更新为NULL,当前事务也是null,对于共享锁的判断则有点麻烦,如果当前锁的数量为1,就设置为null,否则将共享锁的计数-1.
说明玩LockManger的类之后,下面来看一下在BufferPool中如何调用.首先是在BufferPool中加入一个LockManager对象.
private LockManager lockManager_;在getPage中加入,在从pages_中获取该Page中,加入请求锁和获取锁的过程.
long requestSeq = lockManager_.AddRequest(pid,tid,perm);
long start = System.currentTimeMillis();
while (!lockManager_.AcquireLock(pid,tid,perm,requestSeq)){
long now = System.currentTimeMillis();
if (now - start > TIMEOUT) {
throw new TransactionAbortedException();
}
}在这里的实现比较简单,只是采用简单的轮询的,每一个while循环就不断地AcquireLock,直到获取加锁的许可为止,并且在每一轮循环中都会通过获取时间,来判断当前的时间有没有超时,如果超时则判断为死锁.然后抛出异常.到这里只是实现了最最简陋的死锁判断.
关于练习1中所需要的unsafeReleasePage和holdsLock则是直接调用LockManager中的相关接口即可.
下面来看一下在练习2中所提到的一些特殊情况,首先是在新追加一个Page后,需要对这个新的Page立刻上锁,如果不上锁的话,容易造成data race:
HeapPageId heapPageId = new HeapPageId(heapId_,i);
HeapPage newPgae = new HeapPage(heapPageId,HeapPage.createEmptyPageData());
newPgae.insertTuple(t);
writePage(newPgae);
newPgae = (HeapPage) Database.getBufferPool().getPage(tid,heapPageId,Permissions.READ_ONLY);
result = newPgae;上面这段代码出现在HeapFile在insert时,需要追加新的page的情况,这个时候在在最终返回该page前,调用getPage确保该事务已经加上了新Page的锁.
此外在insertTuple,对于一个page,如果没有可写的空间,那么可以考虑立刻将这个page上的这个锁去掉,这是一种违背两阶段锁的情况,但是由于确实在持有该锁期间,也没有对该Page作出任何的更新,所以在此直接释放掉也没有什么关系,这算是唯一违背两段锁协议的地方.
HeapPageId pageId = new HeapPageId(heapId_,i);
HeapPage page = (HeapPage) Database.getBufferPool().getPage(tid,pageId,Permissions.READ_ONLY);
if (page.getNumEmptySlots() > 0) {
page = (HeapPage) Database.getBufferPool().getPage(tid,pageId,Permissions.READ_WRITE);
page.insertTuple(t);
result = page;
break;
} else {
Database.getBufferPool().unsafeReleasePage(tid,pageId);//将这个锁释放掉
}在上面实现中,起初我们只需要读取其中的空闲数,所以这个时候只是READ_ONLY,如果判断可写,然后再调用getPage并且权限为READ_WRITE,将权限升级为READ_WRITE.
Exercise 3
这一步主要是对置换策略的改变:
private synchronized void evictPage() throws DbException {
Iterator<Integer> fifoIterator = fifoQueue_.iterator();
while (fifoIterator.hasNext()) {
int hash = fifoIterator.next();
HeapPage page = (HeapPage) pages_.get(hash);
if (page.isDirty() == null) {
fifoIterator.remove();
pages_.remove(hash);
return;
}
}
throw new DbException("no undirty page to evict");
}主要是为了防止将脏页踢出的的情况,如果将脏页踢出的话,如果该页正在被某个事务进行写操作,但是写操作还没有完成,这个时候如果就将该page踢出,并flush文件中的话,会造成当前事务正在进行的写有所丢失.若没有找到Dirty页,就抛出异常.
关于Dirty相关的接口.在之前的lab中就进行了实现.不再多说.
Exercise 4
这里主要是对于Commit或者Abort的处理.其中
public void transactionComplete(TransactionId tid, boolean commit) {
// some code goes here
// not necessary for lab1|lab2
if (commit) {
try {
flushPages(tid);
} catch (IOException ioe) {
ioe.printStackTrace();
}
} else {
try {
RecoverPages(tid);
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
lockManager_.ReleaseAllLocks(tid);
}主要就是在释放锁之前,究竟是要flushPages还是RecoverPages.如果是flushPages就直接写到disk中,否则就是RecoverPages,其实现相对来说比较复杂.
private synchronized void RecoverPages(TransactionId tid) throws IOException {
Iterator<Page> pageIt = pages_.values().iterator();
while (pageIt.hasNext()) {
Page page = pageIt.next();
if (tid.equals(page.isDirty())) { //只要等于tid就写回
DbFile file = Database.getCatalog().getDatabaseFile(page.getId().getTableId());
try {
int hashcode = page.getId().hashCode();
HeapPage hpage = (HeapPage) page.getBeforeImage();
file.writePage(hpage);
pages_.put(hashcode,hpage);
} catch (IOException e) {
System.out.println("The flush page error in flushForTid");
e.printStackTrace();
}
}
}
}只是相对来说借助的是HeapPage的getBeforeImage方法,这个方法获取的是数据修改前的旧数据,将旧数据Page写入该文件即可.至于更多细节,以及何时将该Page的旧数据进行设置.比如说在Page.insertTuple中需要对某一页真正进行写操作时,会调用setBeforeImage保存旧数据.当然,这只是一种临时性的做法,所以不能完整地作出事务级别的回滚,因此与其说这里回滚到该事务执行之前的状态,还不如说只是回滚到上次修改的状态.真正的abort回滚还得靠日志,也就是会在lab6中进行实现.
4.小结
都说lab4是比较难的,但是也并没有我想像的那么难,因为这一部分主要在于实现一个Lock Manager,而对于Lock Manager的实现在不少数据库的书籍中都有讲解,我在这里的实现主要是参考了《数据库系统概念》和《数据库系统实现》这两本书,虽然最终也可以稳定地通过test,但是我认为我的Lock Manager的实现,还是存在一定的问题的,比如说释放锁时,关于对于当前状态是共享锁的情况,此外,我认为我没有真正实现两段锁协议.关于请求的处理以及获取锁的许可,也存在冗余.
除了Lock Manager之外,剩余的主要是一些比较琐碎的部分,对于置换策略的调整,我认为无脑地驱逐脏页不如《数据库系统概念》中所提到的pin和unpin的方法,因为脏页只能说明写过,不能说明正在写.
关于abort的恢复,这里只是使用了一种临时的方法,真正的方法还是得看后面的lab6.总的来说,这一部分先告一段落,开始冲lab5.